[論文レビュー] Understanding LLMs: A Comprehensive Overview from Training to Inference
この論文はLLMの訓練と推論の進化を概観し、データ前処理、アーキテクチャ、プロンプト学習、コスト効率的な解決策へ向けた展開を含む。
The introduction of ChatGPT has led to a significant increase in the utilization of Large Language Models (LLMs) for addressing downstream tasks. There's an increasing focus on cost-efficient training and deployment within this context. Low-cost training and deployment of LLMs represent the future development trend. This paper reviews the evolution of large language model training techniques and inference deployment technologies aligned with this emerging trend. The discussion on training includes various aspects, including data preprocessing, training architecture, pre-training tasks, parallel training, and relevant content related to model fine-tuning. On the inference side, the paper covers topics such as model compression, parallel computation, memory scheduling, and structural optimization. It also explores LLMs' utilization and provides insights into their future development.
研究の動機と目的
- 統計的なアーキテクチャからトランスフォーマー由来のアーキテクチャへの大規模言語モデルの進化とLLMsの出現を説明する。
- 数十億パラメータへとスケールさせることを可能にする訓練データ源、前処理、およびスケーリングを支えるアーキテクチャの選択を要約する。
- 全体的な再訓練の効率的な代替手段として、プロンプト学習、ファインチューニング、アライメント手法を議論する。
- コスト削減とスケーラビリティ向上を目的とした推論、デプロイメント、最適化手法をレビューする。
提案手法
- 歴史的および現代のLLM訓練技術、データソース、前処理手法をレビューし、総合する。
- トランスフォーマー由来のアーキテクチャ(エンコーダ-デコーダおよびデコーダーのみ)と、それらがLLMのスケーリングに果たす役割を説明する。
- テンプレート、ヴァーバライザー、学習戦略を含むプロンプト学習パラダイムを説明する。
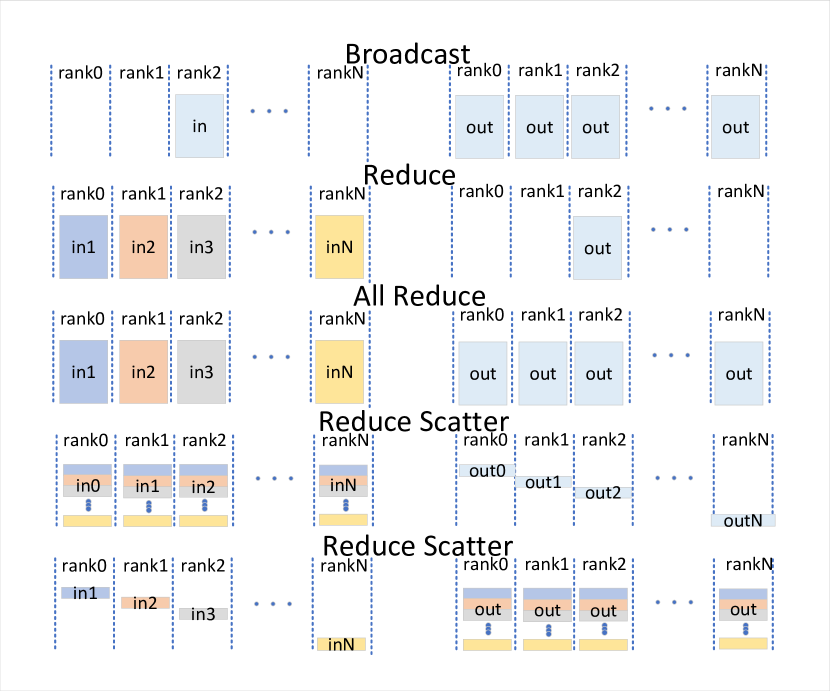
- モデル圧縮、メモリスケジューリング、構造的最適化など、推論とデプロイメントの手法を調査する。

実験結果
リサーチクエスチョン
- RQ1大規模言語モデルを訓練する際の主要なデータソースと前処理手順は何ですか?
- RQ2トランスフォーマー由来のアーキテクチャはLLMsを支えるのか、主要な訓練パラダイム(事前訓練、ファインチューニング、プロンプト学習)とそれらのトレードオフは何か?
- RQ3全体的な再訓練なしでタスク性能を向上させる、プロンプト学習技術とテンプレートは何か?
- RQ4大規模におけるLLMsのコスト効率的な利用を可能にする推論とデプロイメント戦略は何か?
- RQ5LLMの訓練とデプロイメントの将来の方向性と未解決の課題は何か?
主な発見
- LLMsはエンコーダ-デコーダまたはデコーダーオンリーの構成を持つトランスフォーマーアーキテクチャに基づいている。
- プロンプト学習はテンプレートとヴァーバライザーを使用することで、完全なファインチューニングの効率的な代替手段を提供する。
- データ前処理には、フィルタリング、重複排除、プライバシーのクリーニング、毒性/バイアスの緩和が含まれ、安全性と品質を向上させる。
- 推論とデプロイメントは、コスト削減のためのモデル圧縮、並列計算、メモリスケジューリング、構造的最適化に焦点を当てる。
- 本論文は、LLMsの低コストな訓練とデプロイメントに向けた将来の発展動向を論じている。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。