[論文レビュー] VideoMAE V2: Scaling Video Masked Autoencoders with Dual Masking
VideoMAE V2 はデュアルマスキングと進行的トレーニングを導入し、ビデオマスク付き自己符号化器を十億パラメータの ViT にスケールさせ、アクション認識、検出、時系列局所化の分野で最先端の成果を達成する。
Scale is the primary factor for building a powerful foundation model that could well generalize to a variety of downstream tasks. However, it is still challenging to train video foundation models with billions of parameters. This paper shows that video masked autoencoder (VideoMAE) is a scalable and general self-supervised pre-trainer for building video foundation models. We scale the VideoMAE in both model and data with a core design. Specifically, we present a dual masking strategy for efficient pre-training, with an encoder operating on a subset of video tokens and a decoder processing another subset of video tokens. Although VideoMAE is very efficient due to high masking ratio in encoder, masking decoder can still further reduce the overall computational cost. This enables the efficient pre-training of billion-level models in video. We also use a progressive training paradigm that involves an initial pre-training on a diverse multi-sourced unlabeled dataset, followed by a post-pre-training on a mixed labeled dataset. Finally, we successfully train a video ViT model with a billion parameters, which achieves a new state-of-the-art performance on the datasets of Kinetics (90.0% on K400 and 89.9% on K600) and Something-Something (68.7% on V1 and 77.0% on V2). In addition, we extensively verify the pre-trained video ViT models on a variety of downstream tasks, demonstrating its effectiveness as a general video representation learner. The code and model is available at \url{https://github.com/OpenGVLab/VideoMAEv2}.
研究の動機と目的
- 様々なタスクへ汎化するためのビデオ基盤モデルのスケーラブルな自己教師付き事前学習を推進する。
- 総パラメータが十億級のビデオトランスフォーマーを効率的に事前学習できるデュアルマスキング方式を開発する。
- 大規模な事前学習を支援するため、百万レベルのラベルなしおよび混合ラベル付きビデオデータを収集する。
- 自己教師付き事前学習を含む進行的トレーニングパイプラインを用い、その後監視付きポスト事前学習を行う。
- VideoMAE V2 の表現が複数の下流ビデオタスクへ転移可能であることを示す。
提案手法
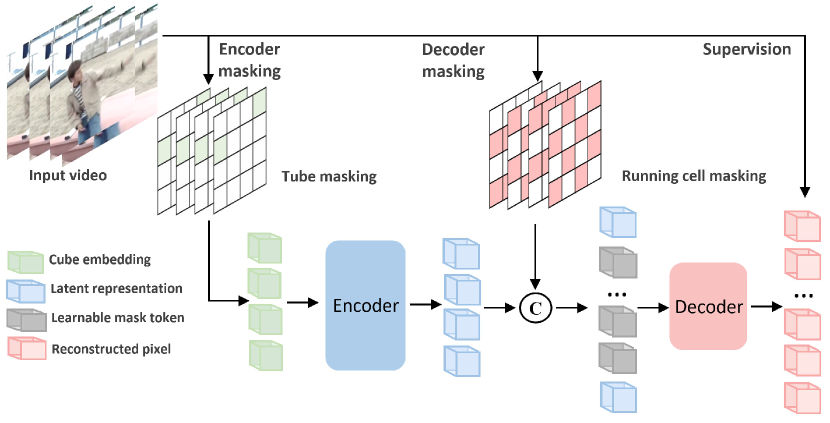
- 高比率のエンコーダマスクとデコーダ入力長を削減するデコーダマスクを組み合わせたデュアルマスキング戦略を採用する。
- デコーダで可視トークンの一部のみを再構成する軽量デコーダを使用する。
- エンコーダで可視なトークンからの情報漏えいを防ぎつつ、デコーダ可視トークンに対して平均二乗誤差再構成損失で訓練する。
- 巨大な ViT バックボーン(例: ViT-g)を用いてモデル容量を拡張し、百万レベルのラベルなしビデオデータセットで事前学習データを多様化する。
- UnlabeledHybrid での自己教師付き事前学習、LabeledHybrid での監視付きポスト事前学習、次にタスク固有の微調整という進行的トレーニングパイプラインを構築する。
- 混在する多源のラベルなしデータセットとラベル付きデータセットを収集・活用して、十億レベルの事前学習とタスク間転移を支える。
実験結果
リサーチクエスチョン
- RQ1VideoMAE スタイルのマスク済み自己符号化を十億パラメータ級のビデオトランスフォーマーへ効果的にスケールさせることができるか?
- RQ2デュアルマスキング(エンコーダとデコーダ)は表現品質を損なうことなく訓練効率を大幅に向上させるか?
- RQ3データの規模と多様性が大規模なビデオマスク事前学習の性能にどのように影響するか?
- RQ4ハイブリッドラベル付きデータセットでの進行的な監視付きファインチューニングは、大規模な事前学習データと小規模な下流データセットとのギャップを埋められるか?
- RQ5VideoMAE V2 の表現は広範なベンチマークにおけるアクション認識、空間的および時系列アクション検出へどの程度転移するか?
主な発見
- VideoMAE V2 は十億パラメータのビデオトランスフォーマー(ViT-g)を訓練することに成功した。
- デュアルマスキングは FLOPs とメモリを削減し、エンコーダーのみのマスキングと比べて精度を維持または向上させる。
- 百万レベルのラベルなしハイブリッドビデオデータセットでの事前学習と、0.66Mクリップ、710カテゴリのラベル付きハイブリッドデータセットでのポスト事前学習は強力な下流性能をもたらす。
- VideoMAE V2 はKinetics-400 (90.0%)、Kinetics-600 (89.9%)、Something-Something V1/V2 (68.7%、77.0%) で新たな SOTA を達成し、AVA および時系列アクションデータセットでも高い結果を示す。
- 進行的な事前学習とデータの多様化は過学習を抑制し、アクション認識および検出のベンチマーク全体で下流タスクへの転移を改善する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。