[論文レビュー] VideoPrism: A Foundational Visual Encoder for Video Understanding
VideoPrism は、大量の高品質キャプションとノイズの多いテキストの混合で事前学習された汎用の凍結ビデオエンコーダで、分類、局在、検索、キャプション生成、QA などのほとんどのビデオ理解ベンチマークで最先端の成果を達成します。
We introduce VideoPrism, a general-purpose video encoder that tackles diverse video understanding tasks with a single frozen model. We pretrain VideoPrism on a heterogeneous corpus containing 36M high-quality video-caption pairs and 582M video clips with noisy parallel text (e.g., ASR transcripts). The pretraining approach improves upon masked autoencoding by global-local distillation of semantic video embeddings and a token shuffling scheme, enabling VideoPrism to focus primarily on the video modality while leveraging the invaluable text associated with videos. We extensively test VideoPrism on four broad groups of video understanding tasks, from web video question answering to CV for science, achieving state-of-the-art performance on 31 out of 33 video understanding benchmarks. Our models are released at https://github.com/google-deepmind/videoprism.
研究の動機と目的
- 外観とモーション理解のバランスを取る、真に基盤的なビデオモデルの必要性を動機づける。
- ビデオ-テキスト対とビデオのみデータを活用した2段階の事前学習戦略を提案する。
- 凍結されたビデオエンコーダが、最小限のタスク特化適応で多様なタスクにおいて最先端の結果を達成できることを実証する。
- 一般的なビデオタスクと科学CV領域での VideoPrism の有効性を示し、広い汎用性を示す。
提案手法
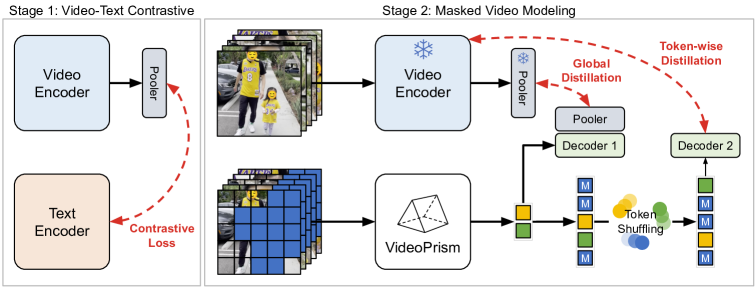
- 二段階の事前学習: Stage 1 は video-text contrastive 学習を通じて意味的なビデオ埋め込みを学習します。
- Stage 2 は video-only データでの改善された masked video modeling をグローバル-ローカル蒸留とともに実行します。
- masked modeling のデコードショートカットを防ぐトークンシャッフル方式を導入します。
- 第一段階の埋め込みのグローバル蒸留を使用して破局的忘却を緩和します。
- 空間-時間分解を伴う Vision Transformer ベースのアーキテクチャで、空間エンコーダの後にグローバルプーリングを行わない。
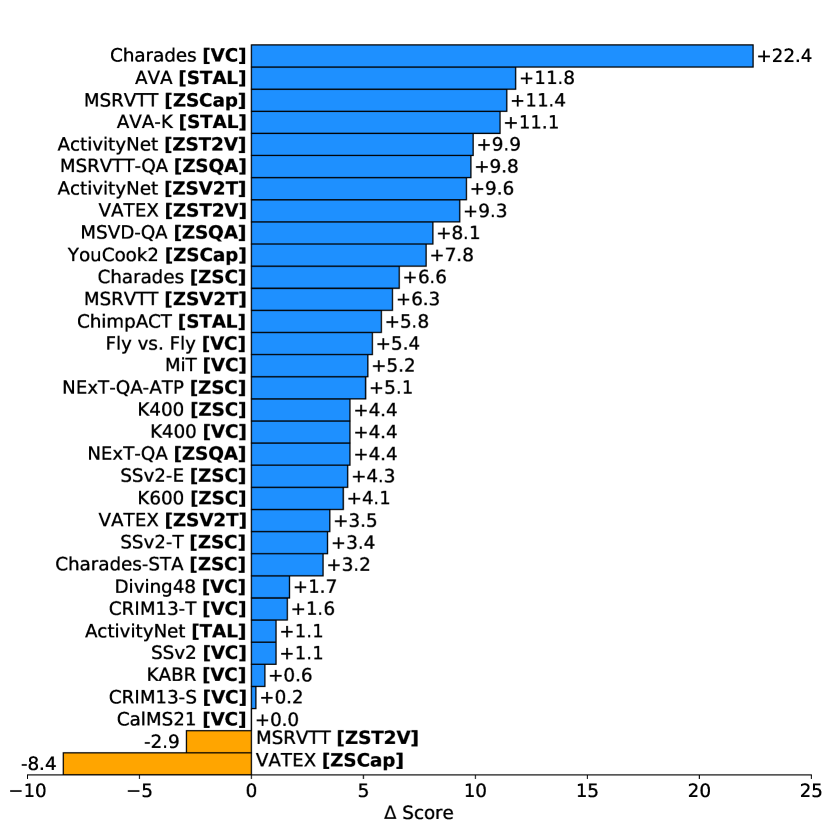
実験結果
リサーチクエスチョン
- RQ1異種の video-text データと video-only データで訓練された単一の凍結ビデオエンコーダが、広範なビデオ理解タスクで最先端の性能を達成できるか?
- RQ2グローバル-ローカル蒸留とトークンシャッフルを伴う二段階の事前学習アプローチは、動画の動作と外観の理解を向上させるか?
- RQ3タスク固有の微調整なしで、ゼロショットの video-text 検索、キャプション生成、QA、科学分野のデータセットにどれだけ一般化できるか?
- RQ4エンコーダを凍結し、タスクヘッドのみを訓練するだけで、多様なベンチマークで競争力のある結果を得られるか?
主な発見
- VideoPrism は 4 つのタスク群にわたる 33 件中 30 件のビデオ理解ベンチマークで最先端の性能を達成します。
- Frozen VideoPrism バリアント(B および g)は VideoGLUE 相当のベンチマークおよびゼロショットタスクで一貫してベースラインを上回ります。
- グローバル-ローカル蒸留とトークンシャッフルを備えた二段階の事前学習は大幅な利得を生み、特に SSv2 のような動き中心のデータセットで顕著です。
- ゼロショットの video-text 検索と分類は新記録を達成し、しばしばより大規模または追加モダリティを持つマルチモーダルモデルを凌ぐ。
- VideoPrism は CV-for-science データセットへの強い汎化を示し、特に base-scale および large-scale バリアントでドメイン特化モデルを頻繁に上回します。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。