[論文レビュー] WebFace260M: A Benchmark Unveiling the Power of Million-Scale Deep Face Recognition
この論文は CAST cleaning を用いた WebFace260M(4M identities, 260M faces)と、それにクリーンアップされた WebFace42M(2M identities, 42M faces)を紹介します。さらに百万規模の顔認識と分散トレーニングを研究するための FRUITS の時間制約評価を提案します。
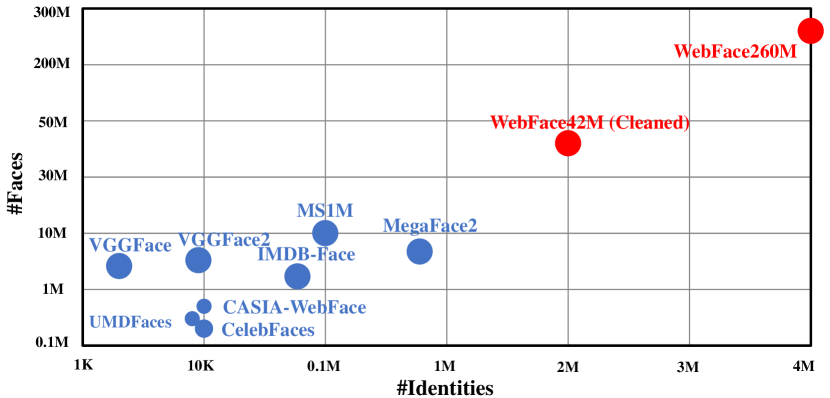
In this paper, we contribute a new million-scale face benchmark containing noisy 4M identities/260M faces (WebFace260M) and cleaned 2M identities/42M faces (WebFace42M) training data, as well as an elaborately designed time-constrained evaluation protocol. Firstly, we collect 4M name list and download 260M faces from the Internet. Then, a Cleaning Automatically utilizing Self-Training (CAST) pipeline is devised to purify the tremendous WebFace260M, which is efficient and scalable. To the best of our knowledge, the cleaned WebFace42M is the largest public face recognition training set and we expect to close the data gap between academia and industry. Referring to practical scenarios, Face Recognition Under Inference Time conStraint (FRUITS) protocol and a test set are constructed to comprehensively evaluate face matchers. Equipped with this benchmark, we delve into million-scale face recognition problems. A distributed framework is developed to train face recognition models efficiently without tampering with the performance. Empowered by WebFace42M, we reduce relative 40% failure rate on the challenging IJB-C set, and ranks the 3rd among 430 entries on NIST-FRVT. Even 10% data (WebFace4M) shows superior performance compared with public training set. Furthermore, comprehensive baselines are established on our rich-attribute test set under FRUITS-100ms/500ms/1000ms protocol, including MobileNet, EfficientNet, AttentionNet, ResNet, SENet, ResNeXt and RegNet families. Benchmark website is https://www.face-benchmark.org.
研究の動機と目的
- 顔認識における学術界と産業界のデータギャップを埋めるため、百万規模のトレーニングデータを作成する。
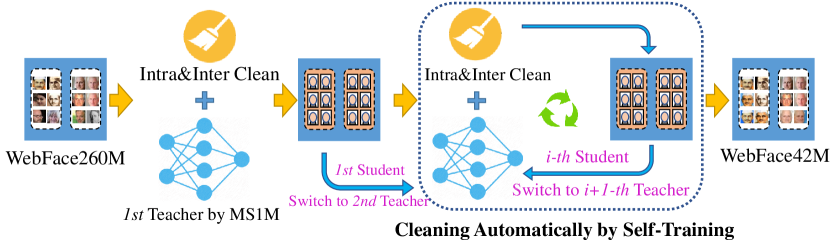
- ノイズのあるウェブデータから高品質なトレーニングセットを作成するための、スケーラブルな自動クリーニングパイプライン(CAST)を開発する。
- FRUITS(Face Recognition Under Inference Time conStraint)を提案し、実世界のデプロイメントに近いテストセットを含む時間制約付き評価プロトコルを提案する。
- 大規模および軽量なバックボーンの双方における百万規模のトレーニングと分散トレーニングの利点を示す。
- FRUITS プロトコルの下でアーキテクチャ横断の包括的なベースラインを提供し、今後の研究を導く。
提案手法
- 4M のセレブリティ名リストを収集し、ウェブから 260M 枚の画像をダウンロードする。
- WebFace260M を Cleaning Automatically via Self-Training (CAST) パイプラインでクリーンにして WebFace42M を得る。
- 分散フレームワークを用いて大規模データでほぼ線形のスピードアップを達成する。
- FRUITS(Face Recognition Under Inference Time conStraint)を 100/500/1000 ms トラックと豊富な属性テストセットとともに設計する。
- FRUITS および標準ベンチマークで複数のバックボーン(例:ResNet-100, ResNet-14)と損失(CosFace, ArcFace, CurricularFace)を評価する。
実験結果
リサーチクエスチョン
- RQ1トレーニングデータのスケール(WebFace260M 対 WebFace42M およびサブセット)が、時間制約付き評価の下で認識性能にどのような影響を与えるか?
- RQ2CAST が巨大なノイズを含むウェブ規模データを高品質な顔認識トレーニングデータへクリーニングする効果はどの程度か?
- RQ3FRUITS の下で大型と軽量のネットワークの両方で百万規模トレーニングによって達成可能な性能向上はどの程度か?
- RQ4分散トレーニングは百万規模の顔認識において学術界と産業界のデータと計算のギャップを縮めることができるか?
- RQ5公開データセットと比較して、難解なベンチマーク(IJB-C, NIST-FRVT)で WebFace42M の性能はどの程度か?
主な発見
- WebFace42M は IJB-C で標準の ResNet-100 設定の下、TAR@FAR=1e-4 が 97.70% を達成し、公開 SOTA に比べて誤差率を約 40% 減少させる。
- WebFace4M(WebFace42M の 10%)を使用するだけで、MS1M ファミリー や MegaFace2 などの公開トレーニングセットと比較してすでに優れた性能を示す。
- WebFace42M は NIST-FRVT の 430 エントリ中 3 位にランクインしており、時間制約付きベンチマークに対する百万規模データの競争力を示している。
- WebFace42M はこれまでで最大の公開クリーンなトレーニングセットを提供し、ヘビーウェイトとライトウェイトのモデルの双方で大幅な改善を可能にしている。
- Distributed training with mixed-precision and feature/center parallelization achieves near-linear speedups (e.g., up to 32 nodes) with minimal performance loss.
- Under FRUITS, a range of baselines across Lightweight to Heavyweight models reveal meaningful gaps and room for improvement, especially on FRUITS-100 (lightweight) and FRUITS-1000 (heavyweight) tracks.
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。