[論文レビュー] Vivim: a Video Vision Mamba for Medical Video Segmentation
Vivimは、階層型エンコーダ内で空間的・時間的選択型状態空間モデリング(ST-Mamba)を用いるVideo Vision Mambaフレームワークを導入し、医用動画オブジェクトセグメンテーションを効率的に実行します。
Medical video segmentation gains increasing attention in clinical practice due to the redundant dynamic references in video frames. However, traditional convolutional neural networks have a limited receptive field and transformer-based networks are mediocre in constructing long-term dependency from the perspective of computational complexity. This bottleneck poses a significant challenge when processing longer sequences in medical video analysis tasks using available devices with limited memory. Recently, state space models (SSMs), famous by Mamba, have exhibited impressive achievements in efficient long sequence modeling, which develops deep neural networks by expanding the receptive field on many vision tasks significantly. Unfortunately, vanilla SSMs failed to simultaneously capture causal temporal cues and preserve non-casual spatial information. To this end, this paper presents a Video Vision Mamba-based framework, dubbed as Vivim, for medical video segmentation tasks. Our Vivim can effectively compress the long-term spatiotemporal representation into sequences at varying scales with our designed Temporal Mamba Block. We also introduce an improved boundary-aware affine constraint across frames to enhance the discriminative ability of Vivim on ambiguous lesions. Extensive experiments on thyroid segmentation, breast lesion segmentation in ultrasound videos, and polyp segmentation in colonoscopy videos demonstrate the effectiveness and efficiency of our Vivim, superior to existing methods. The code is available at: https://github.com/scott-yjyang/Vivim. The dataset will be released once accepted.
研究の動機と目的
- Motivate improved long-range temporal modeling for medical video segmentation.
- Develop a computationally efficient architecture that captures spatiotemporal cues across scales.
- Demonstrate effectiveness on breast ultrasound lesion segmentation and colonoscopy polyp segmentation.
- Provide a lightweight decoder that fuses multi-level features to predict segmentation masks.
提案手法
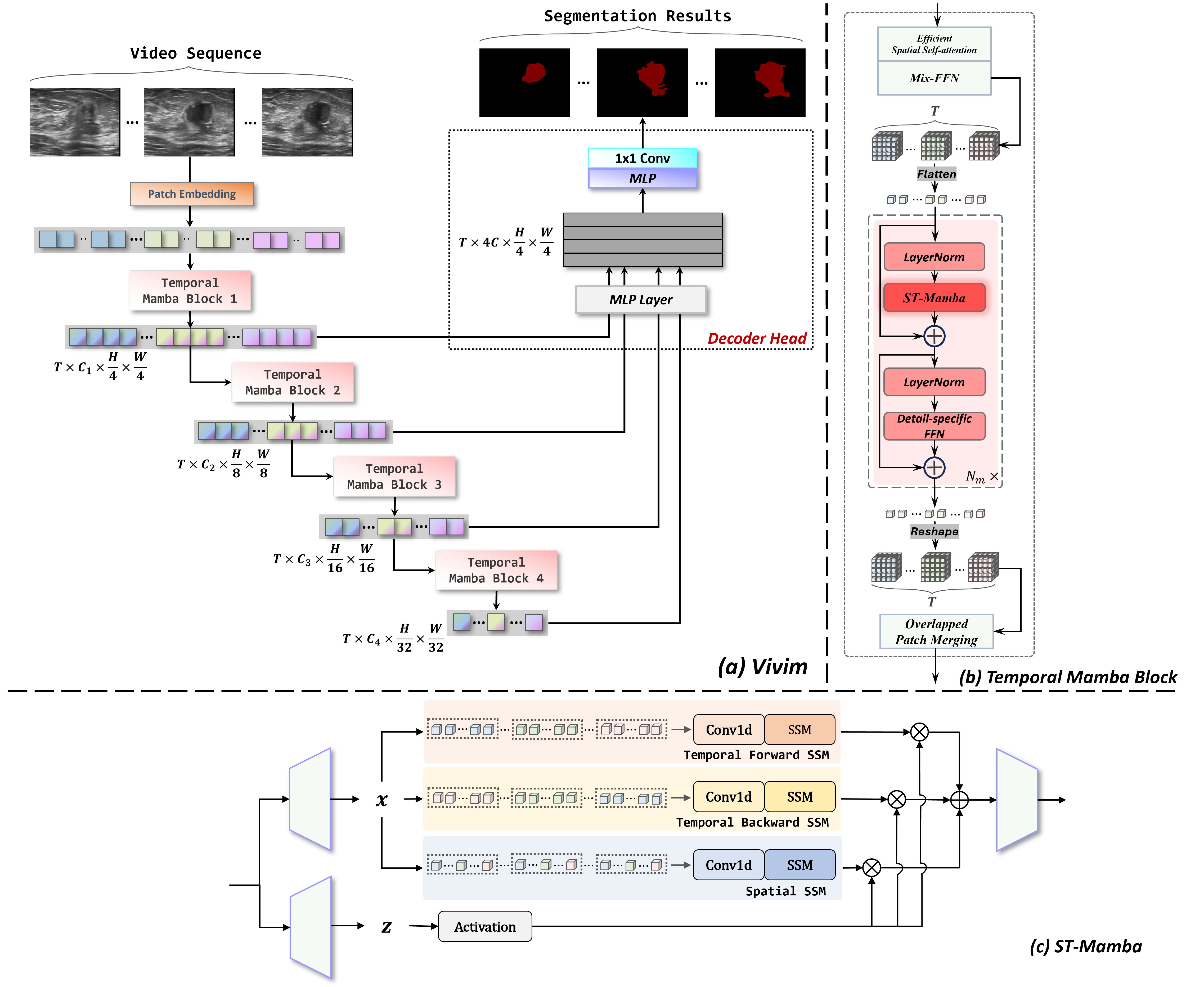
- Introduce Temporal Mamba Block to fuse spatial attention with temporal dependencies.
- Use a hierarchical encoder to extract multi-level spatiotemporal features at resolutions 1/4, 1/8, 1/16, 1/32.
- Replace self-attention with ST-Mamba (spatiotemporal selective scan) for efficient long-sequence modeling.
- Employ a lightweight CNN-based decoder to fuse multi-level features and predict segmentation masks.
- Ground ST-Mamba in state space models with discrete A, B, C matrices and zero-order hold discretization for efficient kernel construction.
- Train in an end-to-end manner on ultrasound breast lesion and colonoscopy polyp video datasets with standard losses (cross-entropy and IoU).
実験結果
リサーチクエスチョン
- RQ1Can ST-Mamba capture long-range spatiotemporal dependencies more efficiently than traditional Transformer self-attention in medical video segmentation?
- RQ2Does a hierarchical Temporal Mamba encoder improve segmentation performance across multiple scales compared to single-scale methods?
- RQ3Is a lightweight CNN decoder sufficient to fuse multi-level ST-Mamba features for accurate segmentation?
- RQ4How does Vivim perform on breast ultrasound lesion segmentation and colonoscopy polyp segmentation in terms of accuracy and speed?
- RQ5What are the computational trade-offs between ST-Mamba and self-attention for long video sequences?
主な発見
- Vivim achieves strong segmentation performance on polyp and breast lesion video datasets, outperforming several state-of-the-art methods across metrics.
- The Temporal Mamba Block enables efficient intra- and inter-frame dependency modeling with reduced computational cost compared to full self-attention.
- ST-Mamba, with spatiotemporal selective scan, effectively handles long video sequences while maintaining higher FPS than many Transformer-based approaches.
- The hierarchical encoder provides multi-scale representations that improve boundary accuracy and segmentation fidelity in medical videos.
- Experiments on CVC-300, CVC-612, ASU-Mayo, and breast US datasets demonstrate the universality and effectiveness of Vivim.
- Vivim achieves superior run-time performance on the breast ultrasound dataset, illustrating advantages in speed alongside accuracy.

より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。