[論文レビュー] VideoFusion: Decomposed Diffusion Models for High-Quality Video Generation
VideoFusionはフレーム間で共有される基底ノイズを用い、時間とともに変化する残差ノイズを用いる分解拡散プロセスを導入する。これにより、事前学習済みの画像拡散モデルを基盤ジェネレータとして利用でき、複数データセットにおいて最先端の結果を達成する。
A diffusion probabilistic model (DPM), which constructs a forward diffusion process by gradually adding noise to data points and learns the reverse denoising process to generate new samples, has been shown to handle complex data distribution. Despite its recent success in image synthesis, applying DPMs to video generation is still challenging due to high-dimensional data spaces. Previous methods usually adopt a standard diffusion process, where frames in the same video clip are destroyed with independent noises, ignoring the content redundancy and temporal correlation. This work presents a decomposed diffusion process via resolving the per-frame noise into a base noise that is shared among all frames and a residual noise that varies along the time axis. The denoising pipeline employs two jointly-learned networks to match the noise decomposition accordingly. Experiments on various datasets confirm that our approach, termed as VideoFusion, surpasses both GAN-based and diffusion-based alternatives in high-quality video generation. We further show that our decomposed formulation can benefit from pre-trained image diffusion models and well-support text-conditioned video creation.
研究の動機と目的
- Diffusionモデルを用いたビデオ生成を改善する動機づけとして、ビデオフレームの時間的冗長性を活用する。
- 各フレームのノイズを共有基底ノイズと時間依存の残差ノイズに分割する拡散プロセスを提案する。
- 事前学習済みの画像拡散モデルを基盤ジェネレータとして活用し、ビデオ合成への強い画像 priors を注入する。
- フレーム指数およびテキスト/条件 cue に条件づけられたフレーム毎の残差をモデル化する残差ジェネレータを開発する。
- 生成ビデオの内容と動きの制御、効率性とスケーラビリティの利点を示し、内容対運動の要因を分析する。
提案手法
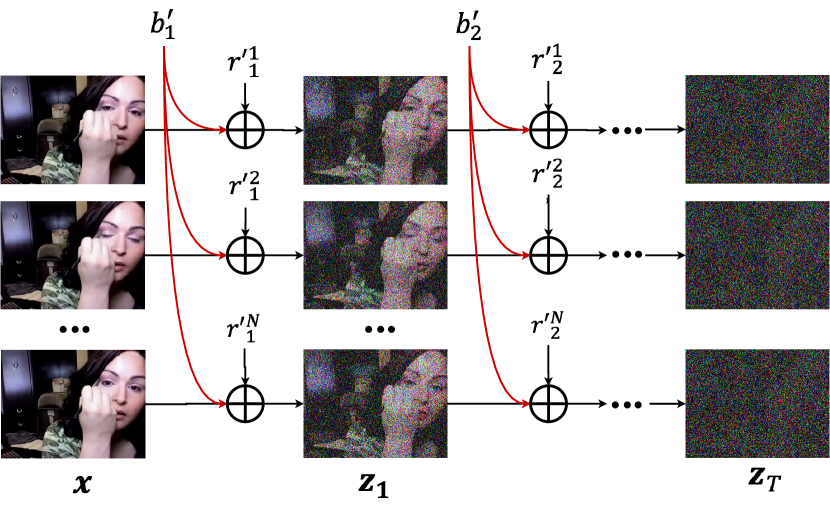
- 各フレームデータ x^i を共有基底 x^0 と残差 Delta x^i に分解し、x^i = sqrt(lambda^i) x^0 + sqrt(1 - lambda^i) Delta x^i と表現する。
- 拡散ノイズ ε_t^i をフレーム間で共有基底ノイズ b_t と残差ノイズ r_t^i に分割し、z_t^i を x^0 の拡散と Delta x^i の拡散の和として表現できるようにする。
- 基底ノイズ b_t を全フレームで共有し、b_t によって z_t^i が相関を持つようにすることで、デノイジングネットワークが整合したビデオを再構成する負担を軽減する。
- 事前学習済み画像DPMを基盤ジェネレータとして用い、単一フレームから base noise z_φ^b(z^{floor(N/2)}_t, t) を推定し、残差ジェネレータ z_ψ^r によりフレーム特有の残差ノイズを推定する。
- 基盤ジェネレータを floor(N/2) に対して停止勾配を設定しつつ共同訓練を行い、画像 priors を保持しつつビデオデータへの微調整を可能にする。
- DDIM/DDPM サンプリングを二段階で採用し、最初に基底ノイズを除去し、次に残差ノイズを推定して次の潜在ステップを生成する。
![Figure 2 : Comparison between images generated from (a) independent noises; (b) noises with a shared base noise. Images of the same row are generated by the decoder of DALL-E 2 [ 25 ] with the same condition.](https://ar5iv.labs.arxiv.org/html/2303.08320/assets/x2.png)
実験結果
リサーチクエスチョン
- RQ1拡散ノイズを共有基底成分とフレーム特有の残差成分に分解することは、ビデオ拡散モデルの時間的一貫性を改善するか?
- RQ2事前学習済みの画像拡散モデルを基盤ジェネレータとして活用することで、ビデオ合成品質と効率性が高まる強い priors が得られるか?
- RQ3lambda^i(各フレームの基底ノイズの共有比率)をどのように選択し、内容保持と動作ダイナミクスのバランスを取るべきか?
- RQ4基盤ジェネレータと残差ジェネレータの共同微調整は、ビデオ生成性能にどのような影響を与えるか?
- RQ5長いシーケンスや高解像度でも一貫性と品質を維持できるか?
主な発見
- VideoFusion は複数データセットで最先端の結果を達成し、16×64×64 および 16×128×128 解像度で FVD および IS 指標でGANベースおよび拡散ベースのベースラインを上回る。
- UCF101(無条件、16×64×64):VideoFusion は IS 71.67 および FVD 139 を達成し、16×128×128 では IS 72.22 および FVD 220。
- Sky Time-lapse で FVD 47.0 および KVD 5.3; TaiChi-HD で FVD 56.4 および KVD 6.9。
- 共有基底ノイズと大規模な事前学習済み基盤ジェネレータによる効果により、VDM再実装と比べてメモリ使用量を約21.8%低減、待機遅延を約57.5%短縮。
- アブレーション研究では lambda^i パラメータが性能に決定的な影響を与え、中程度の値(例:0.5)で IS/FVD が小さすぎるまたは大きすぎる場合よりも良く、基盤ジェネレータと残差ジェネレータの共同微調整は結果を向上させる。
- 長尺シーケンス生成(512フレーム)では、基盤ノイズを一定に保ちつつ残差ノイズを変化させることで、品質と一貫性を維持できる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。