[論文レビュー] Understanding Gaussian Attention Bias of Vision Transformers Using Effective Receptive Fields
この論文は Vision Transformer が効果的受容野を通じて空間理解をどのように獲得するかを分析し、位置埋め込みが順序認識に寄与することを示し、Gaussian attention bias を提案して ViT の性能をタスクとデータセット横断で改善することを示しています。
Vision transformers (ViTs) that model an image as a sequence of partitioned patches have shown notable performance in diverse vision tasks. Because partitioning patches eliminates the image structure, to reflect the order of patches, ViTs utilize an explicit component called positional embedding. However, we claim that the use of positional embedding does not simply guarantee the order-awareness of ViT. To support this claim, we analyze the actual behavior of ViTs using an effective receptive field. We demonstrate that during training, ViT acquires an understanding of patch order from the positional embedding that is trained to be a specific pattern. Based on this observation, we propose explicitly adding a Gaussian attention bias that guides the positional embedding to have the corresponding pattern from the beginning of training. We evaluated the influence of Gaussian attention bias on the performance of ViTs in several image classification, object detection, and semantic segmentation experiments. The results showed that proposed method not only facilitates ViTs to understand images but also boosts their performance on various datasets, including ImageNet, COCO 2017, and ADE20K.
研究の動機と目的
- ViTs が ERF を通じて空間構造をどのように理解するかを調査する。
- 訓練済みの位置埋め込みが事前定義された位置手がかりよりも順序認識を生み出すことを示す。
- 訓練開始時から空間理解を実装するために Gaussian attention bias を提案する。
- Gaussian attention bias が画像分類、検出、分割タスクで複数データセットにわたり ViT の性能を改善することを実証する。
提案手法
- 多数の画像にわたる勾配を平均化して ERF を計算・分析し、パッチの寄与を明らかにする。
- 絶対位置埋め込み (APE) と相対位置埋め込み (RPE) が ERF の形成に果たす役割とそれらを再初期化した場合の活動への影響を検証する。
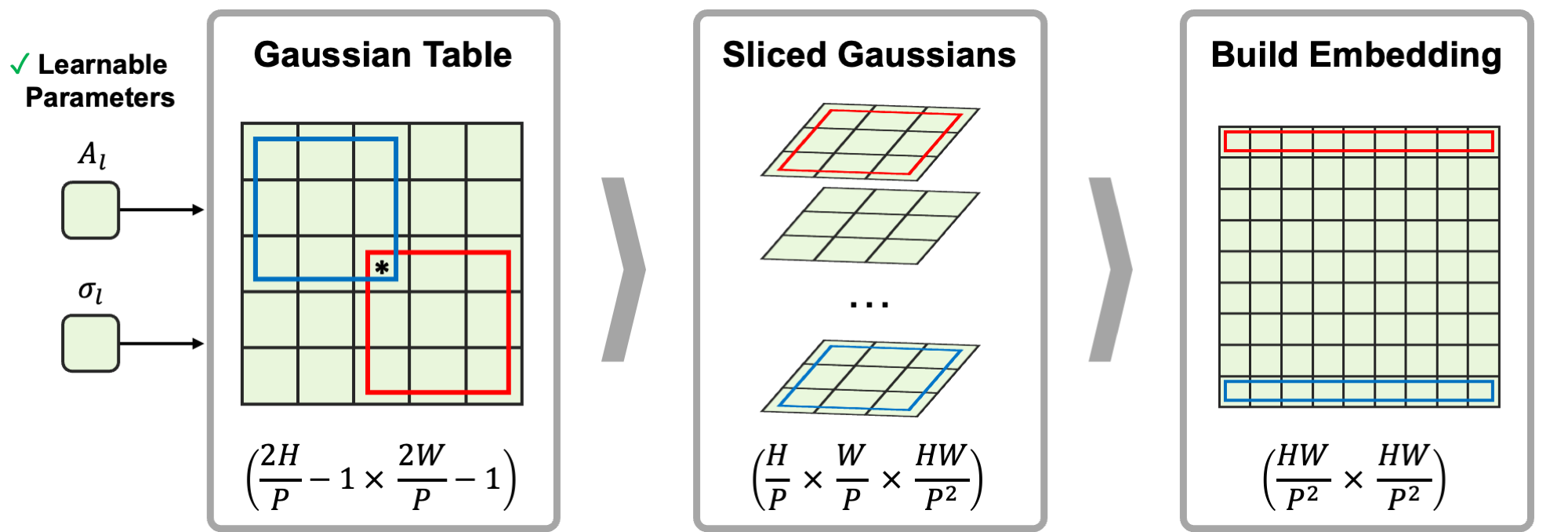
- 注意スコアに B_rel,l と B_Gaussian,l を加えるようにした softmax(QK^T/√D + B_rel,l + B_Gaussian,l) のような Gaussian attention bias を提案する。
- A_l と σ_l でパラメータ化された切片化された 2D ガウスを積み重ねて B_Gaussian,l を構築し、振幅を非負に保ち、ヘッド間で層ごとに共有する。
- B_Gaussian,l を微分可能にし、需要に応じて A_l および σ_l を学習することを検討する一方で、既存の RPE(RelPosBias または RelPosMlp)と互換性を維持する。
- ImageNet-1K などのデータセットで ViT の派生モデルを評価し、Gaussian attention bias による top-1 精度の向上を測定する。
実験結果
リサーチクエスチョン
- RQ1ViT の順序認識は主に訓練済みの位置埋め込みから生まれるのか、それとも固有の SA 構造から来るのか?
- RQ2相対位置エンコーディングに Gaussian attention bias を注入して初期化時から空間理解を誘導し、下流タスクを改善できるのか?
主な発見
- ViTs の ERF はターゲットパッチに集中し、隣接パッチの一部を利用するだけで、空間理解が訓練中に生まれることを示唆している。
- 未学習の RPE は距離に対して感度の低い ERF を生み出す;学習済み RPE は 2D ガウス様のパターンに収束し、近接と遠方パッチを識別しやすくなる。
- Gaussian attention bias を追加すると ImageNet-1K、Oxford-IIIT Pet、Caltech-101、Stanford Cars、Stanford Dogs で ViT の性能が向上し、例として ImageNet-1K で S/16 に +0.157、B/16 に +0.362 の獲得が報告される。
- Gaussian バイアスは物体検出やセマンティックセグメンテーションタスクでも控えめな改善をもたらす(例:RelPosBias を用いた Swin-S で AP_box +0.11、AP_mask +0.10、mIoU +0.25、aAcc +0.27)。
- 学習された σ_l はデータセット間で適応的に変化し、ERF のサイズを柔軟に調整可能である;最後の2層はガウスパターンを学習しない可能性があり、層ごとの挙動にばらつきがあることを示唆する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。