[論文レビュー] Weak-Mamba-UNet: Visual Mamba Makes CNN and ViT Work Better for Scribble-based Medical Image Segmentation
Weak-Mamba-UNet は CNN、Vision Transformer、Visual Mamba ネットワークを scribble ベースの弱教師付き枠組みの下で組み合わせ、クロス監督学習と疑似ラベリングを通じて医療画像分割を改善します。
Medical image segmentation is increasingly reliant on deep learning techniques, yet the promising performance often come with high annotation costs. This paper introduces Weak-Mamba-UNet, an innovative weakly-supervised learning (WSL) framework that leverages the capabilities of Convolutional Neural Network (CNN), Vision Transformer (ViT), and the cutting-edge Visual Mamba (VMamba) architecture for medical image segmentation, especially when dealing with scribble-based annotations. The proposed WSL strategy incorporates three distinct architecture but same symmetrical encoder-decoder networks: a CNN-based UNet for detailed local feature extraction, a Swin Transformer-based SwinUNet for comprehensive global context understanding, and a VMamba-based Mamba-UNet for efficient long-range dependency modeling. The key concept of this framework is a collaborative and cross-supervisory mechanism that employs pseudo labels to facilitate iterative learning and refinement across the networks. The effectiveness of Weak-Mamba-UNet is validated on a publicly available MRI cardiac segmentation dataset with processed scribble annotations, where it surpasses the performance of a similar WSL framework utilizing only UNet or SwinUNet. This highlights its potential in scenarios with sparse or imprecise annotations. The source code is made publicly accessible.
研究の動機と目的
- 医療画像分割におけるラベリングコストを削減するために scribble ベースの注釈の利用を促進する。
- 弱教師付きの下で CNN、ViT、VMamba アーキテクチャを共同訓練する multi-view のクロス監視フレームワークを提案する。
- スパースな scribble 監 supervision を dense な信号ガイダンスへ変換するための疑似ラベル付けを導入する。
- CNN、ViT、VMamba の統合が、単一バックボーンの弱教師付き手法と比較して MRI 心臓データにおける分割性能を向上させることを示す。
提案手法
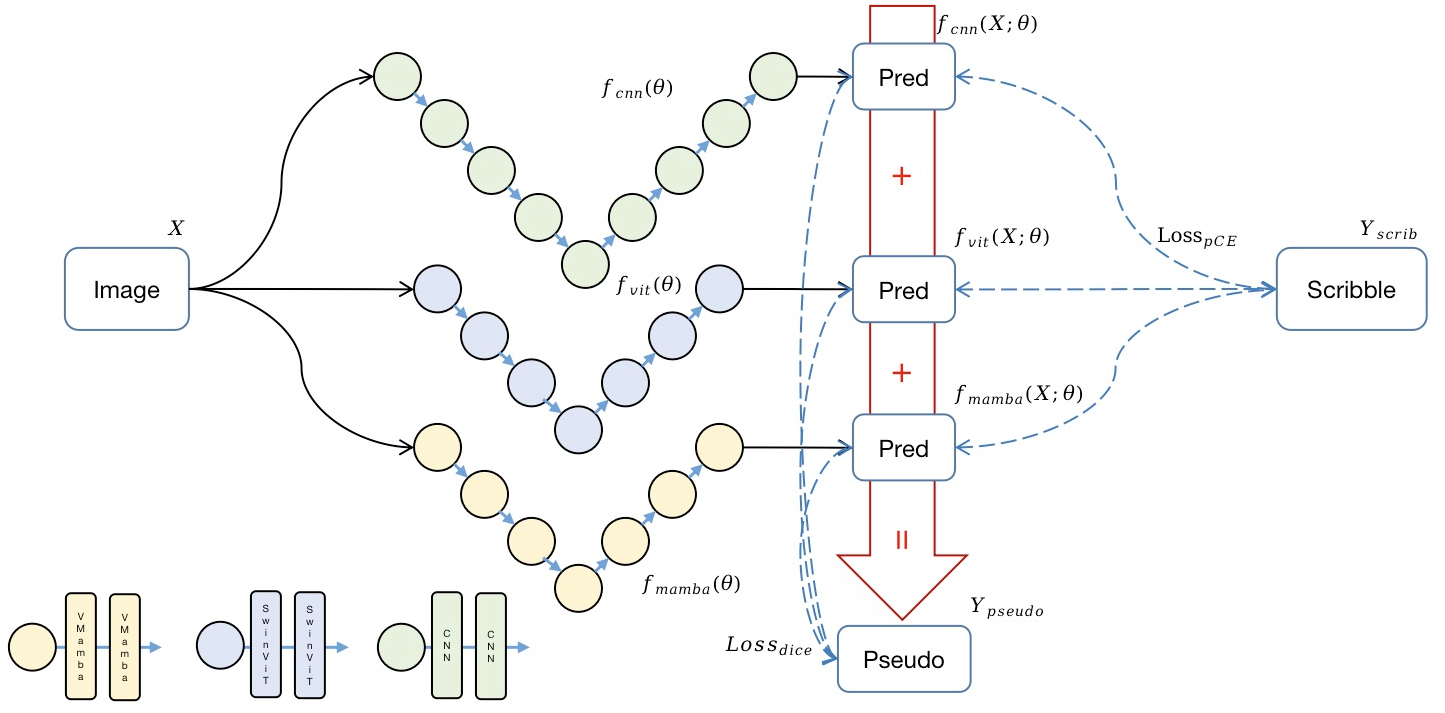
- 三つの encoder–decoder バックボーンを使用: UNet (CNN)、SwinUNet (ViT)、MambaUNet (Visual Mamba)。
- scribble でラベル付けされたピクセルに部分交差エントロピー損失を適用(ラベリングされていない領域は無視)。
- 三つのネットワークの予測の加重結合から dense な疑似ラベルを作成 (Ypseudo = α fcnn + β ftjn + γ fmamba, 各イテレーションごとにランダムな α, β, γ、α+β+γ=1)。
- 予測と Ypseudo の argmax を用いた Dice 系数損失を適用して、全ネットワークに対して dense な監視を提供する。
- 損失はネットワークごとの scribble 損失と dice 損失を結合: Ltotal = sum_i (Lpce^i + Ldice^i) for i ∈ {CNN, ViT, Mamba}。
- ネットワークを別々に初期化(UNet、SwinUNet、MambaUNet)して多様な視点を促進し、クロス監視を可能にする。
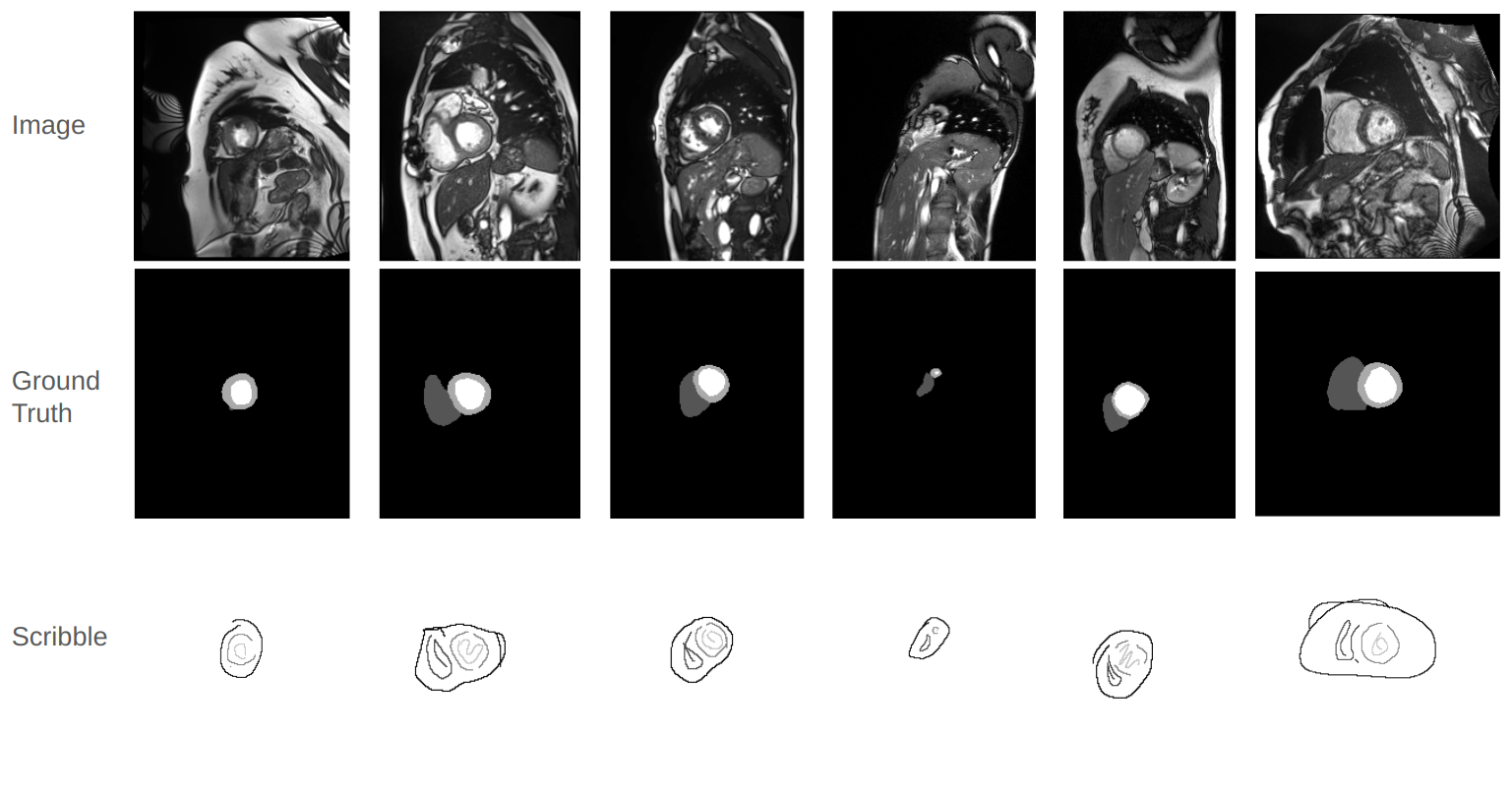
実験結果
リサーチクエスチョン
- RQ1研究質問(RQ) : ["CNN、ViT、および VMamba をクロス監視型の scribble ベーススキームで組み合わせることは、単一バックボーンの WSL 手法と比較して分割性能を向上させるか?","多視点予測から生成された疑似ラベルが、密な注釈なしで dense な監督を向上させるか?","VMamba アーキテクチャは、WSL 設定における長距離依存性モデリングと全体的な分割精度にどのように寄与するか?"]
- RQ2research_questionsuziational_parts
- RQ3research_questions (RQ) : ["Does incorporating CNN, ViT, and VMamba under a cross-supervised, scribble-based scheme improve segmentation performance compared to single-backbone WSL methods?","Can pseudo-labels generated from multi-view predictions enhance dense supervision without dense annotations?","How does the VMamba architecture contribute to long-range dependency modeling and overall segmentation accuracy in a WSL setting?"]
主な発見
| ネットワーク | Dice ↑ | Acc ↑ | Pre ↑ | Sen ↑ | Spe ↑ | HD ↓ | ASD ↓ |
|---|---|---|---|---|---|---|---|
| pCE + UNet | 0.7620 | 0.9807 | 0.6799 | 0.9174 | 0.9823 | 151.0593 | 54.6531 |
| USTM + UNet | 0.8592 | 0.9917 | 0.8128 | 0.9257 | 0.9888 | 99.8293 | 26.0185 |
| Mumford + UNet | 0.8993 | 0.9950 | 0.8844 | 0.9200 | 0.9874 | 28.0604 | 7.3907 |
| Gated CRF + UNet | 0.9046 | 0.9955 | 0.8890 | 0.9304 | 0.9922 | 7.4340 | 2.0753 |
| pCE + SwinUNet | 0.8935 | 0.9950 | 0.8808 | 0.9129 | 0.9884 | 24.4750 | 6.9108 |
| USTM + SwinUNet | 0.9044 | 0.9957 | 0.8952 | 0.9187 | 0.9898 | 6.5172 | 2.2319 |
| Mumford + SwinUNet | 0.9051 | 0.9958 | 0.8996 | 0.9157 | 0.9889 | 6.0653 | 1.6482 |
| Gated CRF + SwinUNet | 0.8995 | 0.9955 | 0.8920 | 0.9175 | 0.9904 | 6.6559 | 1.6222 |
| Weak-Mamba-UNet | 0.9171 | 0.9963 | 0.9095 | 0.9309 | 0.9920 | 3.9597 | 0.8810 |
- Weak-Mamba-UNet は MRI 心臓データセットにおいて、テストされた弱教師付きフレームワークの中で最も高い Dice、精度、適合率、感度、特異度を達成した。
- 基準と比較して最も低い Hausdorff 距離 (HD) および平均表面距離 (ASD) を達成した。
- アブレーションにより、UNet + SwinUNet + MambaUNet の組み合わせが単一バックボーンを超える結果を示し、Ours 構成が強力な指標を達成。
- SwinUNet ベースの WSL 手法は一般に UNet ベースより優れているが、多視点統合はそれを上回る追加の利点を生む。
- scribble 監視の下でのクロスビュー協調は、注釈コストを抑えつつ高い分割性能を発揮できることを示している。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。