[論文レビュー] Unsupervised Deep Anomaly Detection for Multi-Sensor Time-Series Signals
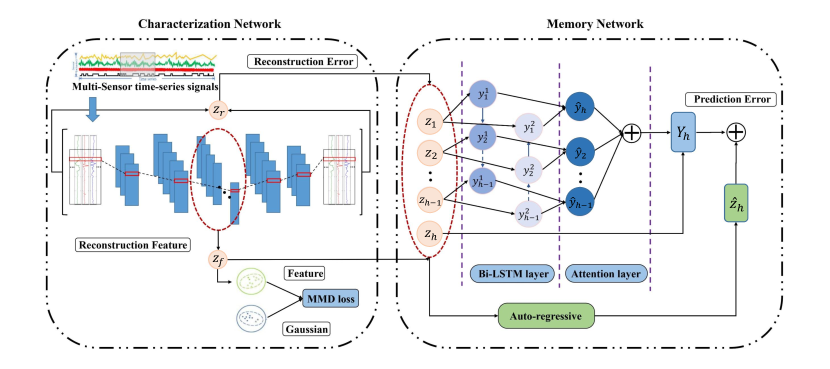
本稿では、空間的および時間的依存関係を共同でモデル化することで、異常検出のための新しい教師なし深層学習モデルCAE-Mを提案する。畳み込み自己符号化器とMMD正則化、および自己回帰的および注意ベースの双方向LSTMを組み合わせたハイブリッドメモリネットワークを採用し、HARおよびHCデータセットで最先端の性能を達成し、ノイズの多いデータに対しても頑健である。
Nowadays, multi-sensor technologies are applied in many fields, e.g., Health Care (HC), Human Activity Recognition (HAR), and Industrial Control System (ICS). These sensors can generate a substantial amount of multivariate time-series data. Unsupervised anomaly detection on multi-sensor time-series data has been proven critical in machine learning researches. The key challenge is to discover generalized normal patterns by capturing spatial-temporal correlation in multi-sensor data. Beyond this challenge, the noisy data is often intertwined with the training data, which is likely to mislead the model by making it hard to distinguish between the normal, abnormal, and noisy data. Few of previous researches can jointly address these two challenges. In this paper, we propose a novel deep learning-based anomaly detection algorithm called Deep Convolutional Autoencoding Memory network (CAE-M). We first build a Deep Convolutional Autoencoder to characterize spatial dependence of multi-sensor data with a Maximum Mean Discrepancy (MMD) to better distinguish between the noisy, normal, and abnormal data. Then, we construct a Memory Network consisting of linear (Autoregressive Model) and non-linear predictions (Bidirectional LSTM with Attention) to capture temporal dependence from time-series data. Finally, CAE-M jointly optimizes these two subnetworks. We empirically compare the proposed approach with several state-of-the-art anomaly detection methods on HAR and HC datasets. Experimental results demonstrate that our proposed model outperforms these existing methods.
研究の動機と目的
- 異常がまれでラベルが付与されていないマルチセンサー時系列データにおける教師なし異常検出の課題に対処すること。
- 多次元時系列信号における空間的および時間的依存関係を共同でモデル化し、一般化された正常パターンを捉えること。
- 訓練中にノイズの影響を受けると、ノイズを正常と誤認する可能性があるため、ノイズに対するモデルの頑健性を向上させること。
- 2段階または別々に訓練されたモデルの限界を克服し、特徴抽出部と予測部を共同で最適化すること。
- 再構築誤差と予測誤差を統合した統一スコアとしての複合異常検出フレームワークを構築し、微細な異常検出を可能にすること。
提案手法
- モデルは、最大平均差分(MMD)正則化を用いた深層畳み込み自己符号化器(CAE)を採用し、ノイズや訓練データ内の異常に対する過学習を低減する強固な表現を学習する。
- メモリネットワークは2本の並列ブランチで構成される:線形自己回帰モデルと自己注意を備えた非線形双方向LSTM(BiLSTM)。
- CAE-Mモデルは、CAEからの再構築損失、自己回帰モデルからの予測損失、および注意ベースのBiLSTMからの予測損失を共同で最適化する。
- 異常スコアは、再構築誤差と予測誤差を組み合わせた複合目的関数として計算され、微細な異常検出を可能にする。
- モデルはエンドツーエンドで訓練され、複合損失を最小化することで、一般化性能とデータノイズに対する頑健性が向上する。
- 制御変数低減法と繰り返し訓練解析を用いて、複数のデータセットにおけるハイパーパrameterの感度と収束性を評価する。
実験結果
リサーチクエスチョン
- RQ1統合された深層学習フレームワークは、マルチセンサー時系列データにおける空間的および時間的依存関係を効果的にモデル化できるか?
- RQ2MMD正則化を組み込むことで、異常検出におけるノイズの多い訓練データに対するモデルの頑健性はどのように向上するか?
- RQ3自己回帰的モデリングと注意ベースのBiLSTMのどちらが、異常検出における時間的ダイナミクスを捉える上で相対的に寄与しているか?
- RQ4特徴抽出部と予測部の共同最適化は、サブネットワークを別々に訓練する場合よりも優れた性能をもたらすか?
- RQ5再構築損失と予測損失の重み付けに依存するハイパーパrameterの選択に、モデルの性能はどれほど感度を示すか?
主な発見
- CAE-MはHARおよび医療(HC)データセットで最先端の手法を上回り、F1、精度、再現率の観点から優れた検出性能を示した。
- アブレーションスタディの結果、自己回帰部を削除したCAE-M w/o ARでは顕著な性能低下が生じ、時間的ダイナミクスをモデル化する上でその重要性が確認された。
- 注意メカニズムとMMD正則化は、すべてのデータセットで顕著な性能向上に寄与しており、特にMMDはノイズへの過学習を低減する点で顕著に有効であった。
- CAE-Mはガウスノイズが30%まで増加しても安定した性能を維持し、UODAやConvLSTM-COMPOSITEと比較して優れた頑健性を示した。
- すべてのデータセットで40回未満の訓練イテレーションで収束し、高速かつ安定した訓練が可能であることが示された。
- パラメータ感度分析の結果、ハイパーパrameterの値の広い範囲でモデルの性能が安定しており、最適な重みはλ₁ = 1e-4、λ₂ = 0.5、λ₃ = 0.5の付近で得られた。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。