[論文レビュー] Visual Attention Methods in Deep Learning: An In-Depth Survey
このサーベイは視覚領域の50のディープラーニングアテンション技術を網羅的にレビューし、それらをカテゴリ分けし、構成要素、長所と制限を議論する。
Inspired by the human cognitive system, attention is a mechanism that imitates the human cognitive awareness about specific information, amplifying critical details to focus more on the essential aspects of data. Deep learning has employed attention to boost performance for many applications. Interestingly, the same attention design can suit processing different data modalities and can easily be incorporated into large networks. Furthermore, multiple complementary attention mechanisms can be incorporated into one network. Hence, attention techniques have become extremely attractive. However, the literature lacks a comprehensive survey on attention techniques to guide researchers in employing attention in their deep models. Note that, besides being demanding in terms of training data and computational resources, transformers only cover a single category in self-attention out of the many categories available. We fill this gap and provide an in-depth survey of 50 attention techniques, categorizing them by their most prominent features. We initiate our discussion by introducing the fundamental concepts behind the success of the attention mechanism. Next, we furnish some essentials such as the strengths and limitations of each attention category, describe their fundamental building blocks, basic formulations with primary usage, and applications specifically for computer vision. We also discuss the challenges and general open questions related to attention mechanisms. Finally, we recommend possible future research directions for deep attention. All the information about visual attention methods in deep learning is provided at \href{https://github.com/saeed-anwar/VisualAttention}{https://github.com/saeed-anwar/VisualAttention}
研究の動機と目的
- 研究者が transformer を超えた視覚に焦点を当てたアテンション機構の広いスペクトルを理解する動機づけを提供する。
- ソフト、ハード、マルチモーダル、算術、論理、自己学習など、アテンション技術の統一的な分類を提供し、それをコアの構成要素にマッピングする。
- コンピュータビジョンにおけるアテンションモジュールの基本概念、長所/短所、および主な用途を要約する。
- 視覚領域におけるディープアテンションの課題、ギャップ、および将来の研究方向性を強調する。
提案手法
- アテンション機構を dominant categories に分類する: soft (deterministic) attention、hard (stochastic) attention、multi-modal、arithmetic、logical、auto-learning アプローチなど。
- コアとなる構成要素と基本的な定式化(例えば、channel attention、spatial attention、self-attention)を説明し、代表的な例(SE、CBAM、ECA、DAN、A2-Nets など)を示す。
- アテンションスコアがどのように計算されるか(例: softmax、sigmoid、プーリング、周波数成分など)と、どのように注意付き特徴が統合されるかを説明する。
- transformerベースのself-attentionと、それが視覚における多くのアテンションタイプのうちの一つのカテゴリとしての役割を討議する。
- メモリ/計算トレードオフを含むアーキテクチャ的および計算上の考慮事項と、さまざまな視覚タスクへの適用性を議論する。
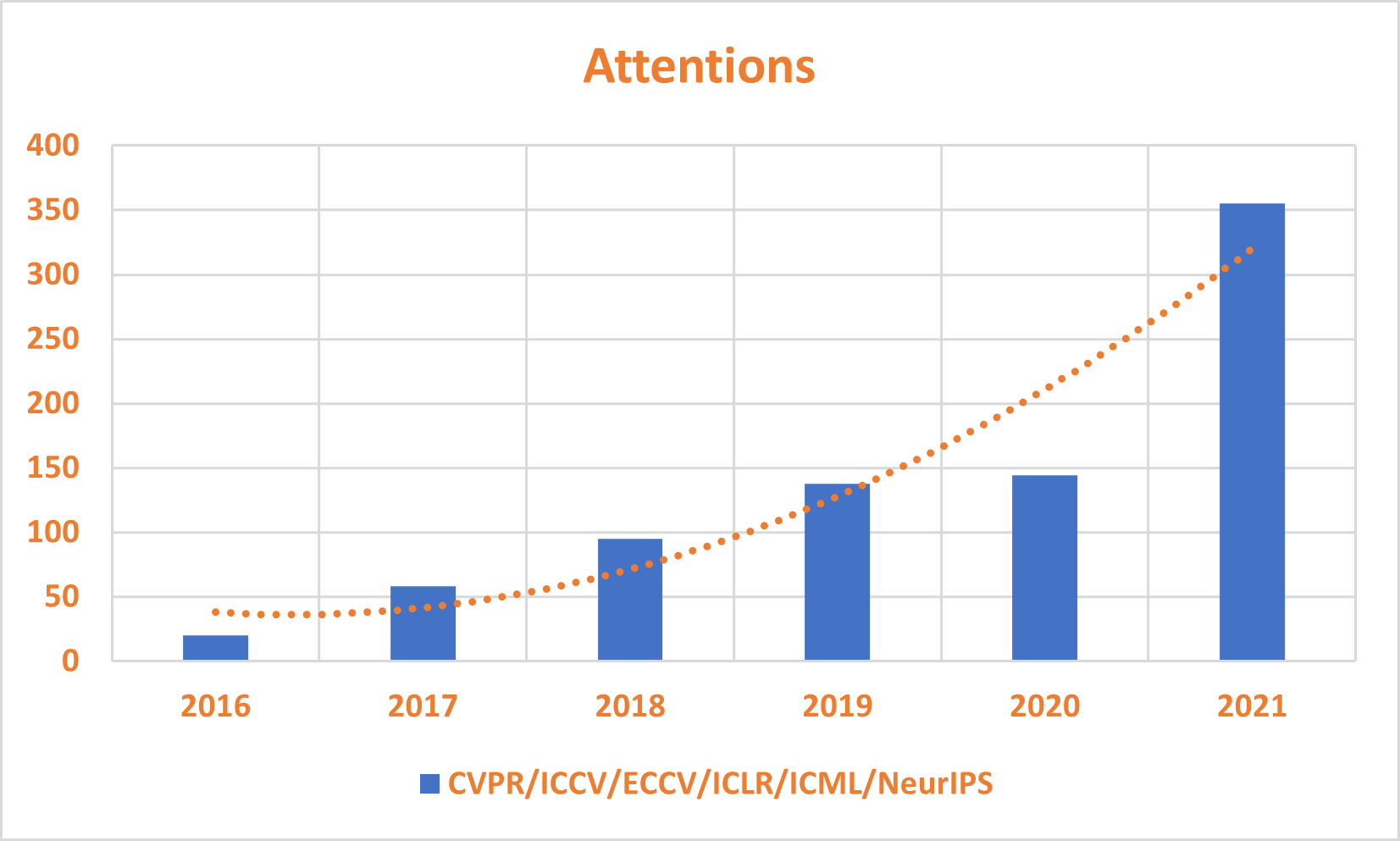
実験結果
リサーチクエスチョン
- RQ1視覚ディープラーニングで用いられるアテンション機構の dominant categories は何か?
- RQ2各アテンションカテゴリの長所、制限、コアとなる構成要素は何か?
- RQ3認識、セグメンテーション、検出など、一般的なコンピュータビジョン課題に対してアテンション手法がどのような影響を与えるか?
- RQ4transformerベースのアプローチを超えた視覚への深層アテンション適用における課題と未解決の問題は何か?
- RQ5視覚領域における深層アテンション手法を進展させる将来の研究方向は何か?
主な発見
- 視覚におけるアテンション機構は多様であり、self-attentionと transformers を超えた複数のカテゴリに分類できる。
- Channel attention、spatial attention、self-attention は、固有の長所と制限を持つコア soft attention のサブタイプを形成する。
- Transformerベースのself-attentionは、調査対象の50のアテンション技術の一部を占めるだけで、計算およびデータ量が高くつくことがある。
- ハイブリッドおよびマルチブランチのアテンションモジュール(例:A2-Nets、DAN、Harmonious Attention)は、より高次の相互作用やクロス特徴間の相互作用を捉えることができる。
- 2次統計量、周波数領域の成分、および自己学習アーキテクチャを用いる等の顕著な設計トレンドがあり、アテンションを強化する。
- 本調査は研究のギャップを識別し、視覚領域における堅牢で効率的、かつ一般化可能な深層アテンションの将来の方向性を提案する。
![Figure 3: Core structures of the channel-based attention methods. Different methods to generate the attention scores including squeeze and excitation [ 26 ] , splitting and squeezing [ 23 ] , calculating the second order [ 37 ] or efficient squeezing and excitation [ 22 ] . Images are taken from the](https://ar5iv.labs.arxiv.org/html/2204.07756/assets/figures/SE_att.png)
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。