[論文レビュー] UP-DETR: Unsupervised Pre-training for Object Detection with Transformers
UP-DETRは、新規のランダムクエリパッチ検出タスクを用いてラベルなし画像でDETRトランスフォーマーを事前学習し、CNNバックボーンを事前学習中に凍結させることでDETRの収束と物体検出、ワンショット検出、パンオプティック分割の性能を向上させる。
DEtection TRansformer (DETR) for object detection reaches competitive performance compared with Faster R-CNN via a transformer encoder-decoder architecture. However, trained with scratch transformers, DETR needs large-scale training data and an extreme long training schedule even on COCO dataset. Inspired by the great success of pre-training transformers in natural language processing, we propose a novel pretext task named random query patch detection in Unsupervised Pre-training DETR (UP-DETR). Specifically, we randomly crop patches from the given image and then feed them as queries to the decoder. The model is pre-trained to detect these query patches from the input image. During the pre-training, we address two critical issues: multi-task learning and multi-query localization. (1) To trade off classification and localization preferences in the pretext task, we find that freezing the CNN backbone is the prerequisite for the success of pre-training transformers. (2) To perform multi-query localization, we develop UP-DETR with multi-query patch detection with attention mask. Besides, UP-DETR also provides a unified perspective for fine-tuning object detection and one-shot detection tasks. In our experiments, UP-DETR significantly boosts the performance of DETR with faster convergence and higher average precision on object detection, one-shot detection and panoptic segmentation. Code and pre-training models: https://github.com/dddzg/up-detr.
研究の動機と目的
- 限られたデータからゼロから始めるのではなく、トランスフォーマーを事前学習させてDETRの性能を向上させる動機づけ。
- DETRの局在化フォーカスに合わせた自己教師付き事前タスクとして、ランダムクエリパッチ検出を導入。
- CNNバックボーンを凍結し、分類と局在化特徴のバランスを取ることで安定した事前学習を確保。
- 同じ事前学習モデルを用いた物体検出とワンショット検出の統一的なファインチューニング経路を可能に。
- マルチクエリパッチ検出と注意機構マスクへの拡張を検討し、DETRにおけるNMS風の挙動を模倣。
提案手法
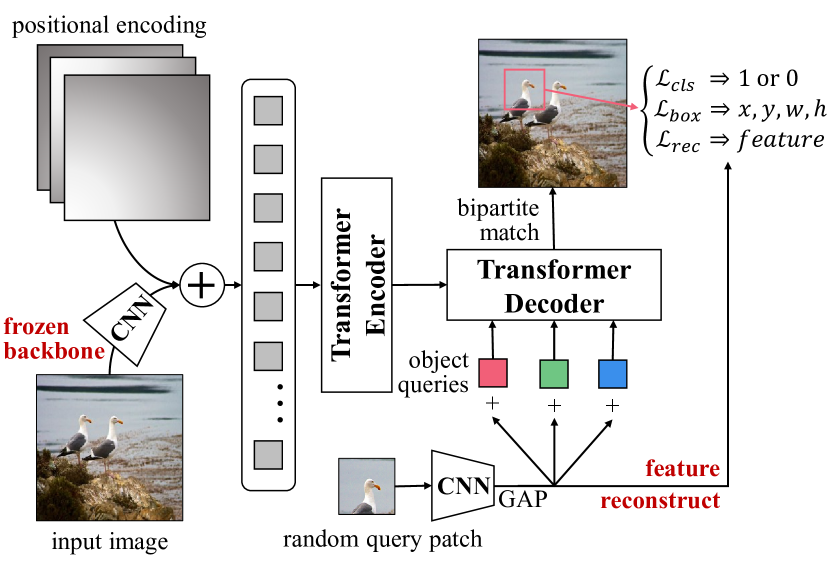
- 教師なし画像上でランダムクエリパッチ検出タスクを用いてトランスフォーマーエンコーダ-デコーダを事前学習。
- CNNバックボーンでパッチ特徴を抽出し、クエリパッチとオブジェクトクエリをトランスフォーマーデコーダに入力してパッチ境界ボックスを予測。
- 分類、ボックス回帰(L1 + IoU)、および局在化/特徴を保持する任意のパッチ再構成損失を組み合わせたハンガリー対応の損失を用いる。
- 事前学習中にCNNバックボーンを凍結し、特徴識別能力を保持し効果的な局在学習を可能にする。
- オブジェクトクエリをグループ化し、グループ間の相互作用を制御するアテンションマスクを適用してマルチクエリパッチ検出へ拡張。
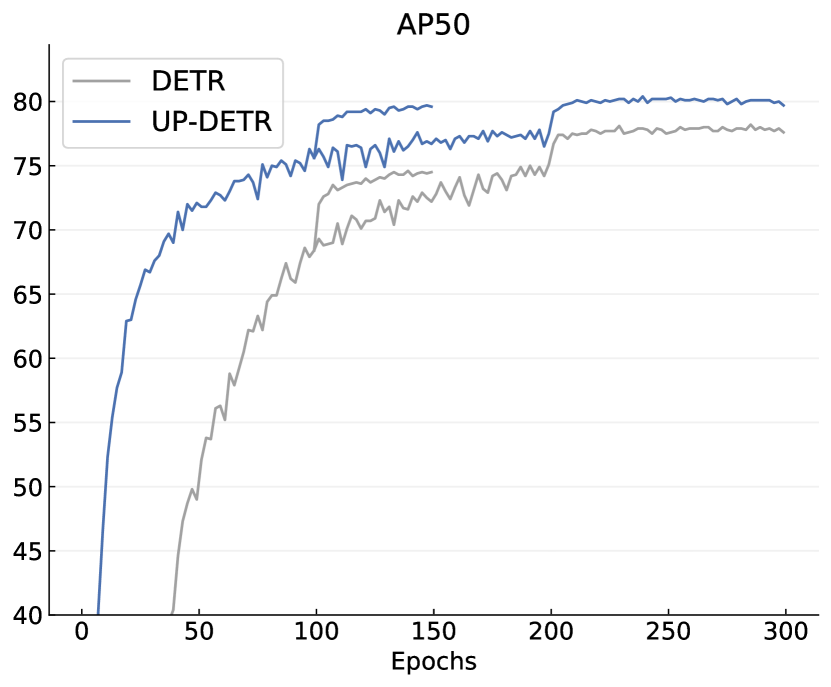
実験結果
リサーチクエスチョン
- RQ1教師なし事前学習でDETRトランスフォーマーはVOC/COCOデータセットでの収束速度と検出精度を、ゼロから学習する場合と比較して改善するか。
- RQ2凍結CNNバックボーンを用いることでランダムクエリパッチ検出の前処理タスクはDETRの局在化フォーカスをより効果的に活用できるか。
- RQ3マルチクエリパッチ検出と注意マスクはクエリ間競合をより良く反映し、ワンショット検出やパンオプティック分割などの下流タスクを改善するか。
- RQ4UP-DETRはDETRと比較してワンショット検出やパンオプティック分割へどの程度転移するか。
- RQ5パッチ特徴再構成が局在化事前学習中の分類スタイル特徴の保持に与える影響はどの程度か。
主な発見
| モデル | バックボーン | エポック | AP | AP50 | AP75 |
|---|---|---|---|---|---|
| Faster R-CNN | R50 | - | 56.1 | 82.6 | 62.7 |
| DETR/150 | R50 | 150 | 49.9 | 74.5 | 53.1 |
| UP-DETR/150 | R50 | 150 | 56.1 | 79.7 | 60.6 |
| DETR/300 | R50 | 300 | 54.1 | 78.0 | 58.3 |
| UP-DETR/300 | R50 | 300 | 57.2 | 80.1 | 62.0 |
- UP-DETRはVOCおよびCOCOで短期/長期の訓練スケジュールの後、DETRよりも高速に収束し、より高いAPを達成する。
- PASCAL VOCでは、バックボーンを凍結したUP-DETRは150エポックでDETRより最大で+6.2 AP、300エポックで+7.5 APを達成し、Faster R-CNNの性能に近づく。
- COCOでは、150エポックのUP-DETRはDETRをわずかに上回り、同等のスケジュールでFaster R-CNNと同等、300エポックではDETRを超え、Faster R-CNN(R50-FPN)をわずかに上回るAP。
- ワンショット検出の結果はUP-DETRがDETRを大幅に改善し、VOC設定の seen/unseen クラスの両方で顕著な向上を示す。
- パンオプティック分割の結果はUP-DETRがDETRよりPQ, SQ, RQ 指標で改善し、AP segおよび関連パンオプティックスコアが向上。
- アブレーションではマルチクエリパッチ(M=10)は単一クエリパッチを上回り、バックボーン凍結とパッチ特徴再構成が事前学習の有効性に有益であることを示した。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。