[論文レビュー] UniWorld: Autonomous Driving Pre-training via World Models
UniWorld はラベルなしのマルチカメラ統合事前学習フレームワークを導入し、 unlabeled image-LiDAR ペアから 4D 幾何オキュペンシー世界モデルを学習して、モーション予測、マルチカメラ3D物体検出、周辺セマンティックシーン完成を向上させる。
In this paper, we draw inspiration from Alberto Elfes' pioneering work in 1989, where he introduced the concept of the occupancy grid as World Models for robots. We imbue the robot with a spatial-temporal world model, termed UniWorld, to perceive its surroundings and predict the future behavior of other participants. UniWorld involves initially predicting 4D geometric occupancy as the World Models for foundational stage and subsequently fine-tuning on downstream tasks. UniWorld can estimate missing information concerning the world state and predict plausible future states of the world. Besides, UniWorld's pre-training process is label-free, enabling the utilization of massive amounts of image-LiDAR pairs to build a Foundational Model.The proposed unified pre-training framework demonstrates promising results in key tasks such as motion prediction, multi-camera 3D object detection, and surrounding semantic scene completion. When compared to monocular pre-training methods on the nuScenes dataset, UniWorld shows a significant improvement of about 1.5% in IoU for motion prediction, 2.0% in mAP and 2.0% in NDS for multi-camera 3D object detection, as well as a 3% increase in mIoU for surrounding semantic scene completion. By adopting our unified pre-training method, a 25% reduction in 3D training annotation costs can be achieved, offering significant practical value for the implementation of real-world autonomous driving. Codes are publicly available at https://github.com/chaytonmin/UniWorld.
研究の動機と目的
- Motivate and leverage spatial-temporal world models for autonomous driving pre-training.
- Develop a label-free pre-training pipeline that uses multi-view data to reconstruct 4D occupancy and predict future scenes.
- Demonstrate that 4D occupancy-based pre-training improves downstream tasks such as motion prediction, multi-camera 3D detection, and semantic scene completion.
- Show that unified multi-camera pre-training reduces 3D annotation costs while leveraging unlabeled data.
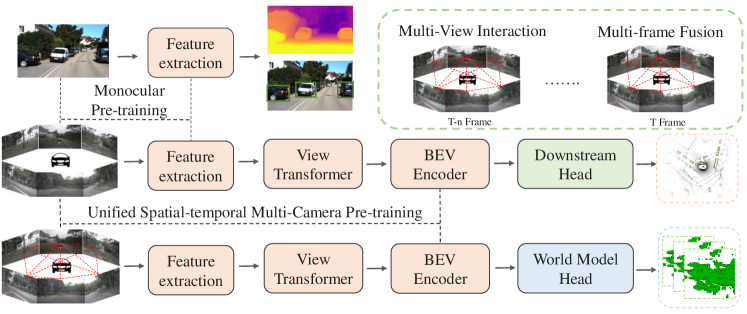
提案手法
- Transform multi-view images into a unified Bird's Eye View (BEV) representation using methods like LSS or Transformer-based view transforms.
- Introduce a 4D geometric occupancy decoder that predicts voxel-wise occupancy over D×H×W×1, learned via a binary occupancy classification with focal loss.
- Fuse multi-frame LiDAR point clouds to generate ground-truth 4D occupancy labels for pre-training, addressing frame sparsity and temporal dynamics.
- Pre-train the encoder and a lightweight 3D occupancy decoder, then discard the decoder and use the encoder to initialize downstream multi-camera perception models.
- Extend the pre-training to surrounding semantic occupancy by first reconstructing 3D geometry and then finetuning for semantic scene completion, reducing the need for dense 3D annotations.
- Compare UniWorld to monocular pre-training, depth-based pre-training, and knowledge distillation approaches, highlighting unified spatial-temporal learning and reduced annotation cost.
実験結果
リサーチクエスチョン
- RQ1Can a label-free, multi-camera unified pre-training framework learn accurate 4D occupancy representations from unlabeled image-LiDAR data?
- RQ2Does 4D occupancy-based pre-training improve downstream tasks in autonomous driving (motion prediction, multi-camera 3D object detection, semantic scene completion) compared to monocular or depth-based pre-training?
- RQ3How does multi-frame LiDAR fusion impact occupancy label quality and downstream performance?
- RQ4What is the data-efficiency benefit (in terms of annotation cost) of UniWorld for downstream 3D perception tasks?
主な発見
| Type | Method | Pre-train | Backbone | Image Size | CBGS | mAP | NDS | mATE | mASE | mAOE | mAVE | mAAE |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| DETR3D [7] | FCOS3D | R101-DCN | 900 × 1600 | ✓ | 0.349 | 0.434 | 0.716 | 0.268 | 0.379 | 0.842 | 0.200 | |
| FCOS3D + UniWorld-3D | R101-DCN | 900 × 1600 | ✓ | 0.360 | 0.461 | 0.701 | 0.260 | 0.372 | 0.730 | 0.188 | ||
| FCOS3D + UniWorld-4D | R101-DCN | 900 × 1600 | ✓ | 0.432 | 0.530 | 0.659 | 0.274 | 0.375 | 0.344 | 0.188 |
- UniWorld yields improvements over monocular pre-training in motion prediction (IoU and VPQ gains) and 3D object detection (mAP and NDS gains on nuScenes).
- UniWorld-3D improves multi-camera 3D object detection (mAP and NDS) and reduces downstream annotation costs by about 25%.
- 4D occupancy pre-training achieves notable gains in surrounding semantic occupancy prediction (mIoU improvements).
- Compared to monocular depth pre-training, UniWorld-based pre-training shows substantial gains in mAP and NDS on nuScenes test set.
- The approach demonstrates data-efficiency, with experiments indicating that 75% of labeled data can match full-data performance and 25% can surpass certain baselines when fine-tuning.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。