[論文レビュー] VerilogEval: Evaluating Large Language Models for Verilog Code Generation
この論文は VerilogEval を紹介します。Verilog に焦点を当てたベンチマーク(156 HDLBits problems)を用いて、Verilog コード生成に対する LLM の評価を行い、自動化されたテストパイプラインと性能向上のための合成された教師あり微調整データを含みます。
The increasing popularity of large language models (LLMs) has paved the way for their application in diverse domains. This paper proposes a benchmarking framework tailored specifically for evaluating LLM performance in the context of Verilog code generation for hardware design and verification. We present a comprehensive evaluation dataset consisting of 156 problems from the Verilog instructional website HDLBits. The evaluation set consists of a diverse set of Verilog code generation tasks, ranging from simple combinational circuits to complex finite state machines. The Verilog code completions can be automatically tested for functional correctness by comparing the transient simulation outputs of the generated design with a golden solution. We also demonstrate that the Verilog code generation capability of pretrained language models could be improved with supervised fine-tuning by bootstrapping with LLM generated synthetic problem-code pairs.
研究の動機と目的
- Verilog コード生成のドメイン特化型ベンチマークを、明確な正解基準を持つ HDLBits 問題を活用して動機づける。
- 生成された Verilog コードの機能的正確性を評価する自動化されたテスト環境を提供する。
- LLMs によって生成された合成的教師付き微調整データが Verilog のコーディング性能を向上させることを示す。
- モデルサイズとベースモデルが VerilogCoding 能力と SFT の有効性にどう影響するかを調査する。
提案手法
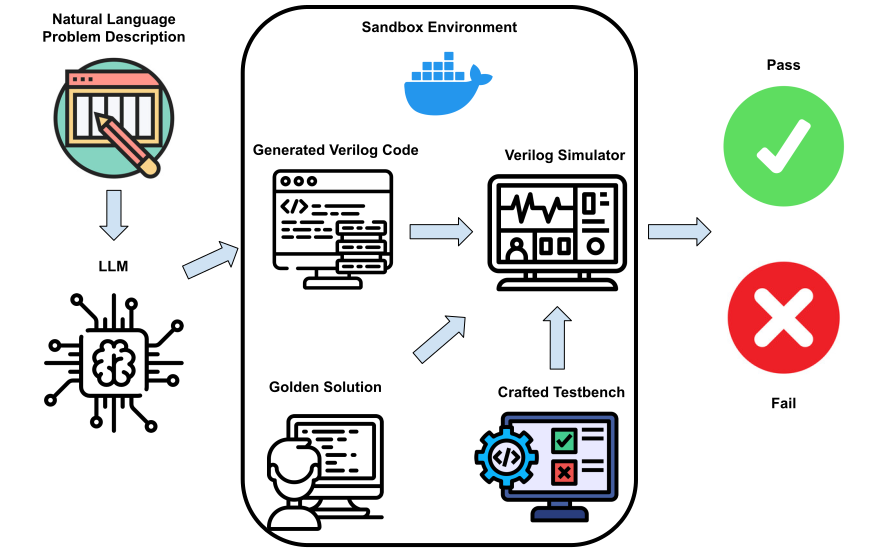
- HumanEval に倣った Verilog コード生成のサンドボックス化評価フレームワークを構築する。
- HDLBits から自己完結モジュールを含む 156 問題の Verilog 評価セットを作成する。
- Docker サンドボックス内の ICARUS Verilog による機能シミュレーションを通じて、金標準解答と自動的に生成された Verilog 補完を評価する。
- GitHub から自己完結モジュールを抽出し、LLMs を用いて説明文を生成し、説明文とコードをペアにした合成的 SFT データを作成する。
- 合成的 SFT データで CodeGen ファミリーモデルをファインチューニングし、pass@k 指標(k は {1,5,10})で評価する。
- GPT-3.5/4 および Verilog に特化したベースモデル(codegen-nl, codegen-multi, codegen-Verilog)間で性能を比較し、データ品質の影響を分析する。
実験結果
リサーチクエスチョン
- RQ1LLM は 多様なタスクに対して自然言語の説明から正しい Verilog コードを信頼性高く生成できるか。
- RQ2サンドボックス化された自動化テストワークフローは Verilog ソリューションの機能的正確性と相関するか。
- RQ3synthetic SFT データは LLM を微調整した際に Verilog コード生成をどの程度改善できるか。
- RQ4モデルサイズとベースモデル選択が VerilogEval のパフォーマンスにどう影響するか。
- RQ5SFT データ品質が下流の Verilog コーディング性能に及ぼす影響はどの程度か。
主な発見
- VerilogEval は 金標準解答に対する自動シミュレーションを通じて機能的正確性を測定できることを示す。
- より大きく、より機能的なモデルは一般に Verilog コーディング性能を向上させる。
- 合成的 SFT データは Verilog 学習モデルおよび一部の多言語ベースモデルの下流の Verilog 性能を改善し、VerilogEval マシンの結果で特筆すべき向上を示す。
- SFT データの品質は重要で、問題コードペアの不正確さを導入すると性能が低下することがわかり、合成データの高品質さの重要性が強調される。
- GPT-4 はいくつかの構成で GPT-3.5 より pass@1、pass@5、pass@10 のスコアが高く、Verilog に特化した SFT はいくつかのベースラインで GPT-3.5 の性能に近づくことがある。
- SFT にはトレードオフがあり、エポック数を増やすと pass@1 は改善する一方で pass@5 および pass@10 が過学習により低下する可能性がある。
![Figure 7: Variance in estimating pass@ k with $n$ . Samples from codegen-16B-verilog [ 12 ] for VerilogEval-human .](https://ar5iv.labs.arxiv.org/html/2309.07544/assets/figs/variance.png)
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。