[論文レビュー] Visual Instruction Tuning
本論文は LLaVA を導入し、Vision Encoder と LLM を GPT-4 生成の視覚言語データで指示して訓練することで、強力なモ multimodal チャットを実現し、GPT-4 と組み合わせた ScienceQA で最先端を達成した。
Instruction tuning large language models (LLMs) using machine-generated instruction-following data has improved zero-shot capabilities on new tasks, but the idea is less explored in the multimodal field. In this paper, we present the first attempt to use language-only GPT-4 to generate multimodal language-image instruction-following data. By instruction tuning on such generated data, we introduce LLaVA: Large Language and Vision Assistant, an end-to-end trained large multimodal model that connects a vision encoder and LLM for general-purpose visual and language understanding.Our early experiments show that LLaVA demonstrates impressive multimodel chat abilities, sometimes exhibiting the behaviors of multimodal GPT-4 on unseen images/instructions, and yields a 85.1% relative score compared with GPT-4 on a synthetic multimodal instruction-following dataset. When fine-tuned on Science QA, the synergy of LLaVA and GPT-4 achieves a new state-of-the-art accuracy of 92.53%. We make GPT-4 generated visual instruction tuning data, our model and code base publicly available.
研究の動機と目的
- ビジョン-言語モデルに対する指示調整の拡張を促し、汎用の視覚アシスタントを可能にする。
- 言語モデルを用いた multimodal 指示追従データを生成するスケーラブルなパイプラインを提供する。
- 視覚エンコードと言語モデルを組み合わせた大規模 multimodal モデルを開発・評価する。
- 対話と推論タスクにおける multimodal 指示追従のベンチマーク(LLaVA-Bench)を作成・公開する。
提案手法
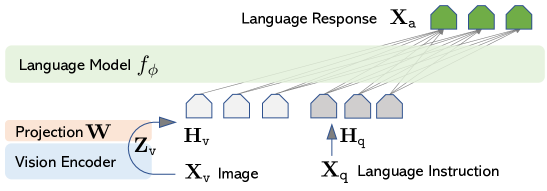
- CLIP 視覚エンコーダを訓練可能な射影 W を介して Vicuna 言語モデルに接続し、視覚トークンを生成する。
- 画像-テキストデータから GPT-4(および以前の ChatGPT)を用いて 158K の multimodal 指示追従サンプルを生成する。形式は会話、詳細な説明、複雑な推論の3形態。
- 2 段階の訓練: Stage 1 では CC3M のサブサンプルを用いて画像特徴と LLM 埋め込みを整列させ、視覚トークナイザを事前訓練する。Stage 2 では生成データ上で W と φ(LM)を用いたエンドツーエンド微調整を行う。
- GPT-4 アンサンブルとともに multimodal チャットデータで訓練し、 multimodal チャットと ScienceQA で評価する。結果を向上させるためにGPT-4とアンサンブルする。
実験結果
リサーチクエスチョン
- RQ1GPT-4 生成の視覚言語データは multimodal モデルの視覚指示調整を効果的に可能にするか。
- RQ2CLIP-Vicuna アーキテクチャと GPT-4 生成データパイプラインはオープンエンドの multimodal タスクでどの程度機能するか。
- RQ3LLaVA を GPT-4 と組み合わせると multimodal 推論ベンチマークで最先端の結果が得られるか。
- RQ4会話、詳細な説明、複雑な推論の異なるデータタイプが multimodal 配置にどの程度価値を持つか。
主な発見
| Model | Conversation | Detail description | Complex reasoning | All |
|---|---|---|---|---|
| OpenFlamingo | 19.3 ± 0.5 | 19.0 ± 0.5 | 19.1 ± 0.7 | 19.1 ± 0.4 |
| BLIP-2 | 54.6 ± 1.4 | 29.1 ± 1.2 | 32.9 ± 0.7 | 38.1 ± 1.0 |
| LLaVA | 57.3 ± 1.9 | 52.5 ± 6.3 | 81.7 ± 1.8 | 67.3 ± 2.0 |
| LLaVA † | 58.8 ± 0.6 | 49.2 ± 0.8 | 81.4 ± 0.3 | 66.7 ± 0.3 |
- LLaVA は強力な multimodal チャット機能を実現し、未見の画像と指示に対して multimodal GPT-4 に近づく。
- 合成 multimodal 指示追従データセットで、LLaVA は GPT-4 に対して相対スコア 85.1% を達成。
- ScienceQA で GPT-4 アンサンブルを用いた微調整により新たな最先端正解率 92.53% を達成。
- LLaVA-Bench(In-the-Wild)は指示調整によって大幅な改善を示し、3 種類のデータタイプ全てが総合性能を最も高く引き上げ、85.1%を達成。
- アブレーションは事前学習とモデル規模が結果に実質的に影響を与え、13B の LLaVA モデルは ScienceQA で 90.92% を達成し、GPT-4 と組み合わせると SOTA に到達する。
![Table 3 : Example prompt from GPT-4 paper [ 36 ] to compare visual reasoning and chat capabilities. Compared to BLIP-2 [ 28 ] and OpenFlamingo [ 5 ] , LLaVA accurately follows the user’s instructions, instead of simply describing the scene. LLaVA offers a more comprehensive response than GPT-4. Even](https://ar5iv.labs.arxiv.org/html/2304.08485/assets/figures/img_extreme_ironing.png)
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。