[論文レビュー] Video Anomaly Detection in 10 Years: A Survey and Outlook
この調査は、深層学習ベースの video anomaly detection (VAD) を含む監視付き、弱教師あり、自己教師あり、教師なしの方法、および vision-language models を含み、データセット、損失、将来の方向性について論じます。
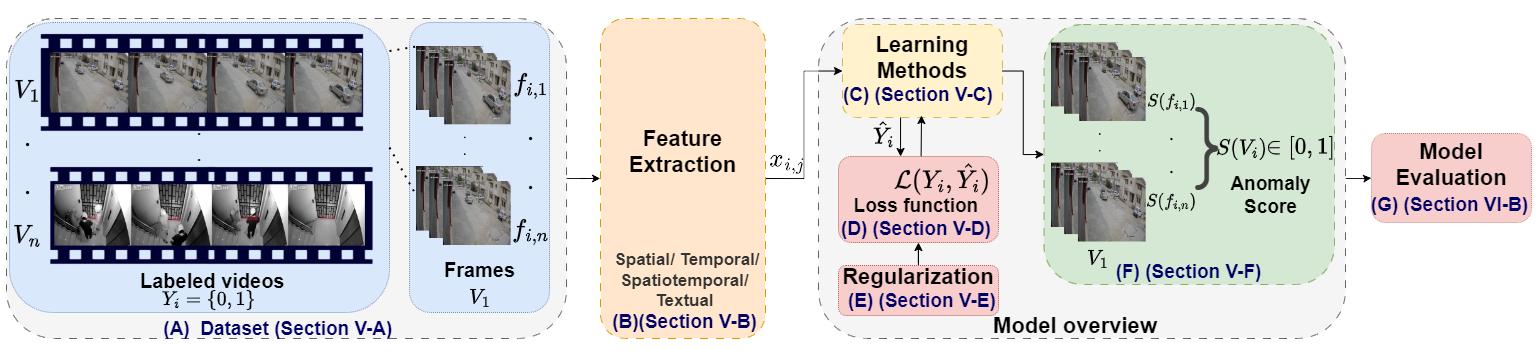
Video anomaly detection (VAD) holds immense importance across diverse domains such as surveillance, healthcare, and environmental monitoring. While numerous surveys focus on conventional VAD methods, they often lack depth in exploring specific approaches and emerging trends. This survey explores deep learning-based VAD, expanding beyond traditional supervised training paradigms to encompass emerging weakly supervised, self-supervised, and unsupervised approaches. A prominent feature of this review is the investigation of core challenges within the VAD paradigms including large-scale datasets, features extraction, learning methods, loss functions, regularization, and anomaly score prediction. Moreover, this review also investigates the vision language models (VLMs) as potent feature extractors for VAD. VLMs integrate visual data with textual descriptions or spoken language from videos, enabling a nuanced understanding of scenes crucial for anomaly detection. By addressing these challenges and proposing future research directions, this review aims to foster the development of robust and efficient VAD systems leveraging the capabilities of VLMs for enhanced anomaly detection in complex real-world scenarios. This comprehensive analysis seeks to bridge existing knowledge gaps, provide researchers with valuable insights, and contribute to shaping the future of VAD research.
研究の動機と目的
- モダン VAD のコアな課題を特定する(大規模データセット、特徴抽出、損失関数、正則化、異常スコアの予測を含む)。
- 深層学習アプローチ(supervised, weakly supervised, self-supervised, unsupervised)が VAD の性能に与える影響を評価する。
- VAD の特徴抽出器として vision-language models の潜在能力を探る。
- データセットのベンチマークを統合し、将来の VAD 研究と実践を導く推奨を提供する。
提案手法
- 過去10年間のトップクラスの computer vision ア venues(CVPR, ICCV, ECCV, TPAMI, IJCV, CVIU)からの文献を系統的にレビュー。
- 方法を supervised、unsupervised、self-supervised、weakly supervised のカテゴリに分類。
- データセット、特徴抽出技術(空間的、時間的、空間時間的、テキスト的)、および損失/正則化スキームを分析。
- ベンチマークデータセット上の最先端モデルを定性的・定量的に評価して長所と短所を特定。
- VAD の特徴抽出器としての vision-language models(VLMs)の活用と性能への影響について議論。
- 堅牢な VAD システムの実現に向けた将来の方向性と推奨を提案。
![Figure 1: Performance improvement from 2017 until 2023 on two popular benchmarks. Performance is measured by the area under the ROC curve (AUC%). Note that some of the models were developed before the datasets were created but were used after the creation by other researchers such as [ 15 , 16 ] . T](https://ar5iv.labs.arxiv.org/html/2405.19387/assets/Figures/introchart.png)
実験結果
リサーチクエスチョン
- RQ1動画異常検知に用いられる深層学習の主流パラダイム(supervised、weakly supervised、self-supervised、unsupervised)は何か、そしてそれらはどのように比較されるか?
- RQ2特徴抽出の選択肢(空間、時間、空間時間、テキスト)と損失関数は VAD の性能にどのような影響を与えるか?
- RQ3VAD における vision-language models の役割は何か、そしてそれらは異常スコアの予測と局在化にどのような影響を与えるか?
- RQ4実世界の VAD の課題を最も適切に捉えるデータセットと評価プロトコルは何か、ベンチマークはどのように進化すべきか?
- RQ5現状の限界(データの多様性、現実性、長期的文脈、マルチモーダルデータ)に対処する将来の方向性は何か?
主な発見
- 深層学習ベースの VAD は過去10年間で性能を大きく向上させ、特に vision-language models からの顕著な改善が見られる。
- データセットは複雑さと現実性に差があり、異常の多様性の不足やクラス不均衡といった課題が強調されている。
- 空間的特徴と時間的特徴の双方が不可欠であり、それらを統合した spatiotemporal 表現が検出と局在化を改善する。
- 弱教師ありおよび教師なしのパラダイムは、アノテーション負担を減らしつつ堅牢な検出を維持するために重要性が増している。
- vision-language の特徴は意味的文脈を補完的に提供し、異常理解とスコア付けを向上させる可能性がある。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。