[論文レビュー] Understand Legal Documents with Contextualized Large Language Models
要約: 本論文は直説的役割分類の連続性に対する Legal-BERT-HSLN と、法的固有表現認識のための Legal-LUKE を提案し、ベースラインを上回り、 rhetoric roles リーダーボードで上位5位を達成します。
The growth of pending legal cases in populous countries, such as India, has become a major issue. Developing effective techniques to process and understand legal documents is extremely useful in resolving this problem. In this paper, we present our systems for SemEval-2023 Task 6: understanding legal texts (Modi et al., 2023). Specifically, we first develop the Legal-BERT-HSLN model that considers the comprehensive context information in both intra- and inter-sentence levels to predict rhetorical roles (subtask A) and then train a Legal-LUKE model, which is legal-contextualized and entity-aware, to recognize legal entities (subtask B). Our evaluations demonstrate that our designed models are more accurate than baselines, e.g., with an up to 15.0% better F1 score in subtask B. We achieved notable performance in the task leaderboard, e.g., 0.834 micro F1 score, and ranked No.5 out of 27 teams in subtask A.
研究の動機と目的
- 法的テキストにおける内文・外文コンテキストをより適切に扱うため、推論的役割予測を連続的な文分類として formalize する。
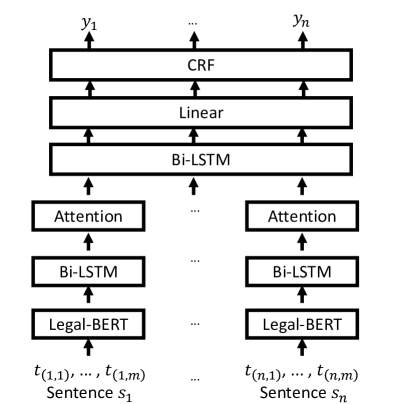
- 文レベルの役割ラベリングのための文脈認識階層モデル(Legal-BERT-HSLN)を開発する。
- 法的固有表現認識のためのエンティティを意識した文脈感知モデル(Legal-LUKE)を設計する。
- F1 スコアとリーダーボードの位置づけの改善を示すため、強力なベースラインと比較評価を行う。)
提案手法
- Legal-BERT-HSLN を階層構造で採用:Legal-BERT からのトークン埋め込み、Bi-LSTM の文脈化、注意機構によるプーリング、シーケンスラベリングのための CRF デコーダ。
- 長距離依存を捉えるための対文脈情報を用いた文表現の強化。
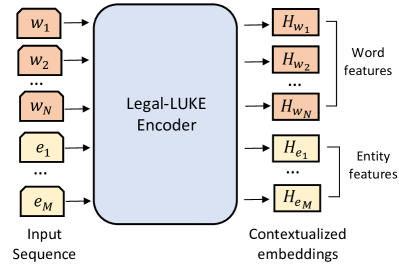
- Legal-LUKE を LUKE アーキテクチャに基づき、トークン、タイプ、位置埋め込みを用いて法的文脈化語とエンティティ表現を学習。
- Legal-LUKE では、単語列とエンティティ列の両方を統合して、NER のための語とエンティティの結合表現を生成。
- 制約付きリソース設定の下で、ベースラインとして BERT-CRF、BERT-Span、XLM-RoBERTa-CRF、mLUKE との比較。)
実験結果
リサーチクエスチョン
- RQ1法的文書における内文・外文コンテキストを捕捉するために、文脈化言語モデルは推論的役割分類の精度をどれだけ高められるか?
- RQ2エンティティを意識した文脈豊かなモデルは、標準エンコーダより法的NER性能を改善できるか?
- RQ3提案モデルは SemEval-2023 Task 6 のベンチマークにおいて強力なベースラインと比較してどうか?
- RQ4長くノイズの多い文書に対して文脈化された法的モデルを適用する際の実務的制約とハイパーパラメータの感度は?
主な発見
| Model | Micro F1 Score | Best Epoch |
|---|---|---|
| BERT-Base | 0.631 | 5 |
| BERT-Mean | 0.641 | 4 |
| BERT-Regularization | 0.597 | 4 |
| BERT-Augmentation | 0.645 | 4 |
| Legal-BERT-HSLN | 0.828 | 16 |
- Legal-BERT-HSLN は検証データで micro F1 が 0.828、テストで 0.8343 を達成し、rhetorical role分類で 27 チーム中 No.5 の順位。
- Legal-LUKE は法的NERでベースラインを上回り、検証データで micro F1 が最大 0.796(列挙されたベースラインの中で最高)を達成。
- Legal-LUKE は NER の BERT-CRF ベースラインに対して micro F1 を最大 14.3% 向上させる。
- XLM-RoBERTa-CRF ベースラインと mLUKE も NER で高成績を示し、XLM-RoBERTa-CRF は 0.773、mLUKE は 0.787。
- 推論役割分類の正則化前処理は性能を低下させる傾向があり、停止語と文マーカーへの感度を示唆。
- Legal-LUKE のテストセット結果は検証より低く(0.667)、セット間の分布シフトを示唆。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。