[論文レビュー] What matters when building vision-language models?
この論文は vision-language model design choices(アーキテクチャ、バックボーン、データ、トレーニング)の制御されたアブレーションを実施し、推論効率を備えた Idefics2、8B-parameter の VLM を導入して高い性能を達成します。
The growing interest in vision-language models (VLMs) has been driven by improvements in large language models and vision transformers. Despite the abundance of literature on this subject, we observe that critical decisions regarding the design of VLMs are often not justified. We argue that these unsupported decisions impede progress in the field by making it difficult to identify which choices improve model performance. To address this issue, we conduct extensive experiments around pre-trained models, architecture choice, data, and training methods. Our consolidation of findings includes the development of Idefics2, an efficient foundational VLM of 8 billion parameters. Idefics2 achieves state-of-the-art performance within its size category across various multimodal benchmarks, and is often on par with models four times its size. We release the model (base, instructed, and chat) along with the datasets created for its training.
研究の動機と目的
- バックボーンの質(視覚と言語)が、制御された条件下で VLM の性能にどのように影響するかを評価する。
- 完全自 autoregressive 対.Cross-attention 融合アーキテクチャを比較し、パラメータ効率の微調整で安定性を評価する。
提案手法
- アーキテクチャ、バックボーン、データの系統的アブレーションを制御された設定で実施。
- VQAv2、TextVQA、OKVQA、COCO を横断する 6k-step ベンチマークを用いて 4-shot の性能を測定。
- Idefics2(8B パラメータ)を OBELICS、画像-テキスト、PDF データでのマルチステージ事前学習の後、命令調整とチャット風整合を実施して開発・訓練。
実験結果
リサーチクエスチョン
- RQ1固定パラメータ予算で VLM を支える最良の事前学習済み unimodal バックボーンはどれか?
- RQ2バックボーンを訓練/凍結している場合、完全自 autoregressive と cross-attention アーキテクチャはどのように比較されるか?
- RQ3視覚トークンを減らし、アスペクト比を保持しても性能を損なわずに効率を向上させることは可能か?
- RQ4OCR 系タスクを特に要する下流タスクで、訓練時に画像をサブ画像に分割することは計算量を削減しつつ下流性能を向上させるか?
主な発見
| モデル | サイズ | アーキテクチャ | 1 枚あたりのトークン数 | VQAv2 | TextVQA | OKVQA | COCO |
|---|---|---|---|---|---|---|---|
| OpenFlamingo | 9B | CA | - | 54.8 | 29.1 | 41.1 | 96.3 |
| Idefics1 | 9B | CA | - | 56.4 | 27.5 | 47.7 | 97.0 |
| Flamingo | 9B | CA | - | 58.0 | 33.6 | 50.0 | 99.0 |
| MM1 | 7B | FA | 144 | 63.6 | 46.3 | 51.4 | 116.3 |
| Idefics2-base | 8B | FA | 64 | 70.3 | 57.9 | 54.6 | 116.0 |
- パラメータ数を固定した場合、言語モデルのバックボーン品質が視覚バックボーン品質より大きく VLM の性能に影響する。
- バックボーンが訓練可能な場合、学習可能なパラメータ効率の微調整を伴う完全自 autoregressive アーキテクチャは cross-attention よりも優れる可能性がある。一方でバックボーンが凍結されている場合、cross-attention が優位になることがある。
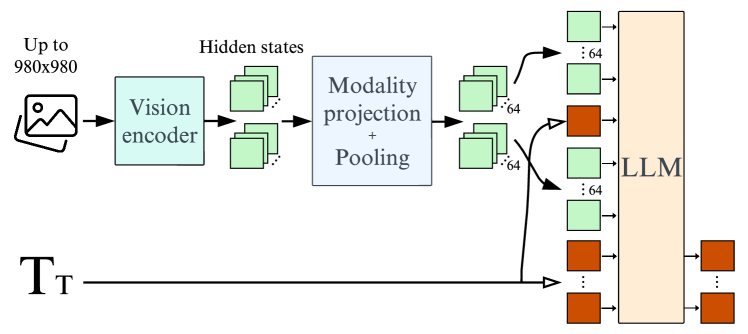
- perceiver-style pooling を用いて視覚トークンを hundreds から 64 へ削減すると、学習と推論の効率が向上し、下流の性能も向上する。
- 視覚エンコーダを適応させつつ、画像のアスペクト比と解像度を保持することで、訓練と推論を高速化しつつ性能を維持する。
- 訓練時に画像をサブ画像に分割することは、特に画像中の文字読取が必要なタスクで下流性能を向上させる。
- Idefics2 はその規模として最先端または競争力のある結果を達成し、より大きなモデルに匹敵することが多く、OCR/読取能力で優れた性能を発揮し、ベース、指示付き、チャット版をオープンにリリース。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。