[論文レビュー] VISTA3D: A Unified Segmentation Foundation Model For 3D Medical Imaging
VISTA3Dは自動および対話的ブランチを備えた統一的な3D CTセグメンテーション基盤モデルを提案し、ゼロショット性能で最先端を達成し、127クラスに対して11454のCTスキャンで強力な転移学習を示す。
Foundation models for interactive segmentation in 2D natural images and videos have sparked significant interest in building 3D foundation models for medical imaging. However, the domain gaps and clinical use cases for 3D medical imaging require a dedicated model that diverges from existing 2D solutions. Specifically, such foundation models should support a full workflow that can actually reduce human effort. Treating 3D medical images as sequences of 2D slices and reusing interactive 2D foundation models seems straightforward, but 2D annotation is too time-consuming for 3D tasks. Moreover, for large cohort analysis, it's the highly accurate automatic segmentation models that reduce the most human effort. However, these models lack support for interactive corrections and lack zero-shot ability for novel structures, which is a key feature of "foundation". While reusing pre-trained 2D backbones in 3D enhances zero-shot potential, their performance on complex 3D structures still lags behind leading 3D models. To address these issues, we present VISTA3D, Versatile Imaging SegmenTation and Annotation model, that targets to solve all these challenges and requirements with one unified foundation model. VISTA3D is built on top of the well-established 3D segmentation pipeline, and it is the first model to achieve state-of-the-art performance in both 3D automatic (supporting 127 classes) and 3D interactive segmentation, even when compared with top 3D expert models on large and diverse benchmarks. Additionally, VISTA3D's 3D interactive design allows efficient human correction, and a novel 3D supervoxel method that distills 2D pretrained backbones grants VISTA3D top 3D zero-shot performance. We believe the model, recipe, and insights represent a promising step towards a clinically useful 3D foundation model. Code and weights are publicly available at https://github.com/Project-MONAI/VISTA.
研究の動機と目的
- 基礎的な3D CTセグメンテーションモデルを定義し、共通の解剖学的構造をアウトオブザボックスの精度でカバーすること。
- 対話的な Refinement を可能にしてセグメンテーション結果を改善すること。
- 最小の注釈で未知の構造をセグメントできるゼロショット機能を開発すること。
- 新しいクラスへの素早い適応を支持するトレーニングレシピとアーキテクチャを提供すること。
- 大規模なCTデータセットで評価し、タスク固有モデルと比較すること。
提案手法
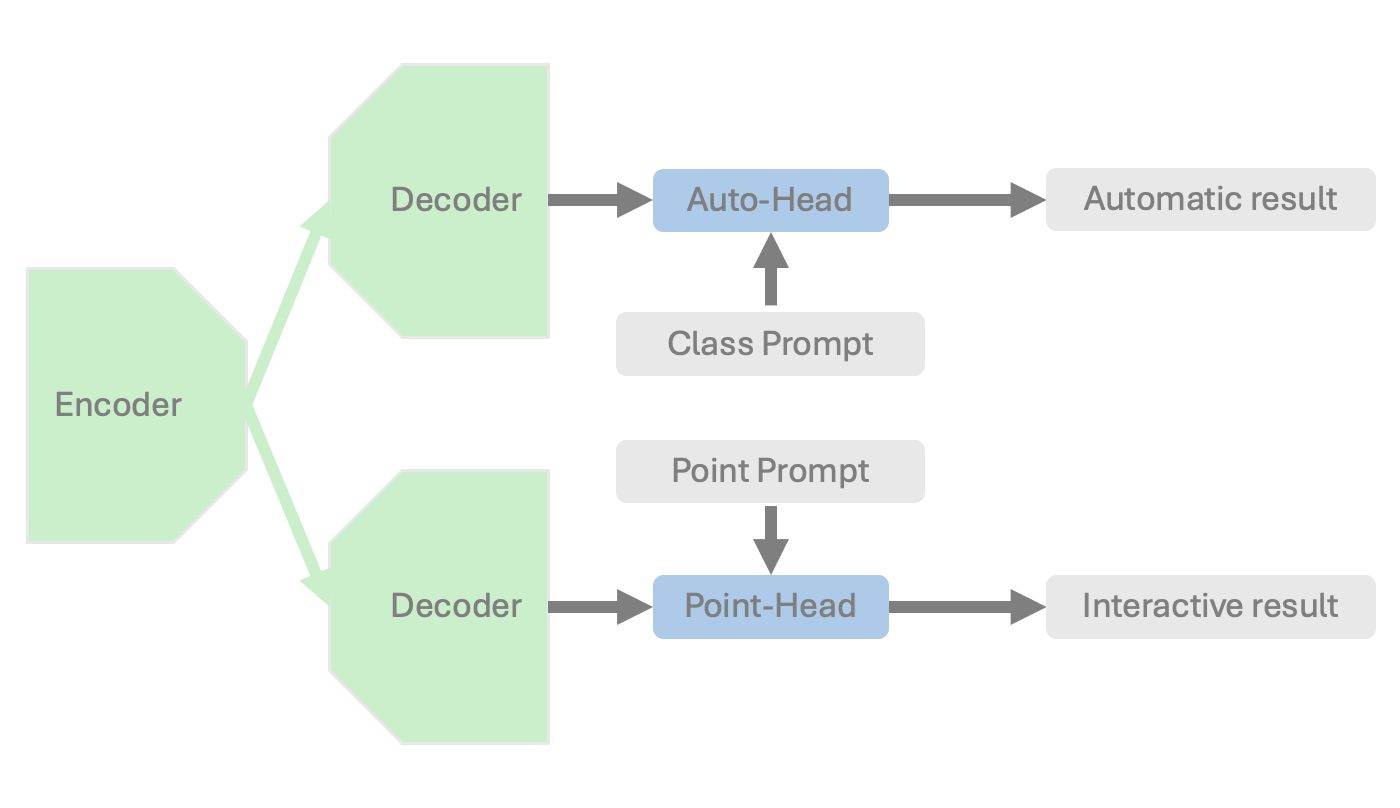
- SegResNetベースの画像エンコーダを共有する二部構成のアーキテクチャ:アウトオブザボックスの1 27クラスのセグメンテーション用自動ヘッドと、3Dポイントプロンプトを受け付ける対話ヘッド。
- 自動ブランチは学習可能なクラス埋め込みとポストマッピング層を用いてクラスごとのセグメンテーションロジットを生成。
- 対話ブランチは3Dに適応したSAMのポイントプロンプトエンコーダを用い、ポイントヘッドで3Dダウンサンプリングとクラス認識ポイント埋め込みを実現。
- トレーニングはマニュアルラベル、TotalSegmentator からの疑似ラベル、SAMから抽出された3Dスーパーボクセルを蒸留してゼロショットセグメンテーションを可能にする4段階のレシピを採用。
- 自動出力と対話出力を統合する際、正しい領域を保持するためのコンポーネントレベルのリファインメント戦略を採用(Alg. 1)。
- データ構築には127クラスを含む11454のCTボリュームを、疑似ラベルとスーパーボクセルで拡張し、3Dパッチベースのトレーニングとスライディングウィンドウ推論を適用。
実験結果
リサーチクエスチョン
- RQ1単一の3D CTセグメンテーションモデルが多くの臓器・病変に対してアウトオブザボックスの高精度を達成できるか。
- RQ2統一された対話ブランチは3D CTデータで未知のクラスに対する効果的なゼロショットセグメンテーションを実現できるか。
- RQ3疑似ラベルとスーパーボクセルで訓練した二部構成アーキテクチャは手作業ラベル付きのタスク特異モデルと競合する性能を達成できるか。
- RQ4新しいデータセットや異常に適応するためのファイブショット未満の微調整でVISTA3Dはどの程度性能を向上させるか。
主な発見
| Dataset | Auto3dSeg | nnUNet | TotalSegmentator | VISTA3D auto | VISTA3D point | VISTA3D auto+point |
|---|---|---|---|---|---|---|
| MSD03 Hepatic tumor [3] | 0.616 | 0.617 | - | 0.588 | 0.701 | 0.687 |
| MSD06 Lung tumor [3] | 0.562 | 0.554 | - | 0.613 | 0.682 | 0.719 |
| MSD07 Pancreatic tumor [3] | 0.485 | 0.488 | - | 0.324 | 0.603 | 0.638 |
| MSD08 Hepatic tumor [3] | 0.683 | 0.659 | - | 0.682 | 0.733 | 0.757 |
| MSD09 Spleen [3] | 0.965 | 0.967 | 0.966 | 0.952 | 0.938 | 0.954 |
| MSD10 Colon tumor [3] | 0.475 | 0.473 | - | 0.439 | 0.609 | 0.633 |
| Airway [43] | 0.896 | 0.899 | - | 0.852 | 0.819 | 0.867 |
| Bone Lesion | 0.343 | 0.396 | - | 0.491 | 0.536 | 0.585 |
| BTCV-Abdomen [37] | 0.807 | 0.825 | 0.846 | 0.849 | 0.815 | 0.859 |
| BTCV-Cervix [38] | 0.598 | 0.640 | 0.611 | 0.672 | 0.736 | 0.775 |
| VerSe [40] | 0.786 | 0.828 | 0.832 | 0.825 | 0.896 | 0.906 |
| AbdomenCT-1K [5] | 0.934 | 0.939 | 0.921 | 0.935 | 0.903 | 0.940 |
| AMOS22 [21] | 0.854 | 0.854 | 0.824 | 0.841 | 0.785 | 0.856 |
| TotalSegV2 [7] | 0.882 | *0.906 | *0.942 | 0.893 | 0.884 | 0.918 |
| Average | 0.706 | 0.718 | - | 0.711 | 0.760 | 0.792 |
- VISTA3Dはテストデータ上で127クラスに対するアク Automaticなセグメンテーションで競争力を示す。
- 対話ブランチは未知のクラスに対する効果的なゼロショットセグメンテーションを可能にし、ポイントプロンプトを反復的に行うことで性能が向上する。
- いくつかのデータセットにおいて、VISTA3D auto+pointは単一クリックでベースライン手法を上回り、対話的なリファインメント能力が強いことを示す。
- 少数ケース(1〜10例)でのファインチューニングは、マウス微小CTとWORDデータセットでベースラインよりVISTA3Dに高い利益をもたらす。
- ゼロショット結果は対話的、ゼロショットアプローチを用いると外部データセット(マウス臓器および腎上皮腫/肝腫瘍)でのセグメンテーションが改善されることを示す。
- 自動ブランチへ合成データを組み込むと、さまざまな構造に対する頑健性がさらに向上する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。