[論文レビュー] VideoCrafter1: Open Diffusion Models for High-Quality Video Generation
VideoCrafter1 は高品質なビデオ生成のための2つのオープンソース拡散モデルを提示します:テキストからビデオへ (T2V) モデルは映画的解像度の動画を生成し、画像からビデオへ (I2V) モデルは与えられた画像の内容を保持しつつアニメーション化します。
Video generation has increasingly gained interest in both academia and industry. Although commercial tools can generate plausible videos, there is a limited number of open-source models available for researchers and engineers. In this work, we introduce two diffusion models for high-quality video generation, namely text-to-video (T2V) and image-to-video (I2V) models. T2V models synthesize a video based on a given text input, while I2V models incorporate an additional image input. Our proposed T2V model can generate realistic and cinematic-quality videos with a resolution of $1024 imes 576$, outperforming other open-source T2V models in terms of quality. The I2V model is designed to produce videos that strictly adhere to the content of the provided reference image, preserving its content, structure, and style. This model is the first open-source I2V foundation model capable of transforming a given image into a video clip while maintaining content preservation constraints. We believe that these open-source video generation models will contribute significantly to the technological advancements within the community.
研究の動機と目的
- オープンソースのビデオ生成を高品質なテキストからビデオへの合成で前進させる
- 入力内容と構造を保持する画像条件付きビデオ生成を可能にする
- 一貫性のある動画のための時間的注意機構を伴う潜在空間拡散技術を調査する
- 高解像度ビデオ生成をサポートするトレーニング戦略とデータセットを提供する
- コミュニティの採用と評価を促進するツールとベンチマークを提供する
提案手法
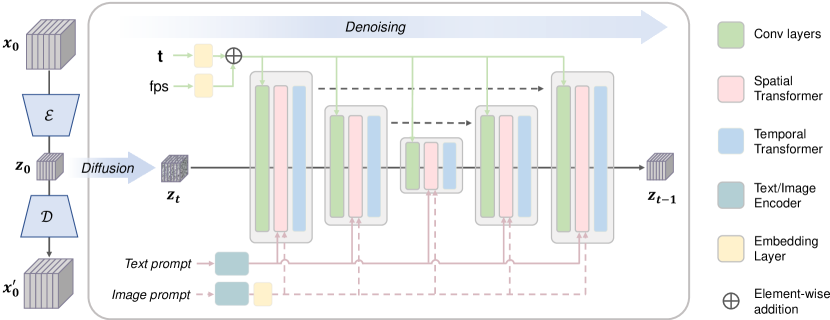
- 潜在空間で動作するビデオ VAE とビデオ拡散モデルを組み合わせた Latent Video Diffusion Model (LVDM) を構築する
- 3D デノイジング U-Net に時間的アテンション層を組み込み時間的一貫性を確保する
- テキストプロンプトを用いたクロスアテンションによる意味的制御を注入する;動作速度を制御する FPS/時間埋め込みを使用する
- I2V の場合、CLIP の画像エンコーダーからリッチな画像埋め込みを抽出し、テキスト埋め込みとデュアルクロスアテンションで融合する
- 256×256 から 1024×576 への段階的解像度戦略で大規模な画像・動画データセット上で T2V を学習する
- 画像埋込みを拡散モデルのクロスアテンション空間に整合させるオープンソースの I2V マッピングを開発する

実験結果
リサーチクエスチョン
- RQ1オープンソースの拡散モデルは高品質で映画的解像度の T2V 動画生成をどのように達成できるか?
- RQ2オープンソースの I2V モデルは参照画像の内容と構造を忠実に保持しつつ動きを可能にできるか?
- RQ3時間的一貫性と動作の大きさを改善する建築とトレーニング戦略は何か?
- RQ4画像条件付きトークンは画像-to-video 条件付けにおけるグローバルな意味トークンとどのように比較されるか?
- RQ5オープンソース環境で堅牢な高解像度ビデオ生成を可能にするデータセットとトレーニングレジームは何か?
主な発見
- T2V モデルはオープンソースのフレームワークで高い視覚品質と高解像度ビデオ生成を実現する
- I2V モデルは入力画像の内容と構造を保持しつつアニメーションを可能にするよう設計されている
- 豊富な画像埋め込み(全 CLIP パッチトークン)は画像条件付きビデオ生成におけるグローバルな意味トークンより忠実度を向上させる
- デュアルクロスアテンションはテキストと画像入力を I2V 生成に統合する際、追加パラメータを最小限に抑えて実現する
- 時間的アテンションを備えた潜在空間拡散は一部のベースラインより時間的一貫性と動作ダイナミクスを改善する
- オープンソースモデルは商用の対訳と比較していくつかの評価要素で競争力があり、持続時間と動作のリアリズムにはさらなる改善余地がある
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。