[論文レビュー] Universal Planning Networks
UPNs は、差分可能な勾配ベースのプランナーをゴール条件付きポリシー内に埋め込み、計画可能な潜在表現を学習して、視覚運動タスクの計画、転移、報酬設計を改善します。 このアプローチは画像ベースのゴール指定と形態間の転移を可能にし、潜在空間はRL報酬にも利用できます。
A key challenge in complex visuomotor control is learning abstract representations that are effective for specifying goals, planning, and generalization. To this end, we introduce universal planning networks (UPN). UPNs embed differentiable planning within a goal-directed policy. This planning computation unrolls a forward model in a latent space and infers an optimal action plan through gradient descent trajectory optimization. The plan-by-gradient-descent process and its underlying representations are learned end-to-end to directly optimize a supervised imitation learning objective. We find that the representations learned are not only effective for goal-directed visual imitation via gradient-based trajectory optimization, but can also provide a metric for specifying goals using images. The learned representations can be leveraged to specify distance-based rewards to reach new target states for model-free reinforcement learning, resulting in substantially more effective learning when solving new tasks described via image-based goals. We were able to achieve successful transfer of visuomotor planning strategies across robots with significantly different morphologies and actuation capabilities.
研究の動機と目的
- 視覚入力から目標指向の計画と制御に有効な表現を学習する。
- ニューラルポリシー内に微分可能な勾配降下プランナーを組み込み、エンドツーエンドで訓練する。
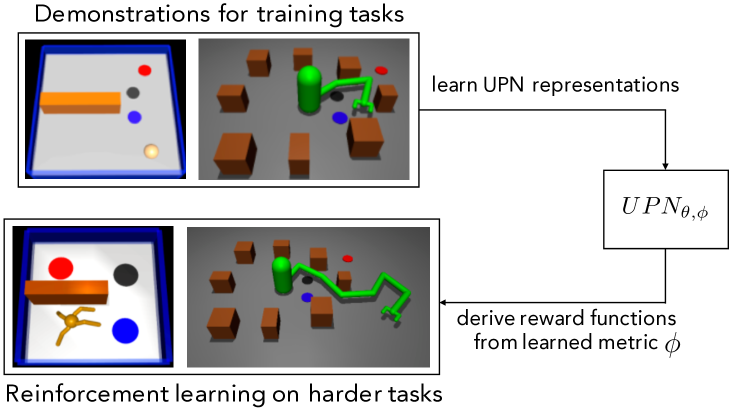
- 学習された潜在表現が画像ベースのゴール指定と形態間の転移をサポートすることを示す。
- 潜在空間が新しいタスクでモデルフリーRLの距離ベース報酬を提供できることを示す。
提案手法
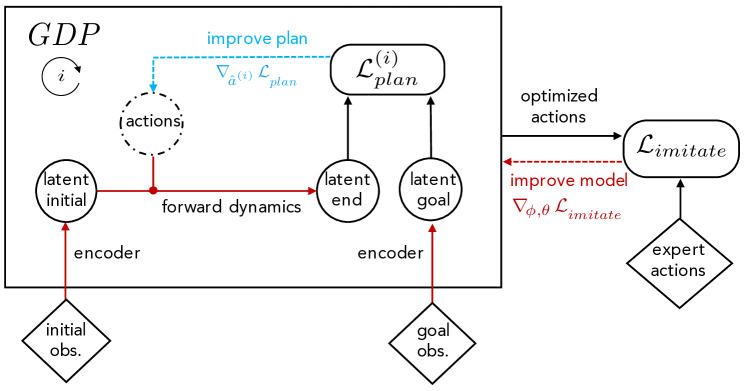
- f_phi によって現在の観測とゴール観測を潜在空間にエンコードし、前方モデル g_theta で遷移をシミュレートする。
- 潜在空間で勾配降下プランナー(GDP)を用いて、エンコード済みゴールとの距離を最小化する作用列を生成する。
- 計画計算グラフ全体を通して計画勾配をバックプロパゲーションし、phiとthetaを更新する。
- 外側の模倣学習目的で訓練し、専門家のデモを一致させる(Algorithm 2)。
- より長い視野を扱うために、テスト時にMPCスタイルの再計画を用いて再計画することもできる。
- Huber損失とRLのファインチューニングを用いて、潜在空間報酬 r(o_t,o_g) = -||f_phi(o_t)-f_phi(o_g)||^2 をデモンストレーションする。
実験結果
リサーチクエスチョン
- RQ1ポリシー内に勾配降下プランナーを埋め込むと、反応性や自己回帰ベースと比べてピクセルからの視覚運動模倣の精度が向上しますか?
- RQ2学習した潜在空間は、画像ベースのゴールを介して異なるロボット形状やより複雑なタスクへの転移をサポートしますか?
- RQ3テスト時の計画更新が性能を改善し、専門家の成功に近づきますか?
- RQ4新しいタスクでモデルフリーRLの距離ベース報酬を定義する際に、学習した表現は有用ですか?
主な発見
| 特徴空間 | 固定 | 変化 |
|---|---|---|
| RIL-RL | 0% | 0.01% |
| AIL-RL | 0% | 4.72% |
| VAE-RL | 20.23% | 24.67% |
| UPN-160 Imitation | 45.82% | 47.99% |
| Expert | 46.77% | 51.1 % |
| UPN-RL | 69.84% | 71.12% |
- UPNは従来の模倣学習者よりもデータが限られた状況で、効果的な視覚的ゴール指向方策をより効率的に学習します。
- 潜在表現は意味のある、障害物を考慮した距離指標を提供し、転移と報酬設計に有用です。
- テスト時にGDPの更新を増やすことで計画性能が向上し、十分なデモンストレーションがあれば専門家レベルに到達します。
- 潜在空間報酬は、転送タスクで他の特徴空間(VAE、RIL、AIL)を上回るRLを可能にします。
- UPN表現は、未見の形態やさらに複雑なタスクでRL性能を向上させることができます。
- UPN由来の報酬を用いた強化学習は、転送設定のいくつかで専門家の性能を上回ることが多いです。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。