[論文レビュー] Unicoder: A Universal Language Encoder by Pre-training with Multiple Cross-lingual Tasks
Unicoderは五つの跨言語タスクと多言語ファインチューニングを用いた普遍的言語エンコーダの事前学習を行い、Multilingual BERTおよびXLMのベースラインと比較してXNLIとXQAで最先端の結果を達成します。
We present Unicoder, a universal language encoder that is insensitive to different languages. Given an arbitrary NLP task, a model can be trained with Unicoder using training data in one language and directly applied to inputs of the same task in other languages. Comparing to similar efforts such as Multilingual BERT and XLM, three new cross-lingual pre-training tasks are proposed, including cross-lingual word recovery, cross-lingual paraphrase classification and cross-lingual masked language model. These tasks help Unicoder learn the mappings among different languages from more perspectives. We also find that doing fine-tuning on multiple languages together can bring further improvement. Experiments are performed on two tasks: cross-lingual natural language inference (XNLI) and cross-lingual question answering (XQA), where XLM is our baseline. On XNLI, 1.8% averaged accuracy improvement (on 15 languages) is obtained. On XQA, which is a new cross-lingual dataset built by us, 5.5% averaged accuracy improvement (on French and German) is obtained.
研究の動機と目的
- 限られたラベル付きデータしかない言語間での跨言語転移学習の必要性を動機づける。
- 複数の跨言語事前学習タスクで訓練された普遍的エンコーダを提案し、言語非依存表現を学習する。
- マルチ言語ファインチューニングにより跨言語転移がさらに改善されることを示す。
- 強力な多言語ベースラインと比較してXNLIとXQAで新たな最先端結果を確立し、経験的評価を行う。)
提案手法
- 15言語にまたがって共有される12層のトランスフォーマー、隠れ層1024、語彙数95kのUnicoderを導入する。
- 5つのタスクで事前学習する:マスク済み言語モデリング(MLM)、翻訳言語モデリング(TLM)、跨言語語彙回復、跨言語パラフレーズ分類、跨言語マスク済み言語モデリング(文書レベル)。
- 跨言語語彙回復で元の語を回復するための二言語文ペア注意機構を使用。
- 二言語の文を連結し先頭トークン表現を用いて二値分類を行うことで、跨言語パラフレーズ分類器を訓練する。
- 言語間で文を整列させて跨言語文書を構築し、256トークン列にMLMを適用する。
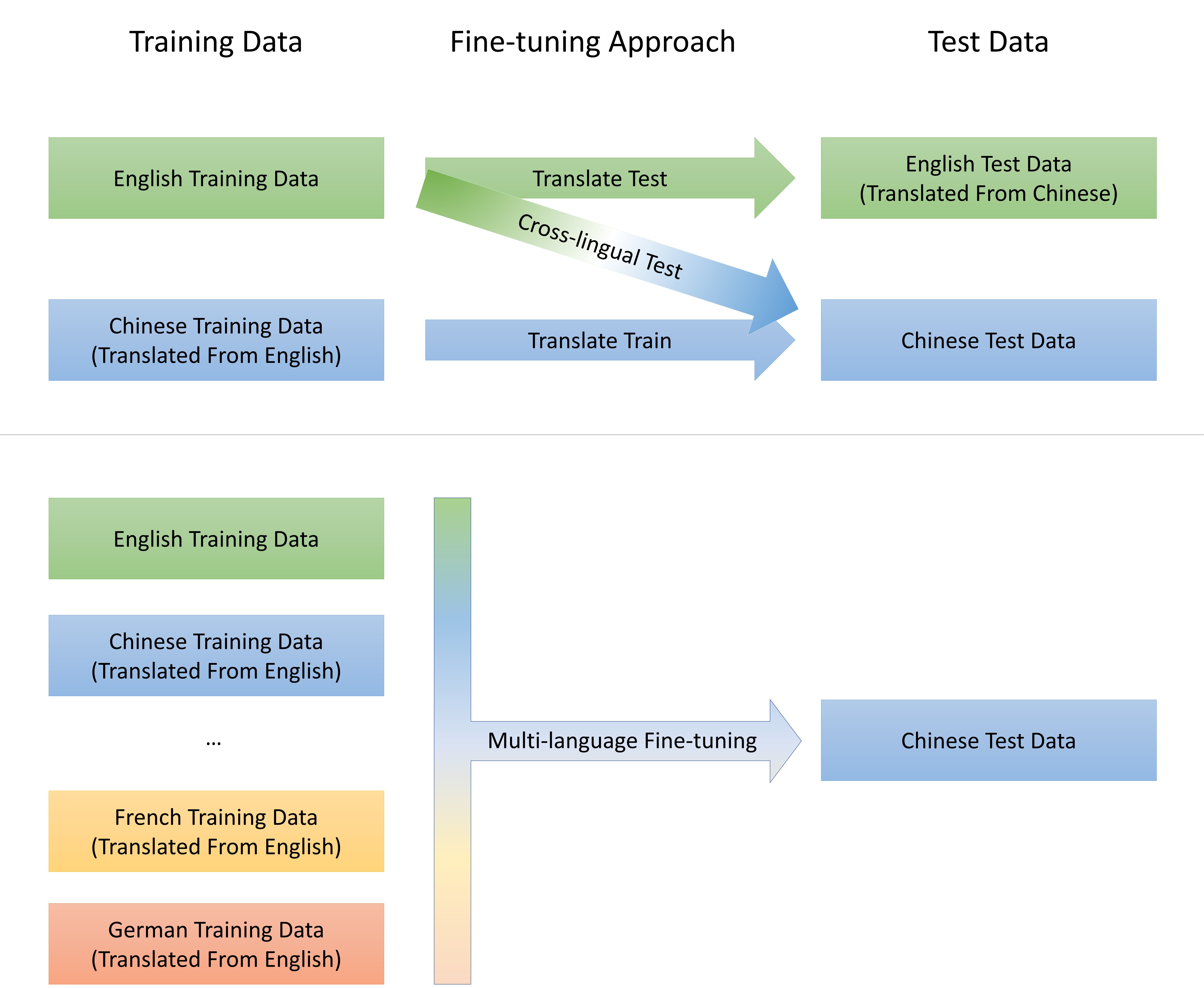
- Multi-language Fine-tuning戦略を用いて、複数言語(実データまたは疑似翻訳)のデータを共同訓練し転送を改善する。
実験結果
リサーチクエスチョン
- RQ1多言語ごとに言語特化の適応を極力必要とせず、 diverse な跨言語タスクで訓練された単一の普遍的エンコーダは、言語間で良好に機能できるか。
- RQ2MLMとTLM以外の追加の跨言語事前学習タスクは跨言語転移性能を改善するか。
- RQ3マルチ言語ファインチューニングはさらに跨言語性能を高めるか、言語カウントは利得にどう影響するか。
- RQ4UnicoderはXNLIとXQAで強力なベースライン(Multilingual BERT、XLM)と比較してどうか。
- RQ5英語と他言語を併用した joint fine-tuning は跨言語タスクにどのような影響をもたらすか。
主な発見
| Fine-tuning approach | XNLI average accuracy (%) |
|---|---|
| TRANSLATE-TRAIN (Conneau et al. 2018 baseline) | 65.4 |
| Multilingual BERT (Devlin et al. 2018) | 61.6 |
| XLM (Lample & Conneau 2019) | 76.7 |
| Unicoder (ours) | 76.9 |
| TRANSLATE-TEST (translate test data to English) | 67.2 |
| XLM (as baseline under TRANSLATE-TEST) | 74.2 |
| Unicoder (TRANSLATE-TEST) | 74.9 |
| Cross-lingual TEST (train English, test on target) | 65.6 |
| Unicoder (Cross-lingual TEST) | 75.4 |
| Multi-language Fine-tune (train English + multiple languages) | 77.8 |
| Unicoder (Multi-language Fine-tune) | 78.5 |
- UnicoderはXNLIで最先端の性能を達成し、特にMulti-language Fine-tuningで最高の設定時に平均正解率78.5%に達する。
- XNLIでは、Fine-tuning設定を問わずUnicoderはXLMを上回り、Multi-language Fine-tuningと組み合わせると最大で1.6%の利得。
- 新しいXQAデータセットでは、英語を含む他言語でファインチューニングし翻訳-訓練を適用した場合、平均正解率69.7%を達成し、XLMベースラインを最大5.5ポイント上回る。
- 3つの新しい跨言語タスクのいずれかを除去すると性能が低下し、語彙回復は利得に notably 貢献する。パラフレーズ分類は相対的に小さな低下を示す。
- Multi-language Fine-tuningは一貫して性能を向上させ、ファインチューニング時にはより多くの言語を用いるほど一般に良い結果を生むが、いくつかの言語ペアには例外もある。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。