[論文レビュー] Using Imperfect Surrogates for Downstream Inference: Design-based Supervised Learning for Social Science Applications of Large Language Models
本論文は、設計ベースの教師あり学習(DSL)と呼ばれる二重頑健な手法を提案します。これは、LLMから得られる不完全な代理ラベルと少量の金標本ラベルのサブセットを組み合わせることで、社会科学の回帰分析における有効な下流推定を可能にします。代理が偏っていても、一貫性・漸近正規性・有効な信頼区間を保証します。
In computational social science (CSS), researchers analyze documents to explain social and political phenomena. In most scenarios, CSS researchers first obtain labels for documents and then explain labels using interpretable regression analyses in the second step. One increasingly common way to annotate documents cheaply at scale is through large language models (LLMs). However, like other scalable ways of producing annotations, such surrogate labels are often imperfect and biased. We present a new algorithm for using imperfect annotation surrogates for downstream statistical analyses while guaranteeing statistical properties -- like asymptotic unbiasedness and proper uncertainty quantification -- which are fundamental to CSS research. We show that direct use of surrogate labels in downstream statistical analyses leads to substantial bias and invalid confidence intervals, even with high surrogate accuracy of 80-90%. To address this, we build on debiased machine learning to propose the design-based supervised learning (DSL) estimator. DSL employs a doubly-robust procedure to combine surrogate labels with a smaller number of high-quality, gold-standard labels. Our approach guarantees valid inference for downstream statistical analyses, even when surrogates are arbitrarily biased and without requiring stringent assumptions, by controlling the probability of sampling documents for gold-standard labeling. Both our theoretical analysis and experimental results show that DSL provides valid statistical inference while achieving root mean squared errors comparable to existing alternatives that focus only on prediction without inferential guarantees.
研究の動機と目的
- 不完実 proxyラベル(例:LLM出力)を社会科学の下流統計分析に用いる動機づけと正式化を行い、推論の妥当性を確保する。
- 偏りを修正する設計ベースの推定量を開発し、代理の正確さに依存せず一貫性と正確な被覆を達成する。
- 金標本ラベリングの既知のサンプリング確率の下で、一貫性・漸近正規性・有効な信頼区間を保証する理論的保証を提供する。
- DSLのバイアス制御と競争的な効率性を示す18の実データセットを横断して、実証的性能を示す。
提案手法
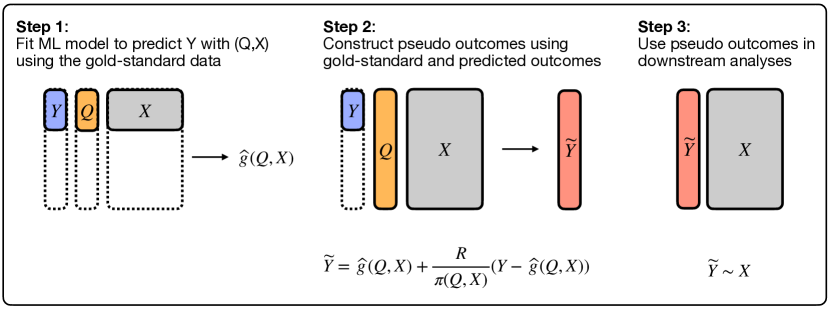
- 代理Q、金標本Y、共変量X、サンプリング指標Rと既知の確率pi(Q,W,X)を用いたデータ生成設定を定義する。
- K分割クロスフィットを用いた、バイアス修正付き疑似アウトカム tilde{Y}_i^k = hat{g}_k(Q_i,W_i,X_i) + (R_i/pi(Q_i,W_i,X_i))(Y_i - hat{g}_k(Q_i,W_i,X_i)) を導入する。
- 疑似アウトカムを用いたロジスティック回帰モーメントを解く: sum_k sum_{i in D_k} (tilde{Y}_i^k - expit(X_i^T beta)) X_i = 0。
- Assumption 1の下でDSL推定量 beta_hat が一貫性と漸近正規性を満たすこと、そして一貫した分散推定量 V_hat を得ることを証明する。
- 複数の代理とモーメント推定量を許容する設計ベースのモーメントへ拡張する(Definition 2, Equation 7)。
- DSLをSurrogate Only(SO)、Gold-Standard Only(GSO)、Supervised Learning(SL)と横断する18データセットでベンチマークし、DSLが有効な被覆と競争力のあるRMSEを達成することを示す。
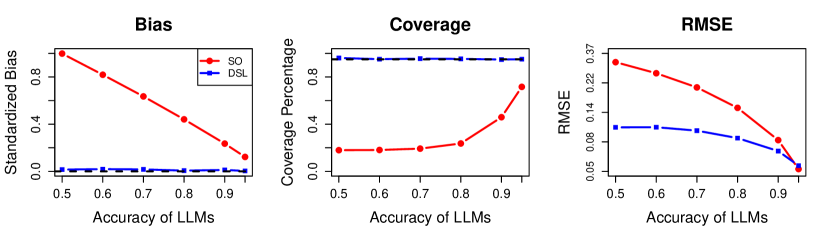
実験結果
リサーチクエスチョン
- RQ1不完実代理ラベルを用いて、下流回帰分析と有効な統計推論を行うことは可能か?
- RQ2既知の金標準サンプリング確率の下で、代理が偏っていてもバイアス修正疑似アウトカムは一貫性と漸近正規性をもたらすか?
- RQ3SNSデータセットを横断して、DSLはSO、GSO、SLと比べてバイアス、被覆、RMSEでどうなるか?
- RQ4ロジスティック回帰以外のモーメントベース推定量にも適用可能な広いクラスへ拡張できるか?
主な発見
- DSLは、代理ラベルを用いたバイアス修正疑似アウトカムにより、下流回帰係数の一貫性と漸近正規性を提供する。
- DSLの分散推定量は一貫しており、代理モデルの正確性の仮定を正しく指定する必要なく、有効な信頼区間を得られる。
- 代理が任意に偏っていても金標準ラベリング確率が既知でゼロからbounded awayであればDSLは有効のままである。
- 18データセットに渡る実証結果は、DSLが低いバイアスと名目上またはほぼ名目どおりの被覆を達成し、RMSEは予測重視の代替手法と同等、または金標準のみのベースラインより改善されることを示す。
- 代理の精度が向上すると(例:ポストLLMプロンプトが増えるなど)、DSLの効率性が向上し、代理が高品質のときはRMSEの改善が大きい。
- このフレームワークは複数の代理に対応し、設計ベースのモーメントへ拡張可能で、社会科学の一般的な推定量へ広く適用できる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。