[論文レビュー] Uncertainty Quantification and Deep Ensembles
この論文は、深層アンサンブルが mixup および較正と低データ設定でどのように相互作用するかを分析し、アンサンブルが較正を悪化させる可能性があることを示し、低データ環境で較正を大幅に改善する Pool-Then-Calibrate アプローチと温度スケーリングを提案します。
Deep Learning methods are known to suffer from calibration issues: they typically produce over-confident estimates. These problems are exacerbated in the low data regime. Although the calibration of probabilistic models is well studied, calibrating extremely over-parametrized models in the low-data regime presents unique challenges. We show that deep-ensembles do not necessarily lead to improved calibration properties. In fact, we show that standard ensembling methods, when used in conjunction with modern techniques such as mixup regularization, can lead to less calibrated models. This text examines the interplay between three of the most simple and commonly used approaches to leverage deep learning when data is scarce: data-augmentation, ensembling, and post-processing calibration methods. Although standard ensembling techniques certainly help boost accuracy, we demonstrate that the calibration of deep ensembles relies on subtle trade-offs. We also find that calibration methods such as temperature scaling need to be slightly tweaked when used with deep-ensembles and, crucially, need to be executed after the averaging process. Our simulations indicate that this simple strategy can halve the Expected Calibration Error (ECE) on a range of benchmark classification problems compared to standard deep-ensembles in the low data regime.
研究の動機と目的
- 過剰パラメータ化された深層モデルを限られたデータで訓練した際の不確実性較正の問題を動機づけて定量化する。
- データ拡張(mixup)とアンサンブル平均化が較正に与える影響を調べる。
- 後処理による較正手法の評価と、較正性能における集約順序の影響を評価する。
提案手法
- データ不足と mixup 増強下での深層アンサンブルの較正特性を分析する。
- 線形プーリング、中央値/トリムドプーリング、および温度スケーリングを後処理として比較する。
- Pool-Then-Calibrate: モデルを訓練し、集約後に検証データ上で単一の温度パラメータを適合させる。
- 複数のデータセットとアーキテクチャに渡って、異なるプーリングおよび較正順序(A-D)を評価する。
- 正解率を最適化するために適切なスコアリング規則(例:cross-entropy)を用いて較正パラメータを最適化する。
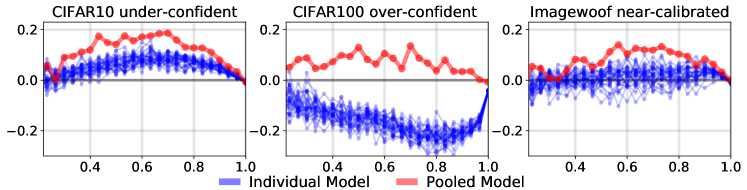
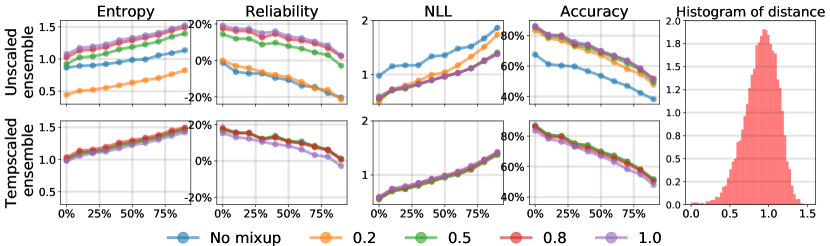
実験結果
リサーチクエスチョン
- RQ1深層アンサンブルは、特に mixup 増強を伴う低データ regime で較正にどのような影響を与えるか。
- RQ2後処理による較正(温度スケーリング)は、アンサンブル平均化と相互作用して較正を改善するか、悪化させるか。
- RQ3どのプーリング/較正順序(pool-then-calibrate 側 vs calibrate-then-pool 側)が、データセット全体で最も良い較正性能を示すか。
- RQ4単純な Pool-Then-Calibrate 戦略は、精度および NLL/Brier の利得を保ちつつ、ECE を大幅に低減できるか。
主な発見
- アンサンブリングによる予測はしばしば信頼度を低下させることがあり、個々のモデルが過信している場合には較正に寄与することがあるが、それ自体で較正を改善するわけではない。
- Mixup 増強はネットワークを過少信頼にさせる傾向があり、そのようなネットワークのアンサンブリングは適切に較正されないと較正を悪化させる可能性がある。
- 温度スケーリングはアンサンブル予測の合算(プーリング)後に適用すべきで、アンサンブル平均化による過少信頼を緩和する。
- Pool-Then-Calibrate(集約を先に行い、単一の温度で較正する)は、低データ設定でいくつかのベンチマークタスクにおいてECEを半減させることができる。
- 個々のモデルをプールする前に較正することは、先にプールしてから較正するより効果が低い(順序と相互作用効果のため)。
- 複数のデータセットを通じて、平均/中央値/トリムドプーリングのようなプーリング戦略は異なる利得を示し、通常は pool-then-calibrate が naive average より優れている。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。