[論文レビュー] VioLA: Unified Codec Language Models for Speech Recognition, Synthesis, and Translation
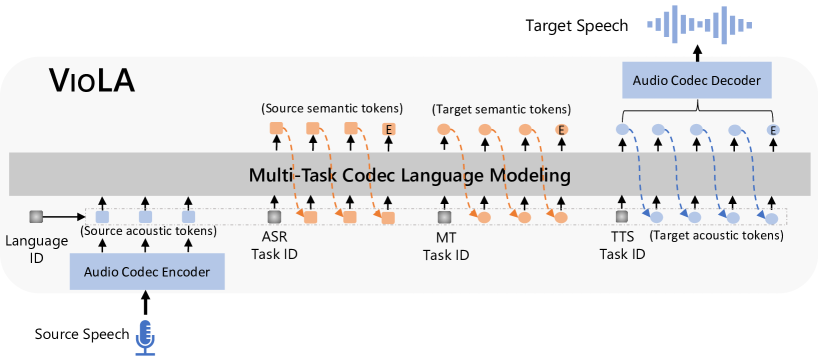
VioLA は、音声とテキストのタスクを統合するデコーダーのみの Transformer であり、音声を離散コデックトークンに変換し、タスクIDと言語IDを用いた多タスク学習で ASR、MT、TTS、S2TT、S2ST を実現します。
Recent research shows a big convergence in model architecture, training objectives, and inference methods across various tasks for different modalities. In this paper, we propose VioLA, a single auto-regressive Transformer decoder-only network that unifies various cross-modal tasks involving speech and text, such as speech-to-text, text-to-text, text-to-speech, and speech-to-speech tasks, as a conditional codec language model task via multi-task learning framework. To accomplish this, we first convert all the speech utterances to discrete tokens (similar to the textual data) using an offline neural codec encoder. In such a way, all these tasks are converted to token-based sequence conversion problems, which can be naturally handled with one conditional language model. We further integrate task IDs (TID) and language IDs (LID) into the proposed model to enhance the modeling capability of handling different languages and tasks. Experimental results demonstrate that the proposed VioLA model can support both single-modal and cross-modal tasks well, and the decoder-only model achieves a comparable and even better performance than the strong baselines.
研究の動機と目的
- 単一のデコーダーのみモデルで、音声とテキストのタスクを跨ぐモダリティをカバーする動機付け。
- 音声信号を離散コデックトークンに変換して、すべてのタスクをトークン列問題として扱う。
- タスクIDと言語IDを組み込み、言語とタスクを区別する。
- 統一されたデコーダが複数の音声タスクで強力なベースラインと同等以上を達成できることを示す。
提案手法
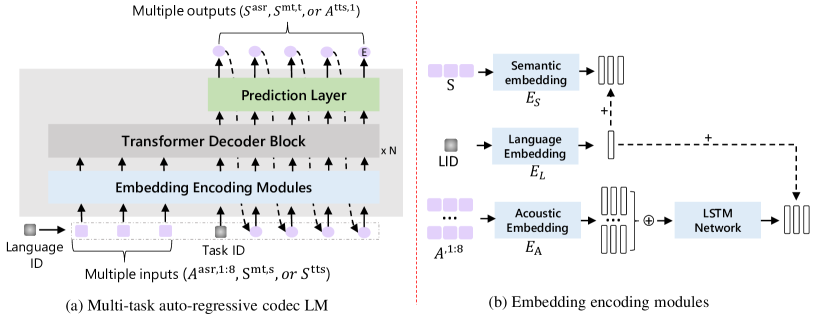
- コアネットワークとして自回帰型コデック Transformer 言語モデルを使用する。
- 音声は EnCodec を介して 8-layer の音響トークン列に、テキストは音素列に変換する。
- 事前ネット embedding モジュールと Transformer デコーダを通じて意味的トークンと音響トークンを融合する。
- ASR、MT、TTS のマルチタスク目的で p(y|x,θ) を最大化して訓練する。
- タスクIDと言語IDを組み込み、タスクと言語に条件を付けてモデルを導く。
- TTS の場合、VALL-E X のように全層音響トークンを生成するため非自回帰コデック LM を採用する。
実験結果
リサーチクエスチョン
- RQ1単一のデコーダーのみモデルは、コデックベースの枠組みで ASR、MT、TTS、クロスモーダル翻訳を実行できるのか?
- RQ2音声を離散コデックトークンとしてエンコードすることは、複数の音声タスクにわたるトークンベースの系列モデリングを可能にするのか?
- RQ3モデルサイズと音響コード層の層構成がタスク間の性能に与える影響は?
- RQ4タスクIDと言語IDは言語横断・タスク横断の能力にどのように影響するのか?
主な発見
- VioLA (18L) は WMT2020 MT で BLEU 56.97 を達成、AED ベースラインと同程度のパラメータ数。
- ASR では、VioLA(18層)は PER 11.36 を達成し、AED の性能に近づき、いくつかのデコーダーのみのベースラインを上回る。
- S2TT では、コデックベースのカスケード LM と VioLA を組み合わせたモデルが BLEU 55.70–55.85、Fbank ベースのカスケード AED モデルと競合するが、パラメータ数は少ない。
- Zero-shot EN TTS とクロスリンガル TTS は、VALL-E X と比較して話者類似性と自然さが向上し、WER の削減と SN スコアの改善という SAL の改善を示す。
- フレームあたりの音響コード層数を増やすと ASR の性能が大幅に向上し、PERの大幅な低減を達成。
- 埋め込みモジュールに LSTM を組み込むと、ASR および TTS の性能がさらに改善され、デコード品質が向上。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。