[論文レビュー] Video-ChatGPT: Towards Detailed Video Understanding via Large Vision and Language Models
Video-ChatGPT は動画に適用した CLIP エンコーダーと Vicuna ベースの LLM を組み合わせ、100k video-instruction ペアで訓練され、詳細なオープンエンドの動画対話を可能にする定量的な動画会話評価フレームワークを導入します。
Conversation agents fueled by Large Language Models (LLMs) are providing a new way to interact with visual data. While there have been initial attempts for image-based conversation models, this work addresses the under-explored field of \emph{video-based conversation} by introducing Video-ChatGPT. It is a multimodal model that merges a video-adapted visual encoder with an LLM. The resulting model is capable of understanding and generating detailed conversations about videos. We introduce a new dataset of 100,000 video-instruction pairs used to train Video-ChatGPT acquired via manual and semi-automated pipeline that is easily scalable and robust to label noise. We also develop a quantitative evaluation framework for video-based dialogue models to objectively analyze the strengths and weaknesses of video-based dialogue models. Code: https://github.com/mbzuai-oryx/Video-ChatGPT.
研究の動機と目的
- 動画を超えるオープンエンドで一貫性のある動画に関する会話を動機づける。
- 動画向けに特化した視覚-言語モデルで時間的・空間的理解を実現する。
- 高品質な動画指示データを生成するスケーラブルなデータ生成フレームワークを提供する。
- 動画ベースの対話能力を定量的に評価するベンチマークフレームワークを提供する。
提案手法
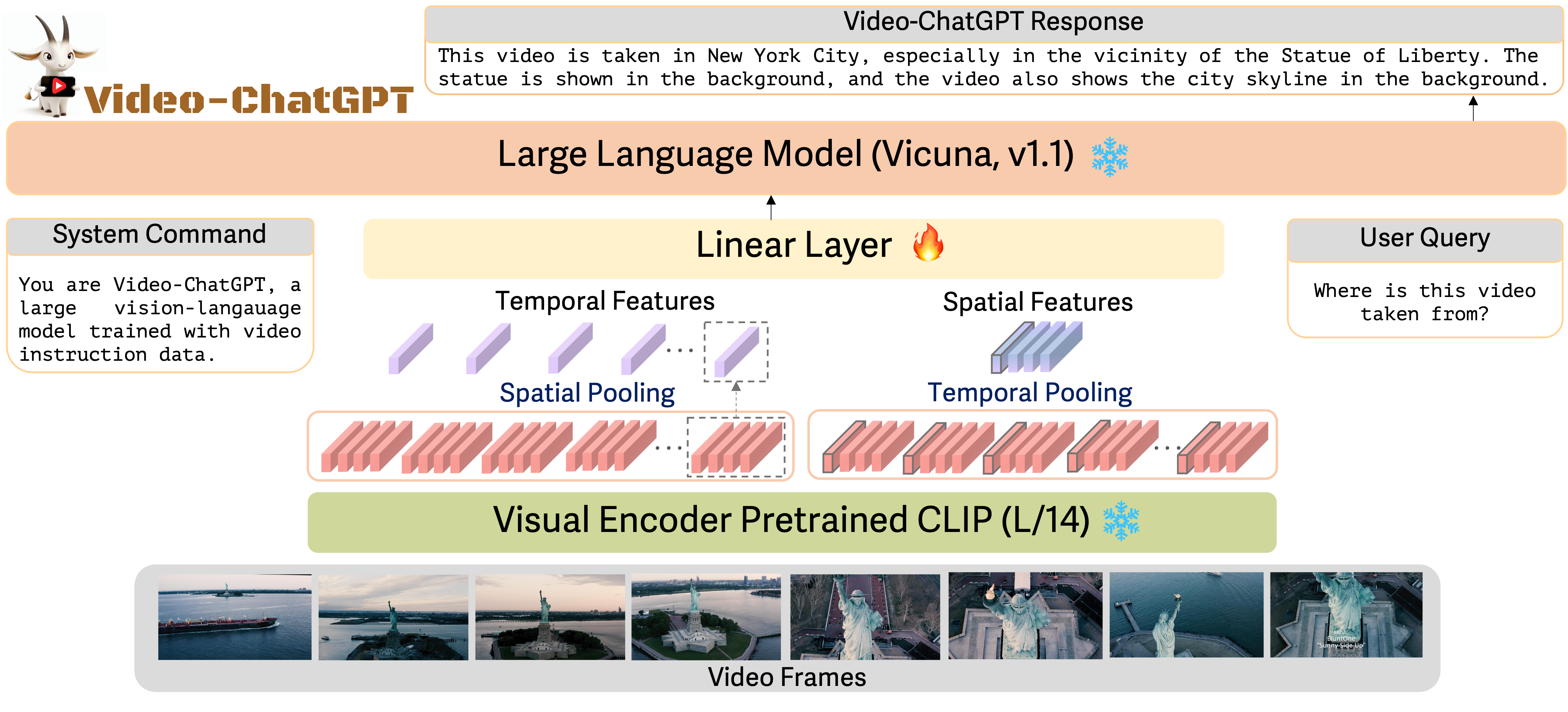
- 視覚エンコーダとして CLIP ViT-L/14 を映像エンコーダとして適応させ、Vicuna を言語デコーダとして使用する動画拡張 VL モデルを設計する。
- ほとんどのバックボーン成分を固定したまま、指示調整を介して 100k video-instruction ペアで作成・微調整する。
- 時空間動画特徴を LLM 入力空間へ投影する単純なアダプタ g を開発する。
- 人間の介在と半自動注釈のハイブリッドなパイプラインを通じて豊富な動画指示データを生成する。
- 正確性、詳細、文脈、時間性、整合性の側面を包含する動画ベースの対話の定量評価フレームワークを提案する。
実験結果
リサーチクエスチョン
- RQ1視覚-言語モデルは時空間動画内容をどれだけ理解し、対話できるのか?
- RQ2凍結されたバックボーンを持つ軽量アダプタは動画ベースの対話性能で競争力を発揮できるのか?
- RQ3高品質な動画特化の指示データがオープンエンドな動画対話に与える影響は?
- RQ4動画ベースの対話モデルの強みと弱みを複数の能力にわたって定量化するにはどうすればよいか?
主な発見
| モデル | MSVD-QA(正答率) | MSVD-QA(スコア) | MSRVTT-QA(正答率) | MSRVTT-QA(スコア) | TGIF-QA(正答率) | TGIF-QA(スコア) | Activity Net-QA(正答率) | Activity Net-QA(スコア) |
|---|---|---|---|---|---|---|---|---|
| FrozenBiLM | 32.2 | – | 16.8 | – | 41.0 | – | 24.7 | – |
| Video Chat | 56.3 | 2.8 | 45.0 | 2.5 | 34.4 | 2.3 | 26.5 | 2.2 |
| Video-ChatGPT | 64.9 | 3.3 | 49.3 | 2.8 | 51.4 | 3.0 | 35.2 | 2.7 |
- Video-ChatGPT は他のモデルと比較した複数データセットでゼロショット QA の性能が競合的である。
- MSVD-QA、MSRVTT-QA、TGIF-QA、ActivityNet-QA で Video-ChatGPT は Video Chat および FrozenBiLM のベースラインより高い精度/スコアを達成。
- 動画データでの指示調整により、モデルは強い時系列理解と文脈認識のある応答を示す。
- 100k の video-instruction データセットは人間支援と半自動注釈を組み合わせ、動画特有の理解と対話能力を高める。
- 本論文は動画ベースの対話モデルをベンチマークする初の定量的な動画会話評価フレームワークを導入する。

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。