[論文レビュー] User-LLM: Efficient LLM Contextualization with User Embeddings
User-LLMは多モーダルなユーザー相互作用をコンパクトな埋め込みに抽出し、それをLLMsへクロスアテンションで結合することで、全LLMを再訓練せずに効率的かつ長い文脈のパーソナライズを実現します。
Large language models (LLMs) have achieved remarkable success across various domains, but effectively incorporating complex and potentially noisy user timeline data into LLMs remains a challenge. Current approaches often involve translating user timelines into text descriptions before feeding them to LLMs, which can be inefficient and may not fully capture the nuances of user behavior. Inspired by how LLMs are effectively integrated with images through direct embeddings, we propose User-LLM, a novel framework that leverages user embeddings to directly contextualize LLMs with user history interactions. These embeddings, generated by a user encoder pretrained using self-supervised learning on diverse user interactions, capture latent user behaviors and interests as well as their evolution over time. We integrate these user embeddings with LLMs through cross-attention, enabling LLMs to dynamically adapt their responses based on the context of a user's past actions and preferences. Our approach achieves significant efficiency gains by representing user timelines directly as embeddings, leading to substantial inference speedups of up to 78.1X. Comprehensive experiments on MovieLens, Amazon Review, and Google Local Review datasets demonstrate that User-LLM outperforms text-prompt-based contextualization on tasks requiring deep user understanding, with improvements of up to 16.33%, particularly excelling on long sequences that capture subtle shifts in user behavior. Furthermore, the incorporation of Perceiver layers streamlines the integration between user encoders and LLMs, yielding additional computational savings.
研究の動機と目的
- 多様な相互作用から得られる圧縮されたユーザー表現を活用して、パーソナライズされたLLMを動機づける。
- 2段階のフレームワークを提案する: (1) embeddingsを生成するユーザーエンコーダを事前学習する, (2) クロスアテンションまたはソフトプロンプトでLLMsに埋め込みを統合する。
- 長いシーケンスと多モーダルデータに対する効率とスケーラビリティを複数データセットで実証する。
- 埋め込みベースのパーソナライズとテキストプロンプトのベースラインおよび全パラメータ微調整とを比較し、パラメータ効率の高い学習戦略を含めて検討する。
提案手法
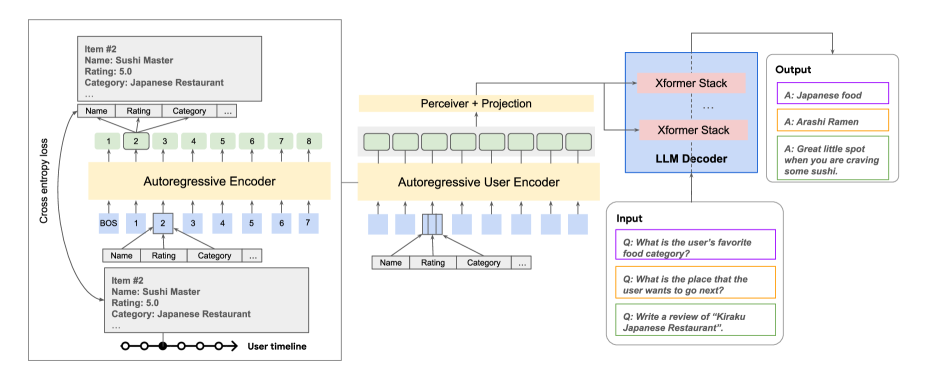
- 多モーダルなユーザ履歴に対してTransformerベースの自己回帰型ユーザーエンコーダを訓練し、イベントごとに密な埋め込みを生成する。
- 2つ以上のモダリティからの埋め込みを統合して、ユーザーの埋め込みの単一シーケンスを作成する。
- クロスアテンション(またはソフトプロンプト)を介してユーザー埋め込みをLLMsと統合し、生成と予測を条件付ける。
- Perceiver層を用いて埋め込みを圧縮し、LLMのアテンション負荷を軽減して効率化する。
- 4つの訓練戦略を検討: Full finetune、Enc(LLMを凍結)、LoRA、Proj(LLMとエンコーダを凍結)。
- LLMとして PaLM-2 XXS を使用し、ユーザーエンコーダは6層・128次元のトランスフォーマーとする。クロスアテンションとソフトプロンプト結合の比較を行う。
実験結果
リサーチクエスチョン
- RQ1多モーダルな相互作用から蒸留されたユーザー埋め込みは、テキストプロンプトよりも効率的にLLMパーソナライゼーションを向上させることができますか?
- RQ2LLMsへのユーザー埋め込みの統合において、クロスアテンションとソフトプロンプト結合はどのように比較されますか?
- RQ3長い履歴で、ユーザー埋め込みとPerceiver圧縮を使用した場合のFLOPと文脈長の効率向上はどの程度ですか?
- RQ4事前学習済みのユーザーエンコーダは、次アイテム予測以外のタスク(ジャンル予測やレビュー生成など)にうまく一般化しますか?
- RQ5異なる訓練戦略(Full、Enc、LoRA、Proj)は、性能とパラメータ効率にどのように影響しますか?
主な発見
| データセット | Rec | ベースライン | User-LLM | MovieLens20M @1 | MovieLens20M @5 | MovieLens20M @10 | Google Review @1 | Google Review @5 | Google Review @10 | Amazon Review @1 | Amazon Review @5 | Amazon Review @10 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| MovieLens20M | @1 | 0.044 | 0.038 | 0.054 | ||||||||
| MovieLens20M | @5 | 0.135 | 0.135 | 0.164 | ||||||||
| MovieLens20M | @10 | 0.206 | 0.158 | 0.243 | ||||||||
| Google Review | @1 | 0.005 | 0.005 | 0.015 | ||||||||
| Google Review | @5 | 0.012 | 0.019 | 0.052 | ||||||||
| Google Review | @10 | 0.023 | 0.033 | 0.071 | ||||||||
| Amazon Review | @1 | 0.021 | 0.034 | 0.037 | ||||||||
| Amazon Review | @5 | 0.026 | 0.051 | 0.047 | ||||||||
| Amazon Review | @10 | 0.031 | 0.062 | 0.051 |
- User-LLMはMovieLensおよびGoogle Local Reviewの次アイテム予測で非LLMベースラインより優れている。Amazon ReviewはBert4Recを好み、データセットのスパース性の影響を強調している。
- 埋め込みベースの文脈処理により、入力シーケンス長に関係なく固定長プロンプト(32トークン)を処理でき、テキストプロンプトベースのベースラインと比べてFLOPsを最大で78.1倍削減できる。
- 事前学習済みユーザーエンコーダは、タスク全般でランダム初期化版より一貫した向上をもたらす。
- クロスアテンション結合は一般にソフトプロンプト結合より優れ、特にレビュー生成タスクでそうである。
- エンコーダと射影層のみを微調整する(Enc)は、全微調整よりはるかに少ない学習可能パラメータで競争力の性能を達成し、LLMの知識を保つ。
- Perceiverベースの圧縮により埋め込みトークンを削減(例: 50から16へ)し、最小限の性能低下で推論効率を向上させる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。