[論文レビュー] Visual Chain of Thought: Bridging Logical Gaps with Multimodal Infillings
Visual Chain-of-Thought (VCoT) は連鎖的思考 prompting を vision-language ドメインに拡張し、連続データの論理的ギャップを埋めるマルチモーダルなインフィリングを生成・選択することで、データ拡張を通じて視覚的ストーリーテリングや WikiHow の要約といった下流の推論タスクを改善する。
Recent advances in large language models elicit reasoning in a chain-of-thought that allows models to decompose problems in a human-like fashion. Though this paradigm improves multi-step reasoning ability in language models, it is limited by being unimodal and applied mainly to question-answering tasks. We claim that incorporating visual augmentation into reasoning is essential, especially for complex, imaginative tasks. Consequently, we introduce VCoT, a novel method that leverages chain-of-thought prompting with vision-language grounding to recursively bridge the logical gaps within sequential data. Our method uses visual guidance to generate synthetic multimodal infillings that add consistent and novel information to reduce the logical gaps for downstream tasks that can benefit from temporal reasoning, as well as provide interpretability into models' multi-step reasoning. We apply VCoT to the Visual Storytelling and WikiHow summarization datasets and demonstrate through human evaluation that VCoT offers novel and consistent synthetic data augmentation beating chain-of-thought baselines, which can be used to enhance downstream performance.
研究の動機と目的
- テキストからマルチモーダル系列へのチェーンオブソート推論の拡張を動機づけ、論理的ギャップに対処します。
- トレーニング不要の反復的な生成と選択の枠組みを提案し、合成テキスト-視覚インフィリングを作成します。
- 下流の逐次タスクのデータ拡張を可能にし、複数ステップ推論への解釈可能な洞察を提供します。
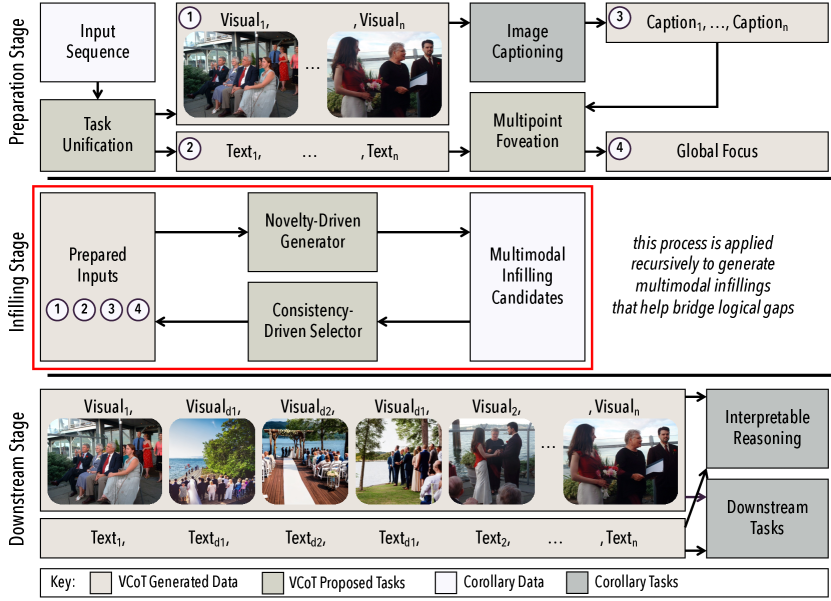
提案手法
- Stable Diffusion を用いてテキストのみのデータに対する候補ビジュアルを生成し、CLIP で与えられたテキストに最も類似するビジュアルを選択して、系列をテキスト-視覚ペアに統合します。
- multipoint foveation を用いて入力系列からグローバルな焦点を抽出し、一貫したインフィリング生成を導きます。
- 新規性と一貫性を指向したアプローチで、GPT-3.5 と視覚的グラウンディングに導かれたマルチモーダルインフィリングを再帰的に生成します。
- CLIP ベースの類似度を用いて最も一貫性のあるテキストおよびビジュアルインフィリングを選択し、固定再帰深度 (depth-limit = 2) を適用します。
- 新規性、整合性、コヒーレンス、記述性を重視した人間の判断でインフィリングを評価します。

実験結果
リサーチクエスチョン
- RQ1視覚とテキストの文脈から生成されたマルチモーダルインフィリングは、下流タスクのための系列データの論理的ギャップを橋渡しできますか。
- RQ2VCoT インフィリングは、視覚-言語タスク全般で、単一モードのチェーン・オブ・ソートのベースラインと比べて一貫性と新規性を向上させますか?
- RQ3視覚的ストーリーテリングと WikiHow 風要約における下流性能に、合成マルチモーダル拡張はどのような影響を与えますか?
- RQ4生成されたインフィリング間のコヒーレンスを維持する際のグラウンディングとフォビエーションの役割は何ですか?
主な発見
- VCoT インフィリングは、Chain-of-Thought (CoT) および Chain-of-Images (CoI) ベースラインよりも新規性と一貫性で人間評価者に高く評価されます。
- VCoT は WikiHow の要約と視覚的ストーリーテリングにおける下流性能をベースラインと比較して改善し、WikiHow での新規性の向上がより大きく、Vist での一貫性がより高くなる。
- 一貫性は multipoint foveation と CLIP-guided 選択によって支えられ、新規性はGPT-3.5駆動のテキストインフィリング生成とStable Diffusion生成のビジュアルによって達成されます。
- VCoT は推論過程のマルチモーダルな解釈性を提供し、逐次推論における論理的飛躍を減らすデータ拡張として機能します。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。