[論文レビュー] VerifAI: Verified Generative AI
VerifAI は、マルチモーダルデータレイクを取得・ 推論して生成AIの出力を検証するモジュラーな枠組みを提案し、タプル、表、テキスト出力の信頼性を向上させる。
Generative AI has made significant strides, yet concerns about the accuracy and reliability of its outputs continue to grow. Such inaccuracies can have serious consequences such as inaccurate decision-making, the spread of false information, privacy violations, legal liabilities, and more. Although efforts to address these risks are underway, including explainable AI and responsible AI practices such as transparency, privacy protection, bias mitigation, and social and environmental responsibility, misinformation caused by generative AI will remain a significant challenge. We propose that verifying the outputs of generative AI from a data management perspective is an emerging issue for generative AI. This involves analyzing the underlying data from multi-modal data lakes, including text files, tables, and knowledge graphs, and assessing its quality and consistency. By doing so, we can establish a stronger foundation for evaluating the outputs of generative AI models. Such an approach can ensure the correctness of generative AI, promote transparency, and enable decision-making with greater confidence. Our vision is to promote the development of verifiable generative AI and contribute to a more trustworthy and responsible use of AI.
研究の動機と目的
- 生成AI出力を検証するデータ管理の視点を促進する。
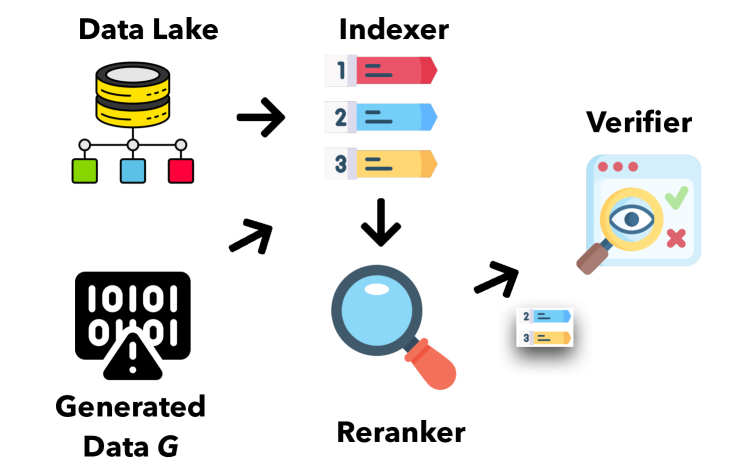
- データレイクの証拠と照合して生成データをインデックス化、リランキング、検証できるモジュラー枠組みを開発する。
- タプルとテキスト検証の予備実験で実現可能性を示す。
- 横断モーダルなデータ発見と検証における未解決問題と課題を強調する。
提案手法
- マルチモーダルデータをカバーする content-based (Elasticsearch) および vector-based (Faiss) インデックスを用いたインデクサー。
- テキスト同士の細粒度・タスク特化のランキングを提供するリランキング(ColBERTによるテキスト-テキスト、OpenTFVによるテキスト-表)。
- 汎用的なモデル(例: ChatGPT)と局所化されたモデルの検証者アンサンブル(表検証は OpenTFV/PASTA、タプル検証は RoBERTa ベース)を含む。
- (g, x) マッピングと 0/1/2 ラベル(verified, refuted, not related)を用いた証拠主導の検証。
- 検証系の系統追跡を支援し、人間のデバッグをサポートするプロ venance ハンドリング。
- データレイクから取得されたデータを用いて生成された表とテキスト検証を実験的に設定。
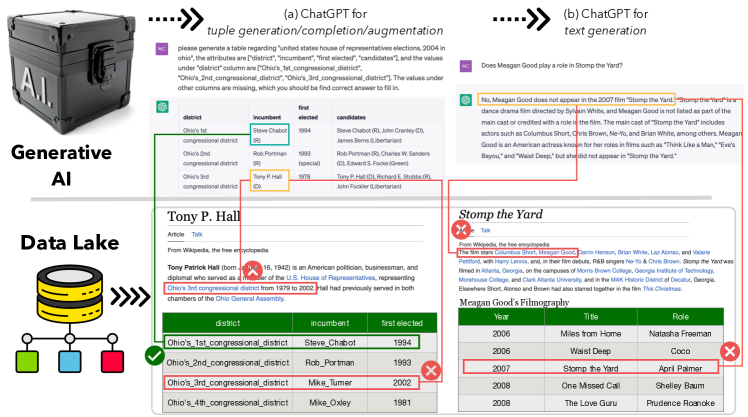
実験結果
リサーチクエスチョン
- RQ1モジュール型の検証器(Indexer-Reranker-Verifier)は、データレイクの証拠を用いて生成AIの出力を信頼できるように検証または否定できるか。
- RQ2マルチモーダルデータレイクは、生成されたタプル、表、テキストの主張の検証を支援するか。
- RQ3異なるモダリティにおける汎用モデルと局所化モデルの相対的な性能はどうなるか。
- RQ4生成AIの出力を検証する際の実務上の課題(プライバシー、信頼性、プロ venance など)は何か。
主な発見
| Generated data type | Retrieved data type | Recall |
|---|---|---|
| tuple | tuple | 0.99 |
| text | text files | 0.58 |
| textual claim | table | 0.88 |
- VerifAI は検証タスクに関連するデータを高い再現率で取得できる(tuple-to-tuple 0.99、text-to-text 0.58、textual claim-to-table 0.88)。
- 検証者としての ChatGPT は (tuple, tuple) 検証で 0.88 の精度を達成し、特定のテキスト-表のケースで一部の専門モデルを上回ることがある;PASTA は関連表が取得された場合、(text, table) 検証で ChatGPT を上回る。
- テキストの主張検証は取得された表の恩恵を受け、PASTA は関連するケースで ChatGPT を超える一方、多くの表が関係ない場合には ChatGPT の汎化が優れる。
- 本研究はデータソースのプロ venance と信頼性の重要性を強調し、横断モーダルな発見と検証を重要な未解決問題として特定する。
- 取得は (tuple, tuple) および (textual claim, table) に対して有効性を示す一方、tuple に裏付けられた証拠に結びつくテキストファイルの取得は性能が低い。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。