[論文レビュー] Use of LLMs for Illicit Purposes: Threats, Prevention Measures, and Vulnerabilities
本論文は、違法利用に関連する大規模言語モデル(LLMs)の脅威、予防措置、脆弱性の分類を提示し、既存文献を概観し、安全性の課題、防御策、攻撃サーフェスについて論じる。
Spurred by the recent rapid increase in the development and distribution of large language models (LLMs) across industry and academia, much recent work has drawn attention to safety- and security-related threats and vulnerabilities of LLMs, including in the context of potentially criminal activities. Specifically, it has been shown that LLMs can be misused for fraud, impersonation, and the generation of malware; while other authors have considered the more general problem of AI alignment. It is important that developers and practitioners alike are aware of security-related problems with such models. In this paper, we provide an overview of existing - predominantly scientific - efforts on identifying and mitigating threats and vulnerabilities arising from LLMs. We present a taxonomy describing the relationship between threats caused by the generative capabilities of LLMs, prevention measures intended to address such threats, and vulnerabilities arising from imperfect prevention measures. With our work, we hope to raise awareness of the limitations of LLMs in light of such security concerns, among both experienced developers and novel users of such technologies.
研究の動機と目的
- LLMsが生成機能を通じて悪意のある活動をどのように可能にするかを特徴づける。
- 脅威、防御、脆弱性を統一的な分類に整理して、既存の研究を整理する。
- 現在の予防方法の限界を強調し、今後のセキュリティ上の懸念を概説する。
提案手法
- LLMの安全性とセキュリティに関する査読付き・査読無し文献を厳選し、統合する。
- 脅威、予防策、脆弱性を結ぶ分類法を提案する。
- 多様な研究からの実証的および定性的知見を要約し、リスクの全体像を示す。
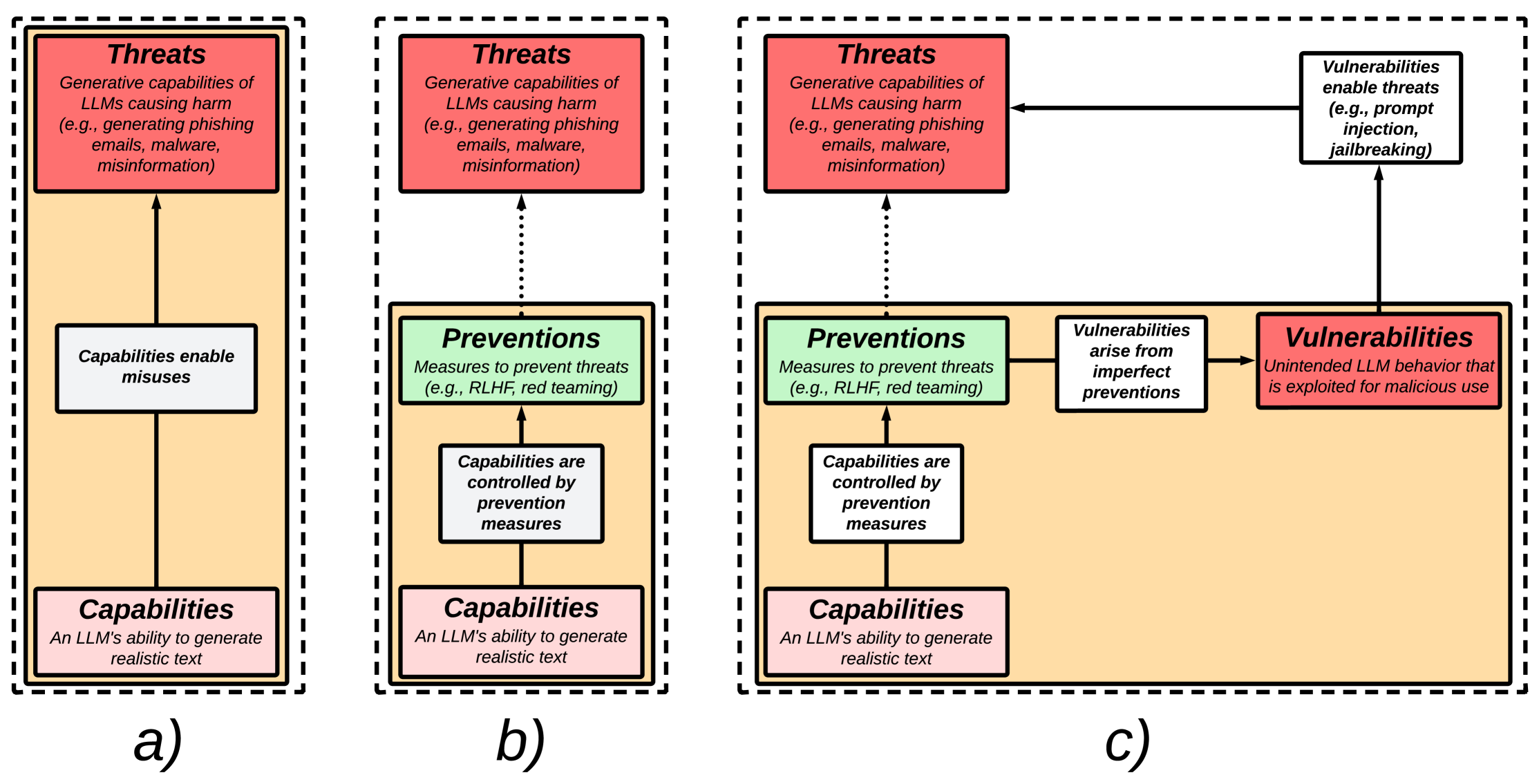
実験結果
リサーチクエスチョン
- RQ1LLMs の生成能力から生じる脅威は何か(例:詐欺、なりすまし、マルウェア、誤情報など)?
- RQ2これらの脅威を緩和するために提案されている予防策は何か(例:コンテンツフィルタリング、RLHF、red teaming)?
- RQ3予防が不完全な場合に生じる脆弱性は何か(例:プロンプトインジェクション、ジャイルブレイキング)?
- RQ4LLM 安全性研究のより広い制約と将来のセキュリティ上の懸念は何か?
主な発見
- LLMs は詐欺、なりすまし、マルウェア生成、誤情報、データ関連の被害などに悪用されうる。
- 予防策には、コンテンツ検出、red teaming、RLHF、指示への従順による安全性、データ保護戦略が含まれる。
- プロンプトインジェクションやジャイルブレイキングなどの脆弱性は、予防努力にもかかわらず脅威を再度有効にする可能性がある。
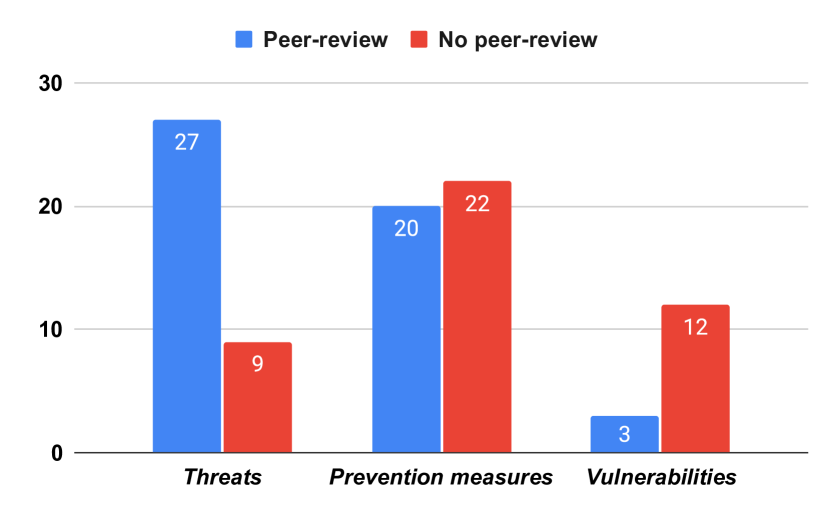
- 文献基盤は、査読付きと査読無しの研究の混在であり、形式的な検証の度合いも様々である。
- 本論文は公的関心と、進化する攻撃サーフェスに対するLLM安全性の継続的評価の必要性について論じている。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。