[論文レビュー] Uni3D: Exploring Unified 3D Representation at Scale
Uni3D は、3D 点群と画像-テキスト CLIP の特徴を整合させる10億パラメータの統一型3D基盤モデルを提示し、6M から 1B へ拡張して、最先端のゼロショット、少数ショット、およびオープンワールドの3D理解を達成する。
Scaling up representations for images or text has been extensively investigated in the past few years and has led to revolutions in learning vision and language. However, scalable representation for 3D objects and scenes is relatively unexplored. In this work, we present Uni3D, a 3D foundation model to explore the unified 3D representation at scale. Uni3D uses a 2D initialized ViT end-to-end pretrained to align the 3D point cloud features with the image-text aligned features. Via the simple architecture and pretext task, Uni3D can leverage abundant 2D pretrained models as initialization and image-text aligned models as the target, unlocking the great potential of 2D models and scaling-up strategies to the 3D world. We efficiently scale up Uni3D to one billion parameters, and set new records on a broad range of 3D tasks, such as zero-shot classification, few-shot classification, open-world understanding and part segmentation. We show that the strong Uni3D representation also enables applications such as 3D painting and retrieval in the wild. We believe that Uni3D provides a new direction for exploring both scaling up and efficiency of the representation in 3D domain.
研究の動機と目的
- 2D/ NLP基盤モデルに倣うスケーラブルで統一的な3D表現学習の動機付け。
- 2Dの豊富な事前学習を活用して3Dバックボーンを初期化し、10億パラメータ規模へ拡大。
- マルチモーダル対比学習を通じて、3D点群特徴と画像-テキスト整列特徴を揃える。
- ゼロショット、少数ショット、オープンワールドの強力な性能を3Dタスク全般で示す。
- 実世界の3Dペインティングや取得などの下流アプリケーションを探る。
提案手法
- 統一されたバニラ・トランスフォーマー(ViT風)を3Dバックボーンとして用いる。
- ViTのパッチ埋め込みを、点をパッチにグループ化しTiny PointNetで3Dトークンを生成する点トークナイザに置換する。
- 事前学習をエンドツーエンドで行い、事前学習済みCLIPモデルからの画像-テキスト特徴と3D点群特徴を整合させる。
- Uni3Dを2D事前学習モデル(例:EVA、DINO)またはクロスモーダルモデル(CLIP)で初期化し、画像/テキストエンコーダを固定したまま3Dエンコーダを微調整する。
- 3D・画像・テキスト間のマルチモーダル対比損失(トリプレット対比目的)を用い、柔軟なCLIP教師(OpenAI CLIP、EVA-CLIP など)を許容する。
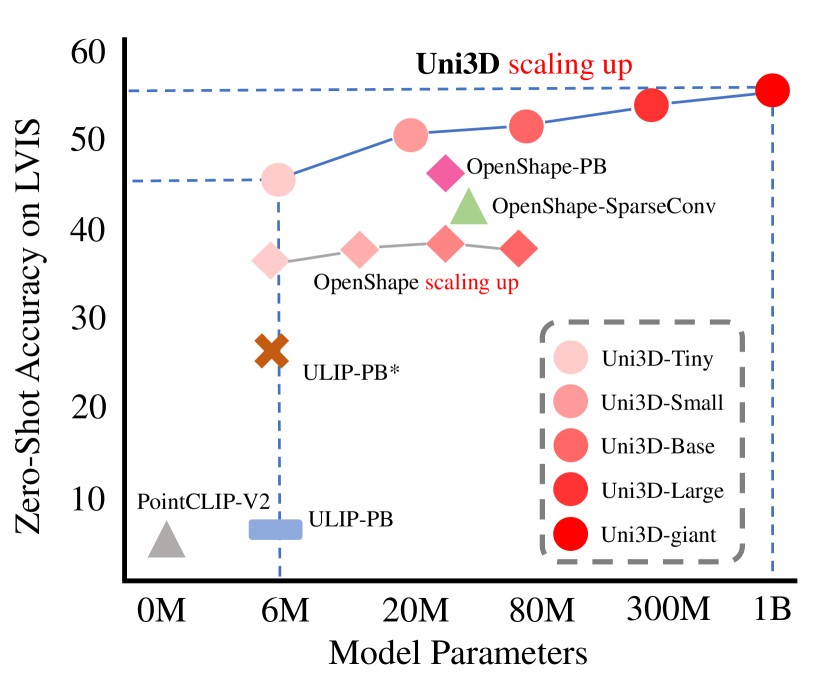
- 統一的な2D/NLPスケーリング法則に従い、6M から1Bパラメータへスケールする;約100万の3D形状、1000万の画像、7000万のテキストで訓練する。
実験結果
リサーチクエスチョン
- RQ110億規模で学習された統一型3D表現が、ゼロショット・少数ショット・オープンワールド・セグメンテーションなどの多様な3Dタスクへ効果的に転移できるか。
- RQ22D事前学習からの初期化と画像-テキスト表現への整合が、大規模データを用いたスケーラブルな3D学習を可能にするか。
- RQ3CLIP式の教師とスケーリング戦略は、3D基盤モデルをどの程度改善できるか。
- RQ410億パラメータの3Dモデルから生じる下流能力(例:取得、塗装、オープン語彙セグメンテーション)は何か。
主な発見
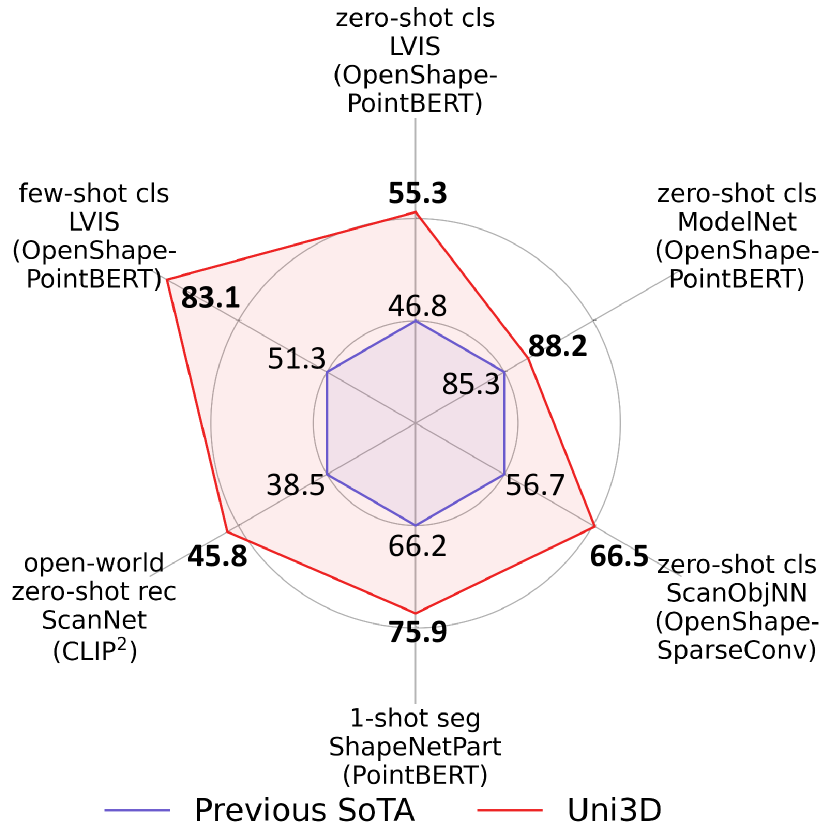
- Uni3D は複数の3Dベンチマークで最先端のゼロショットおよび少数ショット性能を達成し、従来手法を上回る。
- 10億パラメータの Uni3D がマルチモーダル整合で訓練されると、オープンワールド理解と部位セグメンテーションへと良好に転移する。
- ModelNetでのゼロショット分類はトップ5で 88.2% に達しており、クロスモーダル一般化の強さを示す(論文内の報告)。
- Uni3D は点群の塗装や野外でのクロスモーダル3D形状取得などの実用的アプリケーションを可能にする。
- フレームワークは柔軟性を維持:CLIP教師を切替え、異なる2D/事前学習モデルからの初期化を行っても、スケールとともに一貫して結果が改善する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。