[論文レビュー] Understanding Black-box Predictions via Influence Functions
この論文は影響関数を再利用して、モデルの予測を訓練データへ遡らせ、特定の予測に最も責任を負う訓練点を特定するスケーラブルな方法を提供し、理解、デバッグ、データクリーニング、敵対的トレーニングへの応用を実証します。
How can we explain the predictions of a black-box model? In this paper, we use influence functions -- a classic technique from robust statistics -- to trace a model's prediction through the learning algorithm and back to its training data, thereby identifying training points most responsible for a given prediction. To scale up influence functions to modern machine learning settings, we develop a simple, efficient implementation that requires only oracle access to gradients and Hessian-vector products. We show that even on non-convex and non-differentiable models where the theory breaks down, approximations to influence functions can still provide valuable information. On linear models and convolutional neural networks, we demonstrate that influence functions are useful for multiple purposes: understanding model behavior, debugging models, detecting dataset errors, and even creating visually-indistinguishable training-set attacks.
研究の動機と目的
- 予測精度を超えたブラックボックスモデルの説明可能性を動機づける。
- 影響関数を用いて予測を訓練データに帰属付けする方法を提案する。
- 非凸性や非微分可能性にもかかわらず、現代のモデルにおける影響の実用的な計算を可能にする。
- モデル理解、デバッグ、データ品質、敵対的トレーニングなど、多様な応用を示す。
提案手法
- 訓練例を重み付け増加または摂動することが、ヘッセ行列の逆行列と損失の勾配の積を通じてモデルパラメータに与える影響を定式化する。
- テスト損失への影響と訓練入力またはラベルの摂動に対する影響の閉形式表現を導出する。
- 効率的なヘッセ行列ベクトル積と共役勾配法または確率的推定を用いて、ヘッセ行列の明示的な逆行列化なしに H^{-1} 勾配を計算する。
- 減衰および平滑化技術を用いて非凸・非微分可能な設定に対処し、leave-one-out 再訓練と精度を比較して妥当性を検証する。
- 自動微分フレームワークを通じて影響を計算する実用的なレシピを提供する。
実験結果
リサーチクエスチョン
- RQ1深層ネットワークにおいて、影響関数は特定の予測に最も責任を負う訓練点を正確に特定できるか?
- RQ2現代のモデルに対して、影響関数をスケールさせて効率的に計算するにはどうすればよいか?
- RQ3凸性・微分可能性の仮定が成り立たない場合でも、影響関数は有用性を保つか?
- RQ4影響関数はデバッグ、データ品質チェック、敵対的トレーニングデータのために使用できるか?
- RQ5影響測度を用いて異なるモデルを比較した場合、モデル挙動についてどんな洞察が得られるか?
主な発見
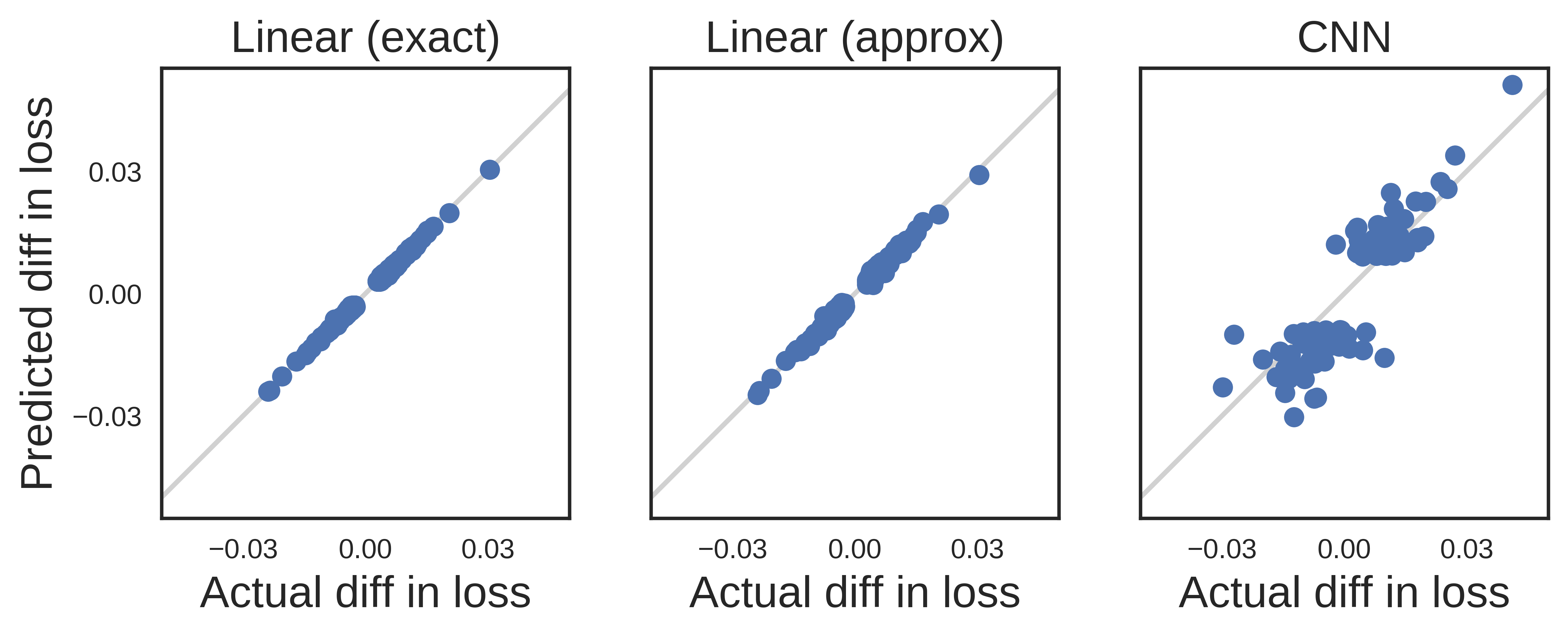
- 影響関数はロジスティック回帰およびMNIST等のタスクにおけるCNNで、予測の leave-one-out 再訓練の変化を密接に近似する。
- ヘッセ-ベクトル積で影響を効率的に計算すると、追加の少数サンプル推定子とともに O(np) で訓練点を影響度でランク付けできる。確率的法と共役勾配法が実用的な高速化を提供する。
- 影響は、モデルが訓練データへの依存と入力空間の単なる近接性との違いを区別するのに役立ち、予測を説明する際に最近傍の直感を上回る。
- 非微分可能な損失関数(例:ヒンジ)を平滑化することで正確な影響推定が得られ、非凸性は減衰で緩和できる。
- 影響関数に導かれた訓練データの摂動は、テスト予測を反転させる視覚的に区別不能な敵対的トレーニング例を作成でき、セキュリティ上の考慮事項を浮き彫りにする。
- 影響関数は領域ミスマッチの原因や誤ラベルデータを特定するのに成功し、デバッグとデータクリーニングを支援する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。