[論文レビュー] Unifying (Machine) Vision via Counterfactual World Modeling
この論文は Counterfactual World Modeling (CWM) を紹介します。統一された、教師なしの視覚フレームワークで、構造化マスキングと counterfactual prompting を用いて、ゼロショットの方法で複数の視覚計算(例:キーポイント、光学流、遮蔽、セグメンテーション、深度)を導出します。
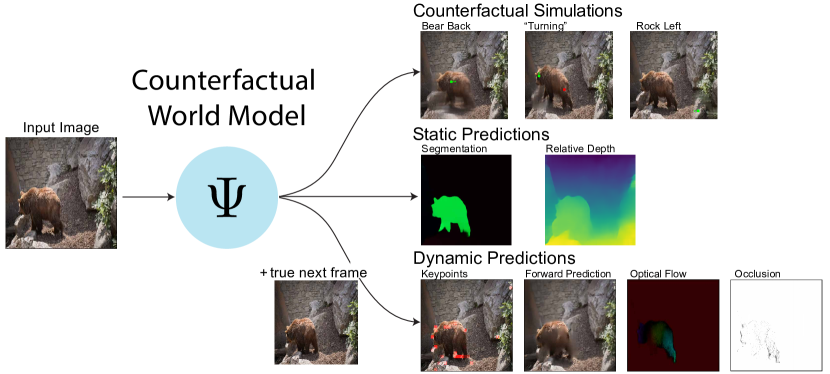
Leading approaches in machine vision employ different architectures for different tasks, trained on costly task-specific labeled datasets. This complexity has held back progress in areas, such as robotics, where robust task-general perception remains a bottleneck. In contrast, "foundation models" of natural language have shown how large pre-trained neural networks can provide zero-shot solutions to a broad spectrum of apparently distinct tasks. Here we introduce Counterfactual World Modeling (CWM), a framework for constructing a visual foundation model: a unified, unsupervised network that can be prompted to perform a wide variety of visual computations. CWM has two key components, which resolve the core issues that have hindered application of the foundation model concept to vision. The first is structured masking, a generalization of masked prediction methods that encourages a prediction model to capture the low-dimensional structure in visual data. The model thereby factors the key physical components of a scene and exposes an interface to them via small sets of visual tokens. This in turn enables CWM's second main idea -- counterfactual prompting -- the observation that many apparently distinct visual representations can be computed, in a zero-shot manner, by comparing the prediction model's output on real inputs versus slightly modified ("counterfactual") inputs. We show that CWM generates high-quality readouts on real-world images and videos for a diversity of tasks, including estimation of keypoints, optical flow, occlusions, object segments, and relative depth. Taken together, our results show that CWM is a promising path to unifying the manifold strands of machine vision in a conceptually simple foundation.
研究の動機と目的
- 言語モデルのゼロショットの多様性になぞらえた、視覚の基盤モデルアプローチを動機づける。
- 構造化マスキングを通じて場面の構造とダイナミクスを学習する、教師なしの統一予測モデルを開発する。
- ラベル付きデータなしで多様な視覚計算を導出するための、counterfactual prompting を介した汎用タスクインタフェースを可能にする。
- counterfactual 入力を介して、場面ダイナミクスのカウントと幾何を抽出・操作できることを示す。
提案手法
- 最初のフレームの大部分と第二フレームのごく一部を開示する構造化マスキングを用いて、外観をダイナミクスから因子分解する temporally-factored masked predictor を訓練する。
- 実入力と修正された入力(counterfactuals)を比較することによって、counterfactual prompts を用いて多様な視覚計算を導出する。
- キーポイントを再構成の明瞭さを最大化するパッチとして形式化し、ブートストラッピングで他の表現を導出できるようにする。
- 光学 flow, occlusion, movable-object segmentation, および relative depth が予測器の導関数または counterfactual から取得できることを示す。
- 表現とタスクを豊かにするために、マスキング方式と条件付け(例:頭部運動、複数フレームのマスキング)を拡張する。
- モデルの counterfactual 導関数が効率的な、ゼロショットのタスクインタフェースを提供する方法を説明する。
実験結果
リサーチクエスチョン
- RQ1構造化マスキングを通じて、単一の教師なし視覚モデルはコアな場面構造とダイナミクスを学習できるか。
- RQ2counterfactual prompting は predictions をゼロショットの解決策へと変換できるか。
- RQ3光学流、遮蔽、セグメンテーション、および深度を統一予測器から導出できるか。
- RQ4ブートストラッピングと導関数は多様な視覚表現を抽出する上でどのような役割を果たすか。
- RQ5マスキング方針の変化は learned representations とタスクのカバー範囲にどのような影響を与えるか。
主な発見
- temporally-factored masked predictor は appearance を dynamics から因子分解することを学習する。
- Counterfactual prompting は同じモデルから複数の視覚計算へのゼロショットアクセスをもたらす。
- 光学流と遮蔽は、予測器の導関数と counterfactual ゆらぎから導出できる。
- キーポイントは再構成誤差を最小化する最も近いパッチとして現れ、オブジェクトレベルの分析を可能にする。
- このフレームワークは、視覚の基盤モデル型アプローチの下で、いくつかの古典的な視覚概念を統合する。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。