[論文レビュー] Video Mamba Suite: State Space Model as a Versatile Alternative for Video Understanding
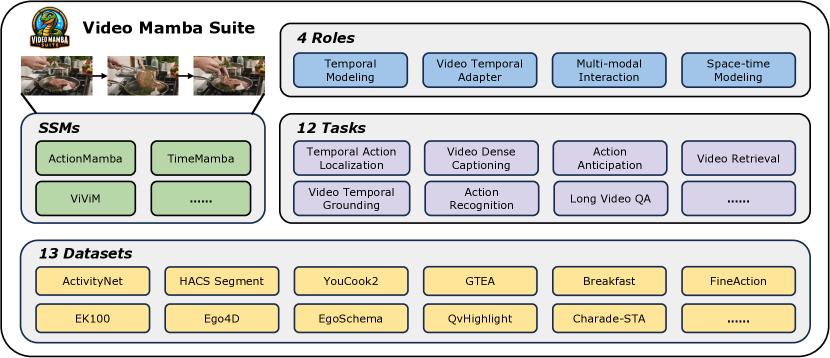
本論文は、状態空間モデル(SSM)、特に Mamba およびその派生を、Transformer の代替として幅広い映像理解タスクに適用可能であると検証し、12タスクにまたがる14モデルの Video Mamba Suite を形成するという点を示している。時間的・跨模態・時空的映像モデリングで競争力のある性能と有利な効率性を示す。
Understanding videos is one of the fundamental directions in computer vision research, with extensive efforts dedicated to exploring various architectures such as RNN, 3D CNN, and Transformers. The newly proposed architecture of state space model, e.g., Mamba, shows promising traits to extend its success in long sequence modeling to video modeling. To assess whether Mamba can be a viable alternative to Transformers in the video understanding domain, in this work, we conduct a comprehensive set of studies, probing different roles Mamba can play in modeling videos, while investigating diverse tasks where Mamba could exhibit superiority. We categorize Mamba into four roles for modeling videos, deriving a Video Mamba Suite composed of 14 models/modules, and evaluating them on 12 video understanding tasks. Our extensive experiments reveal the strong potential of Mamba on both video-only and video-language tasks while showing promising efficiency-performance trade-offs. We hope this work could provide valuable data points and insights for future research on video understanding. Code is public: https://github.com/OpenGVLab/video-mamba-suite.
研究の動機と目的
- Mamba が動画理解のための Transformer の実用的な代替となり得るかを評価する。
- 複数のタスクにわたる14個のSSMベースモデルで Video Mamba Suite を構築・評価する。
- 四つの役割(時系列モデル、時系列モジュール、多モーダル相互作用ネットワーク、時空モデル)における Mamba を分析する。
- 多様な映像データセット上で Mamba 変種を Transformer のベースラインと比較し、長所とトレードオフを明らかにする。
提案手法
- S4、Mamba を含む状態空間モデルを説明し、零次ホールド法を用いた離散化によって Ā と B̄ を得る。
- Mamba、ViM、DBM の4つのブロック変種と、双方向・双方向スキャンのためのアーキテクチャの差異を導入する。
- 時系列局在、セグメンテーション、キャプショニング、アクション予測、クロスモーダルな映像グラウンディングにまたがる12タスク全体で14モジュールからなる Video Mamba Suite を構築する。
- 強力なベースラインの Transformer ブロックを Mamba ブロックに置換し、公正な比較のための競争力のある Mamba ベースモデルを形成する。
- 13の主要データセットで評価し、mAP、精度、BLEU/METEOR/CIDEr/SODA、検索指標などを報告する。
- Flash-attention との推論速度比較およびフレーム長スケーリングを通じて効率性を分析する。
実験結果
リサーチクエスチョン
- RQ1Mamba ベースの SSM は、さまざまな映像理解タスクにおいて Transformer と競合する性能を達成できるか。
- RQ2どの役割(時系列モデリング、時系列モジュール、多モーダル相互作用、時空モデリング)が映像タスクで Mamba を最も有効に活用するか。
- RQ3長い映像シーケンスに対して、Mamba の派生は効率性能の有利なトレードオフを提供するか。
- RQ4時間的グラウンディングと多モーダルタスクにおける Mamba ベースのクロスモーダルモデルは、Transformer ベースのベースラインと比較してどうか。
- RQ5双方向スキャンと一方向スキャン、および分解ブロック設計が性能に与える影響は何か。
主な発見
- Mamba ベースのモデルは Video Mamba Suite の時間的アクションローカリゼーションおよびセグメンテーションでしばしば Transformer ベースラインを上回る。
- DBM ブロックを用いた ActionMamba は HACS Segment で平均 mAP が Transformer 相当より高く(44.56 対 43.34)。
- 密な映像キャプショニングでは、DBM(私たちの案)は ActivityNet と YouCook2 でベースラインより METEOR および CIDEr を改善する。
- DBM を用いたクロスモーダル UniVTG は QvHighlight および Charade-STA データセットで Transformer UniVTG より平均 mAP が高い。
- TimeMamba は、Ego4D で事前学習した場合、Epic-Kitchens-100 でゼロショットのマルチインスタンス検索とアクション認識で一般に TimeSformer を上回る。
- ViViM ベースの時空モデリングは ViT 系統よりゼロショット検索の利得が大きく、長いシーケンスの映像タスクに有効であることを示す。
![Figure 2 : Illustration of three SSMs blocks. (a) is the vanilla Mamba block [ 30 ] . (b) is the ViM block [ 96 ] . (c) is our proposed DBM block, which separates the input projector and shares the parameters of SSM in both scanning directions.](https://ar5iv.labs.arxiv.org/html/2403.09626/assets/x2.png)
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。