[論文レビュー] Using Large Language Models to Generate JUnit Tests: An Empirical Study
この研究は、ゼロショットで Java の JUnit5 テスト生成における Codex、GPT-3.5-Turbo、StarCoder を評価し、HumanEval および SF110 ベンチマークにおけるコンパイル、正確性、カバレージ、テストスメル、そして文脈スタイルの影響を分析します。
A code generation model generates code by taking a prompt from a code comment, existing code, or a combination of both. Although code generation models (e.g., GitHub Copilot) are increasingly being adopted in practice, it is unclear whether they can successfully be used for unit test generation without fine-tuning for a strongly typed language like Java. To fill this gap, we investigated how well three models (Codex, GPT-3.5-Turbo, and StarCoder) can generate unit tests. We used two benchmarks (HumanEval and Evosuite SF110) to investigate the effect of context generation on the unit test generation process. We evaluated the models based on compilation rates, test correctness, test coverage, and test smells. We found that the Codex model achieved above 80% coverage for the HumanEval dataset, but no model had more than 2% coverage for the EvoSuite SF110 benchmark. The generated tests also suffered from test smells, such as Duplicated Asserts and Empty Tests.
研究の動機と目的
- ゼロショット LLM が Java クラスの JUnit テストをどれだけうまく生成できるかを評価する。
- JavaDocs やメソッド署名など、異なる文脈入力がテスト生成の性能に与える影響を検討する。
- コンパイル、正確性、カバレージ、スメル指標の観点で LLM が生成したテストを Evosuite と比較する。
- LLM が生成したテストにおける一般的なテストスメルとその普及度を特徴づける。
- コード生成モデルを用いたテスト駆動開発への示唆を論じる。
提案手法
- 3つの LLM(Codex、GPT-3.5-Turbo、StarCoder)を用いて、Java の HumanEval データセットおよび SF110 ベンチマークの MUT に対して JUnit5 テストを生成する。
- テスト対象のクラスと必要な JUnit のインポートを含むプロンプトと文脈を作成し、検査可能な各メソッドごとに1つのテストファイルを生成する。
- 生成テストのコンパイル問題に対処するヒューリスティック修正を適用し、修正後のコンパイル率を測定する。
- JaCoCo を用いて行と分岐のカバレージと合格率に基づく正確性を評価する。前提として生産コードが正しいと仮定する。
- 生成テストと Evosuite / 手動ベースラインに対して TsDetect でテストスメルを検出する。
- 2つの研究質問中心の実験を実施する:RQ1(全体のテスト生成性能)と RQ2(文脈要素の影響)。
- コンパイルエラーのクラスタリングによって根本原因を分析し、共通の故障モードを特定する。)
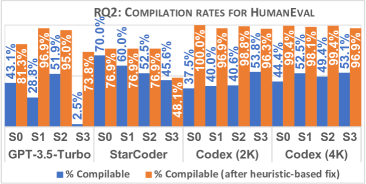
実験結果
リサーチクエスチョン
- RQ1RQ1: 選択されたベンチマーク上で LLM は Java MUT の JUnit テストをどれだけ上手く生成できるか?
- RQ2RQ2: プロンプト中の異なる文脈要素はテスト生成における LLM の性能にどう影響する?
- RQ3LLMs が生成したテストは、コンパイル、正確性、カバレージ、スメルの観点で Evosuite とどう比較されるか?
主な発見
- Codex は HumanEval で80%を超えるカバレージを達成したが、修正前には SF110 でいずれのモデルも2%を超えなかった。
- ヒューリスティック修正を適用した後、データセット全体で平均約41%のコンパイル率の向上。
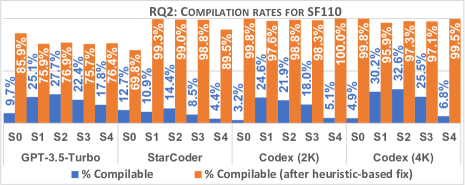
- StarCoder は SF110 で最高のコンパイル可能テスト比率を示したのは 12.7%(ただし修正による改善はモデルごとに異なる)。
- HumanEval では、修正後 StarCoder テストの 70% がコンパイル。Codex (2K) は修正前 37.5% から修正後 100% コンパイル可能に、Codex (4K) は 44.4% から 99.4% に改善。
- SF110 では修正前のコンパイル率は一般に低く(2.7%–12.7%)、修正後約81%向上。Evosuite は設計上 100% コンパイル可能を達成。
- 正確性率は控えめで、HumanEval では StarCoder が約81% 正解;他は Codex 系で 41–77%;SF110 の正確性はより低く、最高で StarCoder の約 51.9% 正解。
- HumanEval のカバレージ:Codex (4K) がライン 87.7%、ブランチ 92.8% を達成。Evosuite および手動テストが一部でより高いカバレージを示した。
- SF110 のカバレージは LLMs 全体で著しく低く(概ね ≤約2%)、Evosuite が大幅に上回った。
- LLM 生成テストにはテストスメルが多く見られ、特に Magic Number (MNT) と Assertion Roulette (AR); SF110 で StarCoder は特にスメル発生率が高く、少なくとも1つのスメルがある割合が 96.7%。
- 文脈シナリオ(JavaDoc の有無、実装の有無)はコンパイルと正確性に影響を与えた。GPT-3.5-Turbo は特定のシナリオ構成で急激に低下することが多かった一方、Codex と StarCoder は異なる反応を示した。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。