[論文レビュー] Unified Training of Universal Time Series Forecasting Transformers
Moirai を導入し、LOTSAで訓練されたマスクドエンコーダーベースの普遍的時系列予測トランスフォーマーで、クロス周波数、任意の変量入力、柔軟な予測分布に対応し、ゼロショットで強力、様々なデータセットで競争力のあるフルショット結果を達成する。
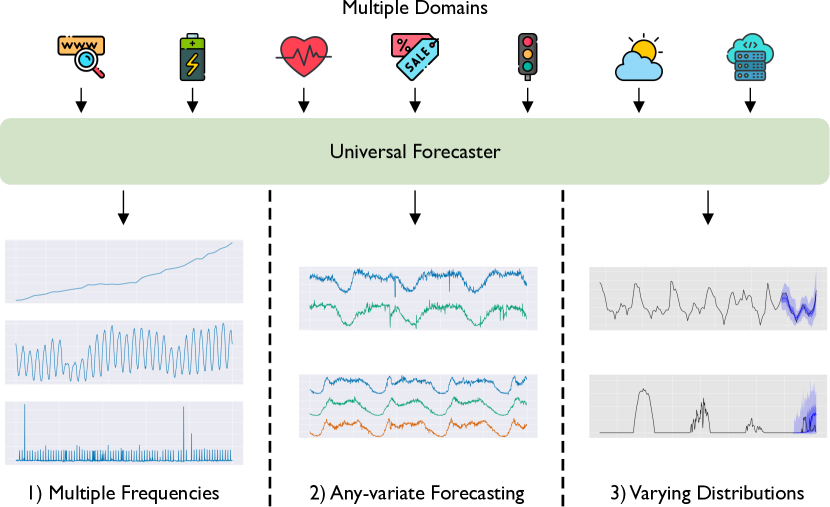
Deep learning for time series forecasting has traditionally operated within a one-model-per-dataset framework, limiting its potential to leverage the game-changing impact of large pre-trained models. The concept of universal forecasting, emerging from pre-training on a vast collection of time series datasets, envisions a single Large Time Series Model capable of addressing diverse downstream forecasting tasks. However, constructing such a model poses unique challenges specific to time series data: i) cross-frequency learning, ii) accommodating an arbitrary number of variates for multivariate time series, and iii) addressing the varying distributional properties inherent in large-scale data. To address these challenges, we present novel enhancements to the conventional time series Transformer architecture, resulting in our proposed Masked Encoder-based Universal Time Series Forecasting Transformer (Moirai). Trained on our newly introduced Large-scale Open Time Series Archive (LOTSA) featuring over 27B observations across nine domains, Moirai achieves competitive or superior performance as a zero-shot forecaster when compared to full-shot models. Code, data, and model weights can be found at https://github.com/SalesforceAIResearch/uni2ts.
研究の動機と目的
- データセットごとに1つのモデルで予測する方式から、普遍的で事前学習済みの時系列モデルへ移行する動機付け。
- 普遍的予測におけるクロス周波数学習、任意の変量数、変動するデータ分布への対応。
- 柔軟な周波数処理、任意変量入力、確率的出力を可能にするアーキテクチャと訓練の改善を開発。
- 普遍的予測モデルを支援するための大規模な公開時系列アーカイブとして LOTSA を作成・公開。
提案手法
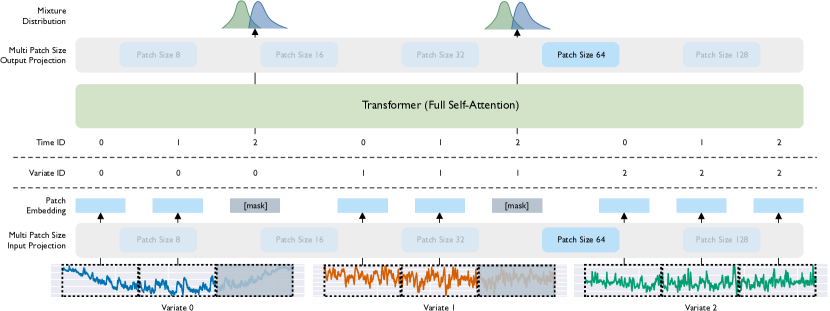
- さまざまな周波数に対応するための複数パッチサイズの入力/出力射影を備えた Masked Encoder-based Universal Time Series Forecasting Transformer (Moirai) の開発。
- バイナリ注意バイアスとロータリ位置エンベディングによる変变量対応エンコードを用いたフラット化された多変量時系列の処理を可能にする Any-variate Attention の導入。
- 学生の t 分布、負の二項分布、対数正規分布、低分散正規分布などを組み合わせた混合分布を用いた確率的予測。
- Moiraiを LOTSA 上で事前学習。九つのドメインにまたがる276億観測の公開時系列アーカイブで、サブデータセットと可変な文脈/予測ウィンドウをサンプリングするデータ/タスク分布。
- ゼロショット一般化を可能にするために、シーケンスパッキング、異なる文脈長、ベータ-二項分布による変量サンプリングを含む統一的な訓練戦略を採用。
実験結果
リサーチクエスチョン
- RQ1LOTSA の多様なデータで訓練された単一の大規模時系列モデルが、複数のデータセットと周波数に対してゼロショット予測を実行できるか?
- RQ2アーキテクチャの革新(Any-variate Attention、マルチパッチサイズ射影)と混合分布が、データセット特有のモデルより普遍的予測性能を向上させるか?
- RQ3Moirai は分布内(In-distribution)対分布外(ゼロショット)の設定で、完全ショットのベースラインと比べてどうか?
- RQ4LOTSA の規模と訓練戦略(パッキング、タスクサンプリング)がドメイン間一般化に与える影響は?
- RQ5長い・短いシーケンスデータセットのゼロショット予測性能に対して、文脈長はどう影響するか?
主な発見
- Moirai ベースおよび大規模は、未知データセットに対してゼロショット性能が競合・上回る。
- Monash/Monash風のベースラインと比較して、Moirai は単一モデルで多様なドメインにおける分布内評価で優れる。
- Moirai は複数データセットで強力なゼロショット確率予測を示し、時には最先端の完全ショット手法に匹敵する、または凌ぐ。
- マルチパッチサイズ、Any-variate Attention、柔軟な混合分布の重要性を示すアブレーション。
- 長いシーケンス予測の結果は、予測長の違いに対して競争力を維持できることを示し、タスクごとにモデルサイズの効果はニュアンスがある。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。