[論文レビュー] What Makes Good Examples for Visual In-Context Learning?
本論文は、文脈内の視覚的例の選択が性能にいかに重大な影響を与えるかを分析し、視覚的文脈学習のために有益なプロンプトを自動的に選択する無監督・監督型のプロンプト取得フレームワークを提案する。
Large-scale models trained on broad data have recently become the mainstream architecture in computer vision due to their strong generalization performance. In this paper, the main focus is on an emergent ability in large vision models, known as in-context learning, which allows inference on unseen tasks by conditioning on in-context examples (a.k.a.~prompt) without updating the model parameters. This concept has been well-known in natural language processing but has only been studied very recently for large vision models. We for the first time provide a comprehensive investigation on the impact of in-context examples in computer vision, and find that the performance is highly sensitive to the choice of in-context examples. To overcome the problem, we propose a prompt retrieval framework to automate the selection of in-context examples. Specifically, we present (1) an unsupervised prompt retrieval method based on nearest example search using an off-the-shelf model, and (2) a supervised prompt retrieval method, which trains a neural network to choose examples that directly maximize in-context learning performance. The results demonstrate that our methods can bring non-trivial improvements to visual in-context learning in comparison to the commonly-used random selection.
研究の動機と目的
- 文脈内の例の選択が視覚的文脈学習の性能にどのように影響するかを調査する。
- 視覚モデルにおけるプロンプトの選択が下流タスクに与える感度を定量化する。
- ランダム選択よりもプロンプト品質を向上させる自動プロンプト取得手法を開発する。
- 分布シフトおよび複数の視覚タスクにおける頑健性を評価する。
提案手法
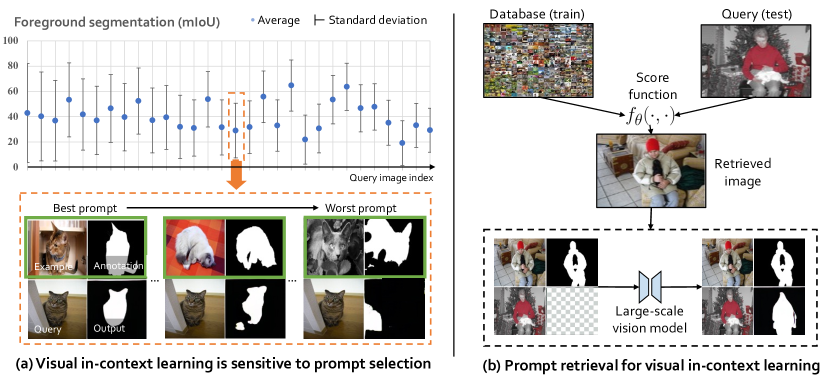
- モデル非依存の視覚的文脈内学習設定で、プロンプトは予測を指示する画像-ラベルのペアの集合であり、モデルパラメータを更新せずに行う。
- クエリ x_q に対して上位のプロンプトを選択するスコアベースのプロンプト取得フレームワーク f_theta(x_n, x_q) を提案する。
- 固定のオフ・ザ・シェルフ特徴量を用いた最近傍探索による無監督プロンプト取得(UnsupPR)を実装する。
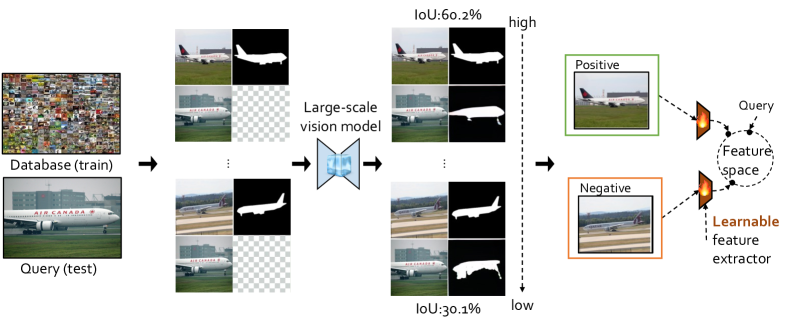
- in-context 学習の性能を最大化するコントラスト学習目的で特徴抽出器を学習し、監督付きプロンプト取得(SupPR)を実装する。
- トップ5の正例/負例の性能セットに基づき、プロンプトを引き寄せる/離すためにコントラスト損失で SupPR を訓練する。
- 事前学習済みの画像インペインティングモデルを用いて、前景分割、単一オブジェクト検出、画像着色の3つの下流タスクで評価する。
実験結果
リサーチクエスチョン
- RQ1文脈内の例の選択は、タスクをまたいだ視覚的文脈学習の性能にどう影響するか?
- RQ2自動プロンプト取得はランダム選択を超える性能向上を達成できるか?
- RQ3無監督および監督付きプロンプト取得戦略は有効か、どちらがより良い結果をもたらすか?
- RQ4プロンプトサイズ、バックボーン、取得セットサイズが結果と分布シフトに対する頑健性にどう影響するか?
主な発見
- 前景分割と物体検出で、プロンプト取得はランダム選択に対して顕著に改善される(それぞれ ≥6% および約1% の mIoU 増加)。
- 監督付きプロンプト取得法(SupPR)は、すべてのタスクで無監督版(UnsupPR)およびランダムベースラインを一貫して上回る。
- プロンプト取得による性能向上は、異なるバックボーン(CLIP、EVA、ViT)間でも持続し、バックボーン感度は最小限である。
- SupPR は分布シフト(Pascal から MSCOCO)に対する頑健性が、UnsupPR や Random よりも高い。とはいえ、シフト下の総合的な利得は同一分布下の利得より小さい。
- 文脈内例の数を増やすと、ほとんどの手法で性能が向上する傾向があり、品質の高い例が選ばれた場合、順序の影響は小さい。
- SupPR はクエリに意味的にも空間的にも近いプロンプトを選択する傾向があり、意味的類似性と文脈的類似性のバランスが有益であることを示唆します。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。