[論文レビュー] Visual Prompt Based Personalized Federated Learning
この論文は、クライアント固有のプロンプトを用いて局所データ分布を暗黄的にエンコードし共有バックボーンを導く、画像分類のための視覚プロンプトベースの個別化連邦学習フレームワークである pFedPT を紹介し、CIFAR-10/100 に対して最先端の PFL 手法より個別化と性能を向上させる。
As a popular paradigm of distributed learning, personalized federated learning (PFL) allows personalized models to improve generalization ability and robustness by utilizing knowledge from all distributed clients. Most existing PFL algorithms tackle personalization in a model-centric way, such as personalized layer partition, model regularization, and model interpolation, which all fail to take into account the data characteristics of distributed clients. In this paper, we propose a novel PFL framework for image classification tasks, dubbed pFedPT, that leverages personalized visual prompts to implicitly represent local data distribution information of clients and provides that information to the aggregation model to help with classification tasks. Specifically, in each round of pFedPT training, each client generates a local personalized prompt related to local data distribution. Then, the local model is trained on the input composed of raw data and a visual prompt to learn the distribution information contained in the prompt. During model testing, the aggregated model obtains prior knowledge of the data distributions based on the prompts, which can be seen as an adaptive fine-tuning of the aggregation model to improve model performances on different clients. Furthermore, the visual prompt can be added as an orthogonal method to implement personalization on the client for existing FL methods to boost their performance. Experiments on the CIFAR10 and CIFAR100 datasets show that pFedPT outperforms several state-of-the-art (SOTA) PFL algorithms by a large margin in various settings.
研究の動機と目的
- 連邦学習におけるデータ分布認識型の個別化の必要性を、モデル中心のアプローチを超えて動機づける。
- クライアント固有の視覚プロンプトを用いて局所データ分布情報をエンコードする新規フレームワークを提案する。
- プロンプト生成器と共有バックボーンの交互訓練を可能にし、クライアント固有の微調整を実現する。
- プロンプトが他の FL/PFL 手法へのプラグインとして機能し、標準ベンチマークでの性能を向上させることを実証する。
提案手法
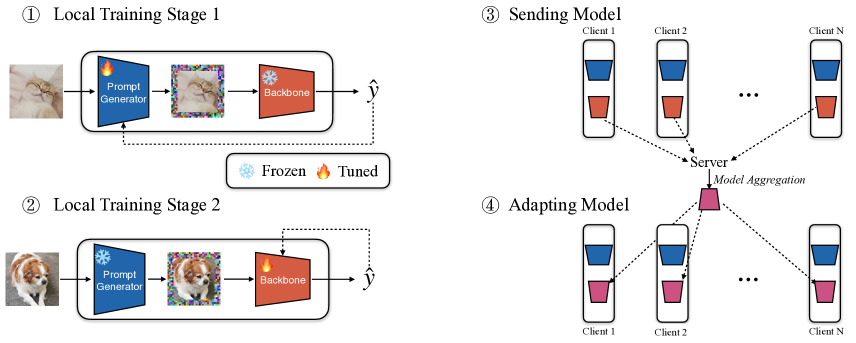
- 各クライアントはローカルなプロンプト生成器とバックボーンを維持する。
- 個々のクライアントに対して個別化された視覚プロンプトを生成し、訓練中のローカル入力に追加する。
- 交互最適化:バックボーンを凍結した状態でプロンプト生成器を更新し、次にプロンプトを凍結した状態でバックボーンを更新する。
- サーバは各通信ラウンドでクライアント間のバックボーンを連邦平均で集約する。
- プロンプトのサイズ/タイプを変化させる。CIFAR-10 の実験ではサイズ 4 のパディングベースのプロンプトが最も良い。
- 目的関数はバックボーンパラメータとクライアント固有のプロンプトの両方に対する損失を最小化する:L(w, δ_i) = E_{(x,y)~D_i}[ℓ_i(w; (x+δ_i, y))].
実験結果
リサーチクエスチョン
- RQ1クライアント固有の視覚プロンプトは局所データ分布をエンコードして共有バックボーンを導くことで個別性能を改善できるか。
- RQ2pFedPT は標準の画像分類ベンチマークの非 IID 設定で既存の PFL ベースラインとどのように比較されるか。
- RQ3プロンプトは pFedPT 以外の他の FL/PFL 手法に対してプラグイン的な改善を提供するか。
- RQ4どのようなプロンプト設計(場所とサイズ)が実践で最も良い性能を示すか。
主な発見
- pFedPT はさまざまな非 IID 設定下で CIFAR-10/100 においてベースラインより一貫して最高のテスト精度を達成する。
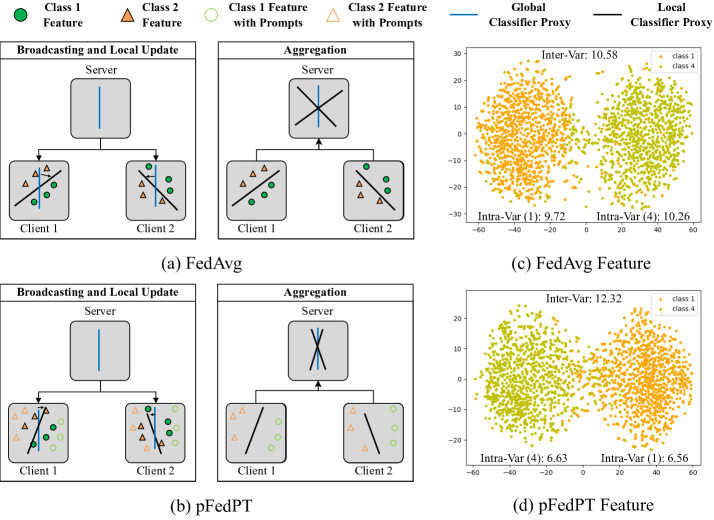
- Dirichlet CIFAR-10 で CNN を用いた場合、pFedPT は 80.83% に達し、FedAvg が 61.92%、FedPer が 77.98% であることと比較して著しい改善を示す。
- pFedPT は ViT および CNN のバックボーン間で頑健性を示し、データのヘテロジニティが増すとより有利になるように見える。
- プロンプト強化は他の FL 手法(例:FedProx、MOON、FedRep)に対しても、バックボーンへの分布認識的ヒントを提供して性能を高める。
- CIFAR-10 のアブレーション研究ではサイズ 4 のパディングプロンプトが最良の性能を示し、他のプロンプト設計は若干劣る。
- 視覚的分析(Grad-CAM、t-SNE)では、プロンプトが注意と埋め込みをクライアント固有情報へシフトさせ、分類を支援する可能性が示唆される。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。