[論文レビュー] Voice Transformer Network: Sequence-to-Sequence Voice Conversion Using Transformer with Text-to-Speech Pretraining
本論文は、Voice Transformer Network(VTN)を導入し、Transformer ベースの seq2seq 音声変換モデルと、データ効率と音声品質を向上させる二段階の Text-to-Speech 事前学習戦略を用いて、RNN ベースの基準モデルを上回る。
We introduce a novel sequence-to-sequence (seq2seq) voice conversion (VC) model based on the Transformer architecture with text-to-speech (TTS) pretraining. Seq2seq VC models are attractive owing to their ability to convert prosody. While seq2seq models based on recurrent neural networks (RNNs) and convolutional neural networks (CNNs) have been successfully applied to VC, the use of the Transformer network, which has shown promising results in various speech processing tasks, has not yet been investigated. Nonetheless, their data-hungry property and the mispronunciation of converted speech make seq2seq models far from practical. To this end, we propose a simple yet effective pretraining technique to transfer knowledge from learned TTS models, which benefit from large-scale, easily accessible TTS corpora. VC models initialized with such pretrained model parameters are able to generate effective hidden representations for high-fidelity, highly intelligible converted speech. Experimental results show that such a pretraining scheme can facilitate data-efficient training and outperform an RNN-based seq2seq VC model in terms of intelligibility, naturalness, and similarity.
研究の動機と目的
- プロソディと持続時間の変化を捉える seq2seq 音声変換 (VC) を動機づける。
- RNN/CNN ベースのモデルを置換するために VC に Transformer アーキテクチャを活用する。
- データ効率を改善し誤発音を減らすための二段階の TTS ベース事前学習を導入する。
- TTS 事前学習済みの VC が、限られた VC データでも高品質で聴き取りやすい音声を生み出すことを示す。
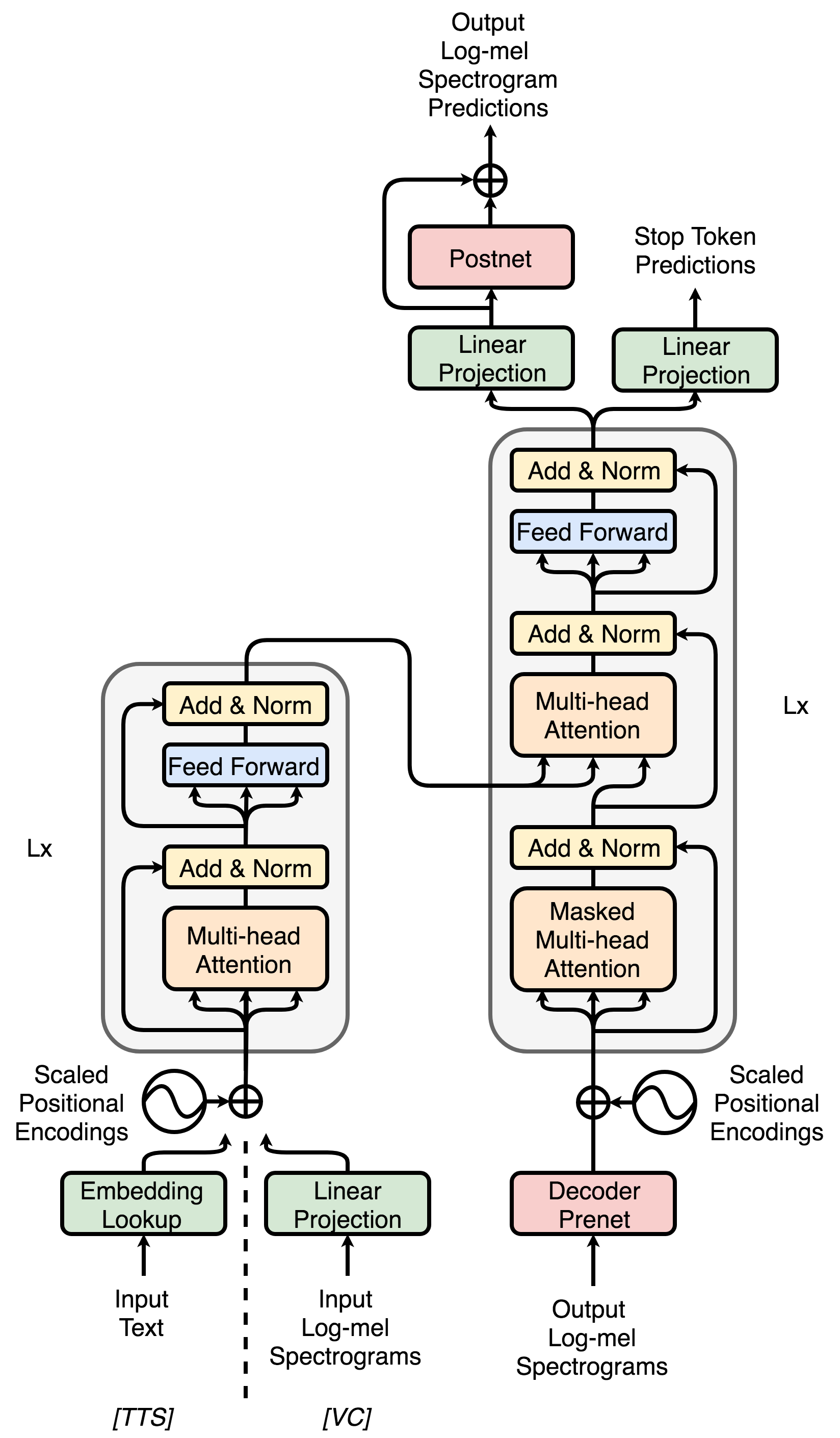
提案手法
- エンコーダ入力埋め込みを線形投影に置換することで、VC のために Transformer-TTS アーキテクチャを適応させる。
- トレーニング時のアテンションを安定化させるため、フレームを積み重ねるエンコーダ削減係数を導入する。
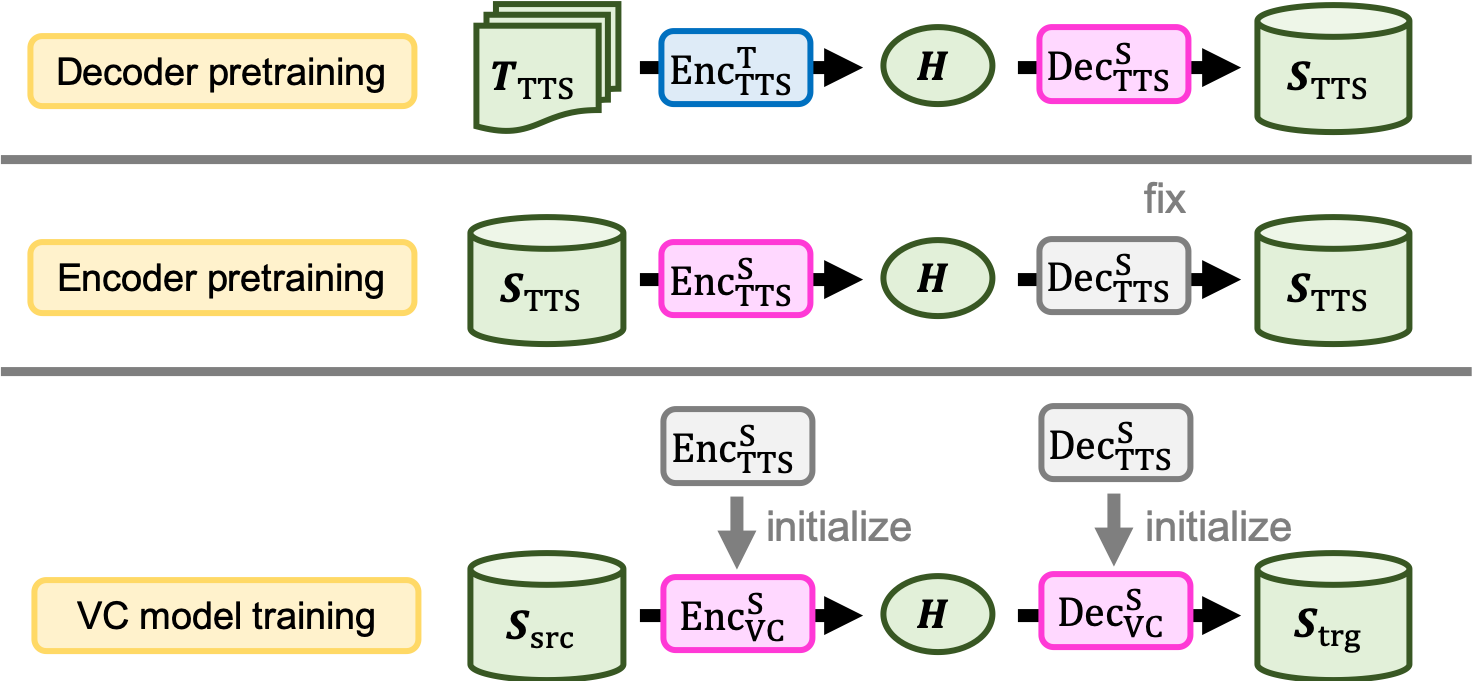
- 大規模な TTS データでデコーダを事前学習し、固定済みの事前学習デコーダを用いたオートエンコーダでエンコーダを事前学習する、二段階の事前学習を提案する。
- 多話者の非並列 TTS および VC データを使用し、二段階のトレーニングで TTS から VC への細かな表現を転移する。
- スペクトル忠実度と聴き取りやすさを評価するため、MCD、CER、WER、MOS風の主観テストを用いて評価する。
実験結果
リサーチクエスチョン
- RQ1Transformer ベースの seq2seq VC モデルは、RNN ベースの seq2seq VC モデルよりも理解しやすさと自然さを向上させることができるか?
- RQ2大規模 TTS データで VC コンポーネントを事前学習することは、小規模 VC データセットでのデータ効率と堅牢性を改善するか?
- RQ3提案された VC システムは、スペクトル歪み、ASR との適合性、知覚的な自然さと類似性の観点からどのように性能を示すか?
主な発見
- 同じデータで訓練した場合、TTS 事前学習を組み込んだ VTN は、客観指標で一貫してベースライン ATTS2S を上回る。
- エンコーダ事前学習とデコーダ事前学習の組み合わせは、VC データ量が減少するにつれて特に堅牢な向上をもたらす。
- 十分な訓練データを用いた場合、VTN は主観テストで自然さと類似性をベースラインより著しく改善する。
- ごく限られた VC データ(例:80 発話)でも、VTN はベースラインより優れており、データ効率の高さを示している。
- TTS 適応のみと比較して、事前学習付きの VTN は、より良いプロソディの保持と言語表現の表現により、自然さと類似性を高く達成できる。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。