[論文レビュー] Unmasked Teacher: Towards Training-Efficient Video Foundation Models
この論文は Unmasked Teacher (UMT) を用いた、ラベルなしビデオマスキングを CLIP ベースの教師に導くことで、起動時からの迅速な収束とマルチモーダル能力を実現する、訓練効率の高い時系列対応ビデオファンデーションモデルのフレームワークを導入します。
Video Foundation Models (VFMs) have received limited exploration due to high computational costs and data scarcity. Previous VFMs rely on Image Foundation Models (IFMs), which face challenges in transferring to the video domain. Although VideoMAE has trained a robust ViT from limited data, its low-level reconstruction poses convergence difficulties and conflicts with high-level cross-modal alignment. This paper proposes a training-efficient method for temporal-sensitive VFMs that integrates the benefits of existing methods. To increase data efficiency, we mask out most of the low-semantics video tokens, but selectively align the unmasked tokens with IFM, which serves as the UnMasked Teacher (UMT). By providing semantic guidance, our method enables faster convergence and multimodal friendliness. With a progressive pre-training framework, our model can handle various tasks including scene-related, temporal-related, and complex video-language understanding. Using only public sources for pre-training in 6 days on 32 A100 GPUs, our scratch-built ViT-L/16 achieves state-of-the-art performances on various video tasks. The code and models will be released at https://github.com/OpenGVLab/unmasked_teacher.
研究の動機と目的
- データ不足と計算コストの高さのため、訓練効率の良い Video Foundation Models (VFMs) の必要性を動機づける。
- 教師によって導かれるマスク付きビデオモデリングを用いて、ゼロから学習可能なスケーラブルなフレームワークを提案する。
- Unmasked Teacher を用いた unmasked ビデオトークンの整合性を通じて、CLIP ベースの教師とマルチモーダルなビデオ理解を実現する。
- 公開データでの最先端性能を、ビデオのみおよびビデオ-言語のベンチマークで示す。
- 従来のウェブ規模アプローチと比較した訓練コストと排出量の削減による環境上の利益を示す。
提案手法
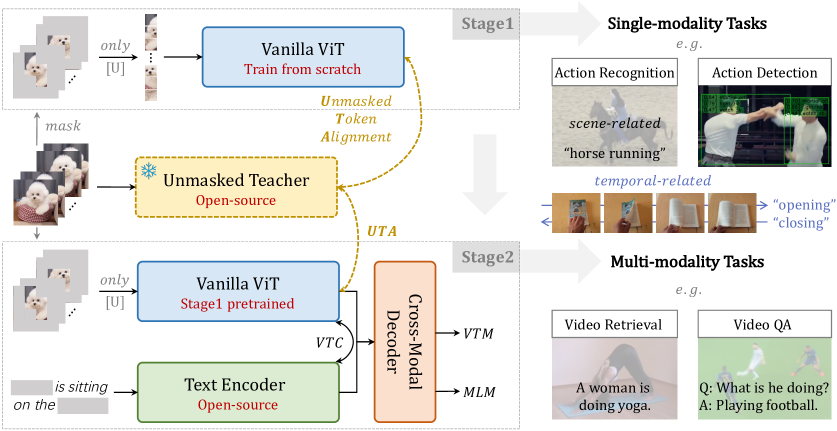
- Image Foundation Model (IFM) を Unmasked Teacher (UMT) として用い、vanilla ViT をゼロから訓練する。
- ビデオトークンに対して高い 80% の意味的マスキングを適用し、教師との整合はマスクされていないトークンのみを MSE によってトークン空間で行う。
- Temporal downsampling を行わずフレームごとの処理を維持し、フレームレベルの教師-学生整合を可能にする。
- 教師ガイドの整合と学生処理の双方において時空系の注意機構を採用し、トークン間の相互作用を促進する。
- 進化的なプレトレーニングパイプラインを採用:Stage 1 は UMT を用いたビデオのみのマスクドモデリング、Stage 2 はビジョン-言語データを用いたマルチモーダル訓練と目的を組み合わせる。
- Stage 2 の目的には Video-Text Contrastive (VTC)、Video-Text Matching (VTM)、Masked Language Modeling (MLM) を含み、Unmasked Token Alignment (UTA) は UMT からの核心的な指針である。
![Figure 1 : Comparison with SOTA methods. “ZS” and “FT” refer to “zero-shot” and “fine-tuned”. “T2V” means video-text retrieval. For Kinetics action recognition, [ 86 ] and [ 76 ] are excluded since they utilize model ensemble. With only public sources for pre-training, our approach achieves SOTA per](https://ar5iv.labs.arxiv.org/html/2303.16058/assets/x1.png)
実験結果
リサーチクエスチョン
- RQ1Unmasked Teacher フレームワークは masked ビデオモデリングを用いてゼロから訓練効率の良い VFMs を実現できるか。
- RQ2Unmasked video tokens を CLIP ベースの教師と整合させることで、ピクセル再構成や全モデル転送と比較して収束とマルチモーダル転送を改善するか。
- RQ3マスキング戦略、時間的サンプリング、注意機構がシーン関連および時間関連のビデオタスクの性能にどのように影響するか。
- RQ4公開データと進化的プレトレーニング設定を用いた訓練で、性能向上とデータ効iciency はどの程度か。
- RQ5提案手法は計算資源を抑えつつ、アクション認識、局在化、ビデオ-言語ベンチマークで最先端の結果をどの程度達成できるか。
主な発見
- 公開データと 32 A100 GPU を用い 6 日間で複数のビデオタスクで最先端の結果を達成(例:K400 の top-1 90.6%、AVA の 39.8 mAP、MSRVTT の 58.8 R@1、MSRVTT VQA の 47.1%)。
- 意味的マスキングを用いた Unmasked Token Alignment (UTA) は、Pixel Reconstruction ターゲットや単一再構成アプローチよりも、効率と精度の両方で上回る。
- 意味的マスキングと疎なフレームサンプリング、最後の層での整合は、ランダムマスキングや過度な時間的ダウンサンプリングよりも良い結果を生む。
- 前 training 中の共通の時空系注意は性能を高め、UMT はビデオ領域での転送後に CLIP 教師を上回る。
- Stage-wise の進行的トレーニング(ビデオのみ → 視覚-言語)により、データと計算を抑制しつつ強力なビデオ-言語理解を実現する。
- CoCa と比較して、UMT は碳排出を約 70 倍低減しつつ競争力ある、あるいはそれを上回るタスク性能を達成する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。