[論文レビュー] Understanding Emergent In-Context Learning from a Kernel Regression Perspective
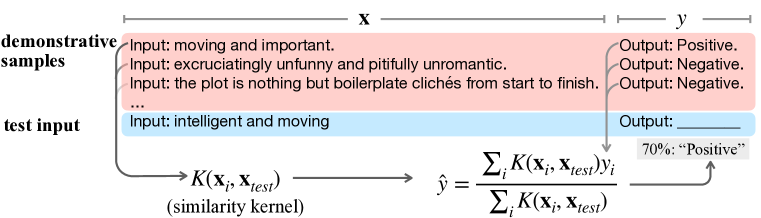
要約: トランスフォーマーにおける文脈内学習はデモンストレーション上のカーネル回帰として現れ、注意機構とサンプルラベルのカーネル様加重との理論・経験的分析で裏付けられる。
Large language models (LLMs) have initiated a paradigm shift in transfer learning. In contrast to the classic pretraining-then-finetuning procedure, in order to use LLMs for downstream prediction tasks, one only needs to provide a few demonstrations, known as in-context examples, without adding more or updating existing model parameters. This in-context learning (ICL) capability of LLMs is intriguing, and it is not yet fully understood how pretrained LLMs acquire such capabilities. In this paper, we investigate the reason why a transformer-based language model can accomplish in-context learning after pre-training on a general language corpus by proposing a kernel-regression perspective of understanding LLMs' ICL bahaviors when faced with in-context examples. More concretely, we first prove that Bayesian inference on in-context prompts can be asymptotically understood as kernel regression $\hat y = \sum_i y_i K(x, x_i)/\sum_i K(x, x_i)$ as the number of in-context demonstrations grows. Then, we empirically investigate the in-context behaviors of language models. We find that during ICL, the attention and hidden features in LLMs match the behaviors of a kernel regression. Finally, our theory provides insights into multiple phenomena observed in the ICL field: why retrieving demonstrative samples similar to test samples can help, why ICL performance is sensitive to the output formats, and why ICL accuracy benefits from selecting in-distribution and representative samples. Code and resources are publicly available at https://github.com/Glaciohound/Explain-ICL-As-Kernel-Regression.
研究の動機と目的
- LLMが大規模一般コーパスの事前学習後に文脈内学習を示す理由を動機づけ、理解する。
- ICLの理論的説明としてカーネル回帰の視点を提案する。
- Transformersの注意機構とカーネル回帰計算の関連を明らかにする。
- LLMの注意と中間特徴におけるカーネル回帰様の挙動を経験的に検証する。
提案手法
- 文脈内学習を事後確率推論として定式化し、前学習ダイナミクスから定義されるカーネル(K(x, x'))でカーネル回帰へと収束する。
- 事例数が増えるにつれて、文脈内のプロンプトに対するベイズ後方がカーネル回帰予測子へ近づくという定理を導く。
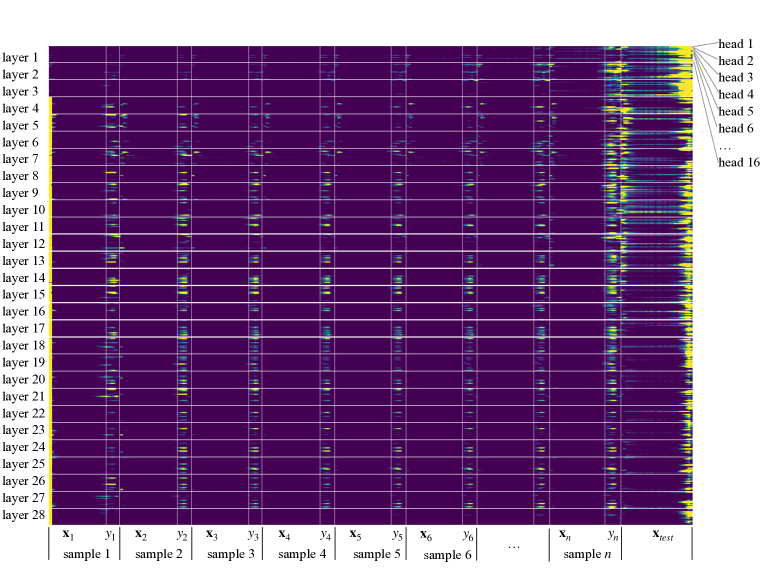
- GPT-J-6Bを経験的に分析し、注意分布を検査し、注意からICL予測を再構築し、カーネル回帰信号のための中間特徴を探る。
- カーネル回帰ベースの再構成とタスク特有ヘッドおよび文エンコーダーベースラインを比較する。
- 複数の層において、注意重み・サンプルラベル・予測出力の整合を示す。
実験結果
リサーチクエスチョン
- RQ1デモンストレーション数が増加するにつれて、文脈内プロンプトに対するベイズ推論はカーネル回帰へ収束するのか。
- RQ2ICL中のLLMの注意パターンは、文脈内サンプルのカーネル回帰様重み付けを反映しているのか。
- RQ3カーネル回帰情報を符号化する特徴はモデルのどこに格納され、予測にどう寄与するのか。
- RQ4カーネル回帰ベースの再構成は実際のICL予測に匹敵しうるのか、デモンストレーションは性能にどう影響するのか。
- RQ5同様のサンプルの検索やラベル形式への感度といったICLの現象を説明する要因は何か。
主な発見
- 理論的結果:文脈内プロンプトに対するベイズ推論は、デモンストレーション数が増えるにつれてカーネル回帰形へ収束する。
- ICL中の注意分布はサンプルラベルに集中し、予測を高精度で再構成できる(いくつかのヘッドで最大89.2%まで)。
- 中間層のいくつかのヘッド(層18–21付近)はカーネル回帰様の挙動を示し、カーネル加重付きラベル情報から出力を予測できる。
- 類似性カーネルは注意ベースの重み付けと整合し、意味表現とカーネル類似性を結びつける。
- ヘッド特徴を用いた再構成されたカーネル回帰予測は、いくつかのタスク(sst2、mnliなど)においてICLおよびカーネル手法と同等の精度を達成する。
- テスト入力に類似するデモンストレーションを retrieved することは、カーネル帯域幅を効果的に狭め、バイアスを低減してICLを改善する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。