[論文レビュー] UltraFeedback: Boosting Language Models with Scaled AI Feedback
UltraFeedbackは、オープンソースLLMのRLHFを改善する大規模で細粒度な好みと批評データセットを作成し、新たな報酬モデルと批評モデルを可能にし、RLHFとbest-of-n戦略を通じた性能向上を示します。
Learning from human feedback has become a pivot technique in aligning large language models (LLMs) with human preferences. However, acquiring vast and premium human feedback is bottlenecked by time, labor, and human capability, resulting in small sizes or limited topics of current datasets. This further hinders feedback learning as well as alignment research within the open-source community. To address this issue, we explore how to go beyond human feedback and collect high-quality extit{AI feedback} automatically for a scalable alternative. Specifically, we identify extbf{scale and diversity} as the key factors for feedback data to take effect. Accordingly, we first broaden instructions and responses in both amount and breadth to encompass a wider range of user-assistant interactions. Then, we meticulously apply a series of techniques to mitigate annotation biases for more reliable AI feedback. We finally present extsc{UltraFeedback}, a large-scale, high-quality, and diversified AI feedback dataset, which contains over 1 million GPT-4 feedback for 250k user-assistant conversations from various aspects. Built upon extsc{UltraFeedback}, we align a LLaMA-based model by best-of-$n$ sampling and reinforcement learning, demonstrating its exceptional performance on chat benchmarks. Our work validates the effectiveness of scaled AI feedback data in constructing strong open-source chat language models, serving as a solid foundation for future feedback learning research. Our data and models are available at https://github.com/thunlp/UltraFeedback.
研究の動機と目的
- RLHFのためのオープンソースの好みデータ不足に対処する。
- テキストフィードバックを伴う、大規模で多様かつ精緻に注釈された好みデータセットを構築する。
- UltraFeedbackを用いて、オープンソース報酬モデル (UltraRM) と批評モデル (UltraCM) を訓練する。
- best-of-nサンプリングとPPOベースのRLHFを通じてオープンソースLLMの改善を実証する。
- 今後のRLHF研究のための再現可能なデータ構築とモデル訓練パイプラインを提供する。
提案手法
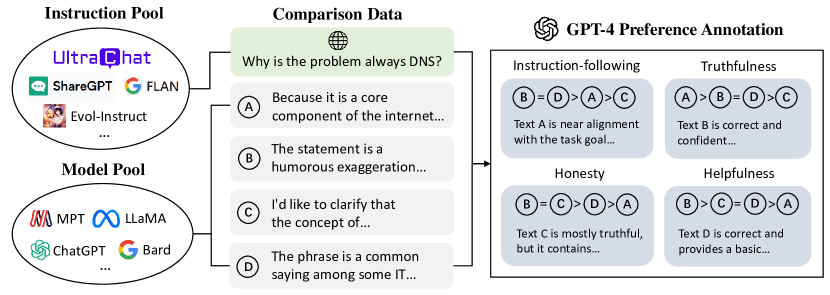
- 複数のソースから多様な指示とモデルの出力をサンプルして、比較データを作成する。
- 各完了に対して、スカラーな好みと詳細なテキスト批評の両方をGPT-4を用いて生成する。
- 対を跨ぐ好みを選択するために、2値ランキング損失を用いてUltraRMを訓練する。
- UltraRMを報酬モデルとして用い、best-of-nサンプリングとPPOでUltraLMをファインチューニングする。
- 自動的な批評生成を可能にするため、UltraFeedbackのテキスト批評でUltraCMを訓練する。
実験結果
リサーチクエスチョン
- RQ1UltraFeedbackは、オープンソースモデルへ一般化する高品質かつ細粒度の好みデータを生成できるか?
- RQ2UltraFeedbackで訓練された報酬モデルは、標準ベンチマーク全体で既存のオープンソースベースラインを上回るか?
- RQ3PPO経由のUltraRMを用いたRLHFは、他のアプローチよりオープンソースのチャットモデルを改善するか?
- RQ4付随する批評モデルUltraCMは、タスク全般で有用で高品質なフィードバックを提供できるか?
主な発見
- UltraFeedbackで訓練されたUltraRMバリアントは、複数のベンチマークで複数のオープンソース報酬モデルを上回る。
- UltraRM報酬を用いたbest-of-nサンプリングは、追加の訓練なしで応答品質を大幅に向上させる。
- UltraFeedbackを用いたUltraLM-13BのPPOファインチューニングは、公開ベンチマークで有意な性能向上をもたらす。
- UltraCMは、多くのタスクでいくつかのクローズドまたは大規模な競合相手の品質に近い、詳細で高品質なテキスト批評を提供する。
- このデータセットは、オープンソースRLHF研究の再現可能な報酬モデリングと批評モデリングのワークフローをサポートする。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。