[論文レビュー] Voices Obscured in Complex Environmental Settings (VOICES) corpus
VOICESコーパスは、現実的なノイズのある部屋で開放・遠距離・複数マイクの音声データを提供し、LibriSpeech由来の前景に様々な妨害ノイズを組み合わせ、ベースラインのASRとSID評価を含む。
This paper introduces the Voices Obscured In Complex Environmental Settings (VOICES) corpus, a freely available dataset under Creative Commons BY 4.0. This dataset will promote speech and signal processing research of speech recorded by far-field microphones in noisy room conditions. Publicly available speech corpora are mostly composed of isolated speech at close-range microphony. A typical approach to better represent realistic scenarios, is to convolve clean speech with noise and simulated room response for model training. Despite these efforts, model performance degrades when tested against uncurated speech in natural conditions. For this corpus, audio was recorded in furnished rooms with background noise played in conjunction with foreground speech selected from the LibriSpeech corpus. Multiple sessions were recorded in each room to accommodate for all foreground speech-background noise combinations. Audio was recorded using twelve microphones placed throughout the room, resulting in 120 hours of audio per microphone. This work is a multi-organizational effort led by SRI International and Lab41 with the intent to push forward state-of-the-art distant microphone approaches in signal processing and speech recognition.
研究の動機と目的
- リアルな部屋の音響と背景ノイズを備えた自由に利用可能な遠距離マイク音声コーパスを提供し、音声・信号処理研究を促進する。
- 実世界の条件を反映するため、複数の部屋録音と複数のマイク配置、妨害ノイズを提供する。
- VOICESデータに対するベースラインのASRと話者識別結果を示し、将来モデルのベンチマークとなる。
- 反響環境でのイベント/背景検出、音源分離、音声強調、局在化の研究を促進する。
提案手法
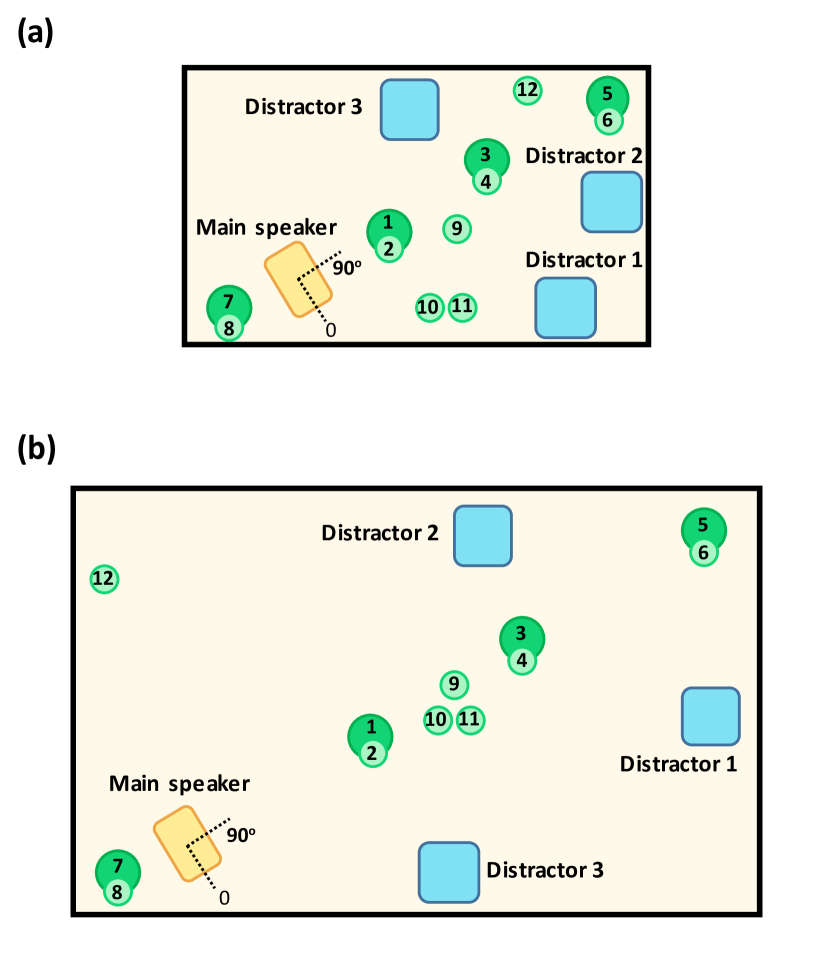
- 二つの家具付き部屋で、異なる音響特性を持つ前景LibriSpeech由来の音声を録音する。
- 前景音声と同期した妨害ノイズ(テレビ、音楽、雑音)を再生し、12台の遠方マイクで録音する。
- マイクあたり120時間データ(374,688音声ファイル)を48 kHz/24-bit(および16 kHzオプション)で提供し、ソース音声と転写を含む。
- 頭部の動きを模擬する回転する前景スピーカーを使用して、再現性ある反響・ノイズ条件を比較する。
- 正書法転写と話者ラベルで注釈を付け、基本統計量(SNR、RMS、振幅)を計算し、ベースラインASR/SID実験を提供する。
実験結果
リサーチクエスチョン
- RQ1現場近接録音データで訓練された場合、現実的な部屋の残響と妨害ノイズ下で distant-microphone speech recognitionはどのように性能を発揮するか?
- RQ2VOICESコーパスにおけるマイク距離と部屋の音響特性がASRとSIDの性能にどのように影響するか?
- RQ3オープンVOICESデータは、騒音環境下の音声/話者認識、検出、強調、改善のための頑健な音響モデル開発を支援できるか?
- RQ4ノイズ種とマイク配置を跨いだVOICESデータに対して、標準的なASRとSIDシステムのベースライン性能はどの程度達成されるか?
主な発見
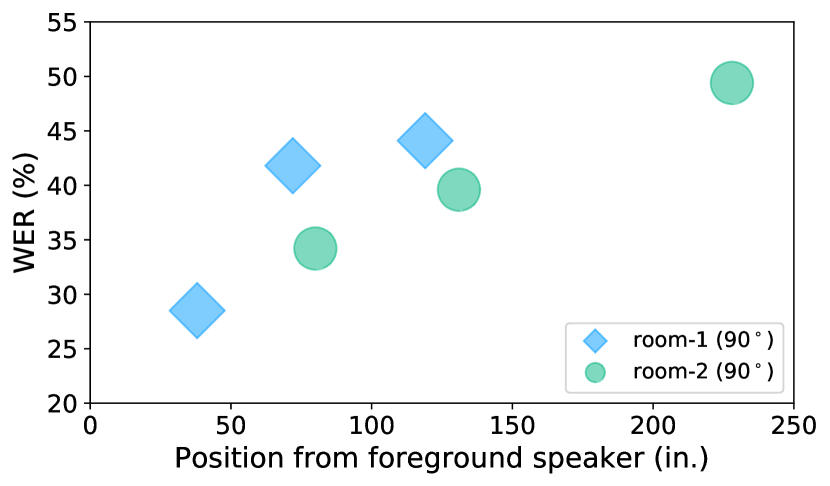
- ASR WERは距離と妨害ノイズにより有意に悪化する。例えば、SRIシステムでは、ソース9.3%対、Babbleで33.0%(Room-1, 90°)の例がある。
- 距離はSIDを劣化させる:EERはソースの5.72%から、Room-1/Room-2のFarマイクで15.1–16.6%へ上昇(妨害なし条件下)。
- 妨害ノイズはSIDをさらに悪化させ、ノイズなしとTV/Music/Babbleの音カテゴリに応じて約2–3.5ppのEERを減少/悪化させる。
- 部屋と条件を横断した平均SNRは距離とともに低下する。Room-1の平均は22.19 dB、Room-2の平均は19.50 dB。
- VOICESデータはマイク1つあたり120時間、12台のマイク、374,688音声ファイルを含み、話者識別と音声認識タスクのためLibriSpeech前景と整合。
- ベースラインのASR結果は、現実的な音響環境で近接場条件と比較して著しく劣化する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。