[論文レビュー] V2X-Boosted Federated Learning for Cooperative Intelligent Transportation Systems with Contextual Client Selection
本論文は、V2Xデータを用いて将来のネットワーク遅延を予測し、データ分布でクライアントをクラスタリングし、非iid設定でFLの性能を向上させるために低遅延クライアントを選択する、車両ネットワークにおける連合学習のための四段階の文脈的クライアント選択パイプラインを提案する。
Machine learning (ML) has revolutionized transportation systems, enabling autonomous driving and smart traffic services. Federated learning (FL) overcomes privacy constraints by training ML models in distributed systems, exchanging model parameters instead of raw data. However, the dynamic states of connected vehicles affect the network connection quality and influence the FL performance. To tackle this challenge, we propose a contextual client selection pipeline that uses Vehicle-to-Everything (V2X) messages to select clients based on the predicted communication latency. The pipeline includes: (i) fusing V2X messages, (ii) predicting future traffic topology, (iii) pre-clustering clients based on local data distribution similarity, and (iv) selecting clients with minimal latency for future model aggregation. Experiments show that our pipeline outperforms baselines on various datasets, particularly in non-iid settings.
研究の動機と目的
- 連携ITS(C-ITS)における連合学習のデータとネットワークの異質性に対応する。
- V2Xメッセージを活用して将来のネットワーク遅延と道路トポロジを予測する。
- データ分布の類似性でクライアントをクラスタリングし、非 iid効果を低減する。
- 代表的で低遅延なクライアントを選択してアグリゲーションの効率と収束を向上させる。
提案手法
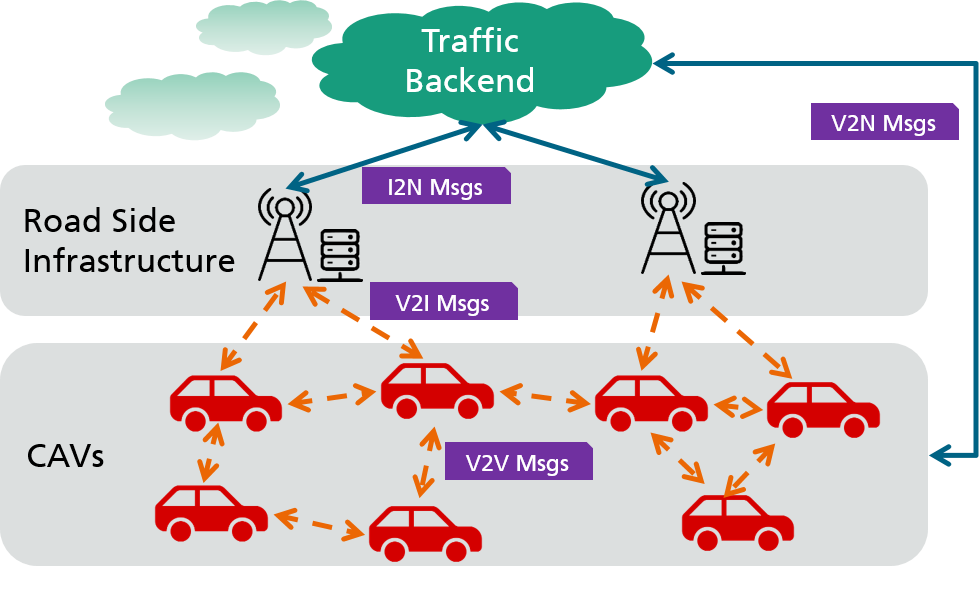
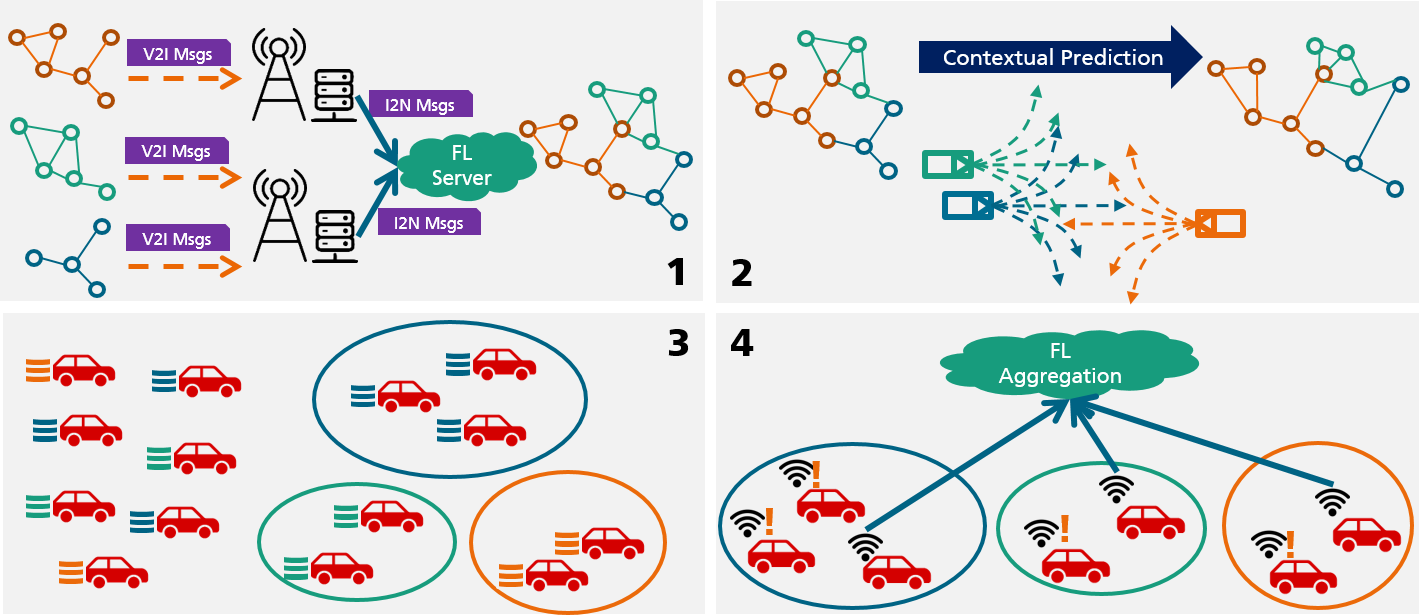
- CAM/CPM V2Xメッセージを融合して道路交通トポロジーグラフ(RTTG)を構築する。
- 将来のRTTGを予測して今後のラウンドの各クライアントの接続品質を推定する。
- データレベルのクラスタリングのために勾配/パラメータの類似性でクライアントをグループ化する。
- 予測されたRTTG遅延とFast-gammaルールを用いて、クラスタごとに小さく低遅延なクライアント集合を選択してアグリゲーションを行う。
- 非iidのMNIST、CIFAR-10、SVHNを100台の車両に分散させてこのアプローチを評価し、greedy、gossip、データベースベース、ネットワークベースのベースラインと比較する。
実験結果
リサーチクエスチョン
- RQ1V2X情報をどのように融合・活用して車串環境におけるFLの将来遅延を予測できるか。
- RQ2データレベルとネットワークレベルの文脈クライアント選択は、CAVs間の非iidデータ下でFLの性能を改善できるか。
- RQ3文脈的選択フレームワークは、精度の収束と通信効率の点で標準的なベースラインと比較してどうか。
- RQ4接続率の変動とデータ異質性に対してアプローチは堅牢か。
主な発見
| CR | 戦略 | 時間(秒) | 削減率 |
|---|---|---|---|
| - | Gossip | 3891.14 | 1× |
| 1.0 | データベースベース | 213.50 | 18.23× |
| ネットワークベース | 620.47 | 6.27× | |
| 文脈的 | 193.77 | 20.08× | |
| 0.5 | データベースベース | 2446.75 | 1.59× |
| ネットワークベース | 690.29 | 5.64× | |
| 文脈的 | 179.54 | 21.67× | |
| 0.2 | データベースベース | 2563.20 | 1.52× |
| ネットワークベース | 634.12 | 6.14× | |
| 文脈的 | 186.47 | 20.87× |
- 文脈的クライアント選択は、非iid設定下でMNIST、CIFAR-10、SVHNのいずれにおいて四つのベースライン(Greedy、Gossip、Data-based、Network-based)よりも優れている。
- 方法は収束をより速く達成し、0.5精度到達時間の削減がベースラインより20倍以上を示す。
- データ異質性がある場合でも、ネットワークベース戦略より安定した収束を示す。
- 接続クライアント割合が20%程度に低くなっても性能向上が持続する。
- 実験は非iidデータ分布に対して一貫して高いテスト精度と頑健性を示す。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。