[論文レビュー] Unsupervised Learning of Disentangled and Interpretable Representations from Sequential Data
因子分解された階層型変分オートエンコーダー(FHVAE)を提案し、逐次データの系列レベルとセグメントレベル属性の監督なしでの分離を実現。音声でi-vectorベースラインを上回る改善と、ミスマッチ条件でのASR性能向上を示した。
We present a factorized hierarchical variational autoencoder, which learns disentangled and interpretable representations from sequential data without supervision. Specifically, we exploit the multi-scale nature of information in sequential data by formulating it explicitly within a factorized hierarchical graphical model that imposes sequence-dependent priors and sequence-independent priors to different sets of latent variables. The model is evaluated on two speech corpora to demonstrate, qualitatively, its ability to transform speakers or linguistic content by manipulating different sets of latent variables; and quantitatively, its ability to outperform an i-vector baseline for speaker verification and reduce the word error rate by as much as 35% in mismatched train/test scenarios for automatic speech recognition tasks.
研究の動機と目的
- 逐次データの多段階情報を活用して、監督なしで解離可能かつ解釈可能な潜在因子を学習する。
- 属性を系列レベル(z2)とセグメントレベル(z1)の潜在変数に分解する。系列依存分布と系列非依存分布を用いて。
- 長い系列を扱いつつ時系列構造を保持するためのセグメントレベルのスケーラブル推論を可能にする。
- 定性的分析と定量的なASRおよび話者検証タスクを通じて分離表現の学習を示す。
提案手法
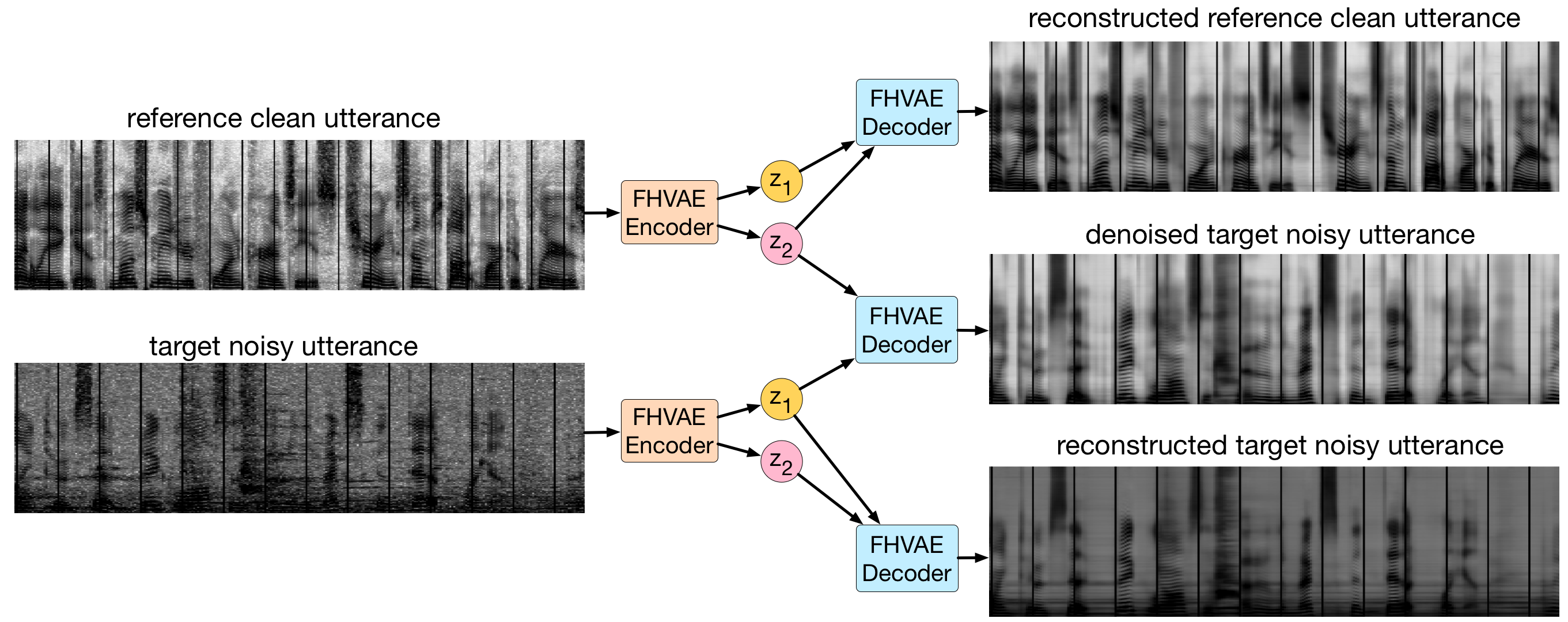
- 2つの潜在変数集合を持つFactorized Hierarchical Variational Autoencoder (FHVAE) を導入する。z1(セグメントレベル)と z2(系列レベル)に加えて、各系列に対するs-vector μ2 を追加。
- P(z1) は系列非依存の事前分布、P(z2|μ2) は系列依存の事前分布、P(x|z1,z2) は平均/分散がニューラルネット fμx(·,·) および fσ2x(·,·) によって与えられるガウス分布である。
- エンコーダ qφ(z1|x,z2)、qφ(z2|x)、および qφ(μ2) は対角ガウス分布で、LSTM/MLP ネットワークでパラメータ化される。識別目的の目的関数 α log p(i|z2) は z2 が系列レベル属性を符号化するよう促す。
- Seq2Seq-FHVAE アーキテクチャを用いて、全系列ではなくセグメントレベルの下界を評価することでセグメントレベルの最適化とスケーラビリティを実現する。
- z2 後方分布を用いた閉形式近似(式 Eq. 5)によるテスト時の μ2 推論を提供し、発話レベルの表現としての利用を可能にする。
実験結果
リサーチクエスチョン
- RQ1Can a factorized hierarchical VAE learn disentangled, interpretable sequence-level and segment-level latent factors from sequential data without supervision?
- RQ2Do the segment-level (z1) and sequence-level (z2) latents align with linguistic content and speaker/ channel attributes respectively in speech?
- RQ3Do the learned latent variables improve speaker verification and domain-invariant ASR compared to baselines such as i-vectors and β-VAE features?
- RQ4Is segment-level latent representation robust to domain mismatches in ASR and useful for voice conversion or denoising tasks?
主な発見
| Features | Dimension | Alpha | Raw | LDA (12 dim) | LDA (24 dim) |
|---|---|---|---|---|---|
| i-vector | 48 | - | 10.12% | 6.25% | 5.95% |
| i-vector | 100 | - | 9.52% | 6.10% | 5.50% |
| i-vector | 200 | - | 9.82% | 6.54% | 6.10% |
| μ2 | 16 | 0 | 5.06% | 4.02% | - |
| μ2 | 16 | 1e-1 | 4.91% | 4.61% | - |
| μ2 | 16 | 1 | 3.87% | 3.86% | - |
| μ2 | 16 | 1e1 | 2.38% | 2.08% | - |
| μ2 | 32 | 1e1 | 2.38% | 2.08% | 1.34% |
- On speaker verification (TIMIT), μ2 (16–32 dim) outperforms i-vector baselines in Raw and LDA settings, achieving as low as 2.38% EER with 32-dim μ2 and α=10^1.
- In domain-mismatch ASR (Aurora-4), latent z1 features reduce WER significantly across noisy/channel conditions and outperform FBank and β-VAE baselines in several mismatched domains.
- Replacing z2 with a different speaker can yield voice-converted outputs preserving linguistic content, evidencing disentanglement of speaker and content.
- Qualitative analyses show z1 capturing segment-level linguistic content and z2 capturing sequence-level attributes, enabling denoising by swapping μ2-related representations.
![Figure 3: Sequence-to-sequence factorized hierarchical variational autoencoder. Dashed lines indicate the sampling process using the reparameterization trick [ 24 ] . The encoders for $\bm{z}_{1}$ and $\bm{z}_{2}$ are pink and amber, respectively, while the decoder for $\bm{x}$ is blue. Darker color](https://ar5iv.labs.arxiv.org/html/1709.07902/assets/x3.png)
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。