[論文レビュー] Where are we in the search for an Artificial Visual Cortex for Embodied Intelligence?
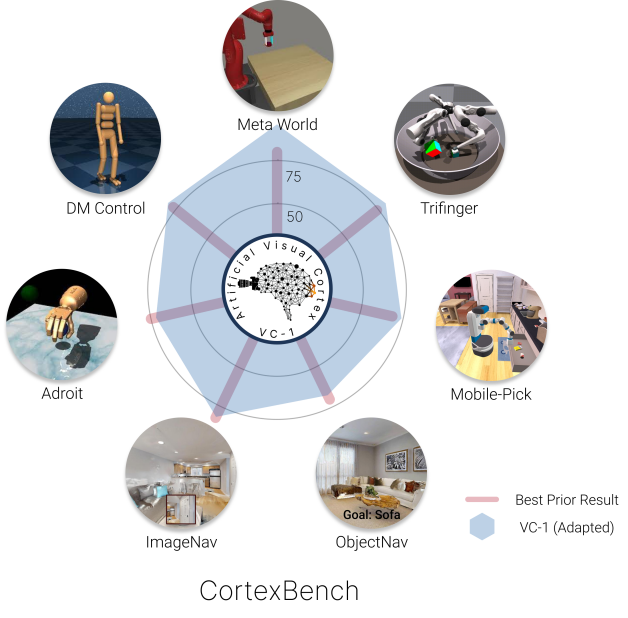
本研究は CortexBench を提示します。Embodied AI の事前学習済み視覚表現の最大規模の評価であり、普遍的な勝者は存在しないことを示しています。VC-1(適応版)は平均的に最も優れており、タスク適応版の VC-1 は CortexBench ベンチマークにおいて最先端の結果に匹敵するかそれを上回ります。
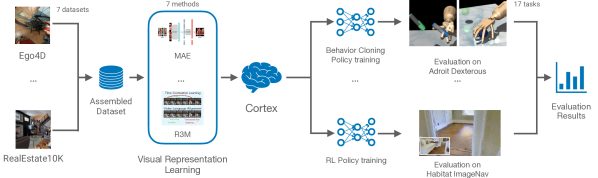
We present the largest and most comprehensive empirical study of pre-trained visual representations (PVRs) or visual 'foundation models' for Embodied AI. First, we curate CortexBench, consisting of 17 different tasks spanning locomotion, navigation, dexterous, and mobile manipulation. Next, we systematically evaluate existing PVRs and find that none are universally dominant. To study the effect of pre-training data size and diversity, we combine over 4,000 hours of egocentric videos from 7 different sources (over 4.3M images) and ImageNet to train different-sized vision transformers using Masked Auto-Encoding (MAE) on slices of this data. Contrary to inferences from prior work, we find that scaling dataset size and diversity does not improve performance universally (but does so on average). Our largest model, named VC-1, outperforms all prior PVRs on average but does not universally dominate either. Next, we show that task- or domain-specific adaptation of VC-1 leads to substantial gains, with VC-1 (adapted) achieving competitive or superior performance than the best known results on all of the benchmarks in CortexBench. Finally, we present real-world hardware experiments, in which VC-1 and VC-1 (adapted) outperform the strongest pre-existing PVR. Overall, this paper presents no new techniques but a rigorous systematic evaluation, a broad set of findings about PVRs (that in some cases, refute those made in narrow domains in prior work), and open-sourced code and models (that required over 10,000 GPU-hours to train) for the benefit of the research community.
研究の動機と目的
- 人工の視覚コルクスの探索を動機づけるため、多様な Embodied AI タスクで事前学習済み視覚表現 (PVR) の広範なセットを評価する。
- Locomotion、navigation、manipulation タスクを含む様々な embodiment に対して PVR をベンチマークする CortexBench を作成する。
- データ規模 / モデル規模がタスク間で普遍的な利益を生むかを assess する。
- 事前学習データと embodied タスク間のドメインギャップを埋める adaptation 戦略を調査する。
- コミュニティのベンチマークを加速するためにデータセット、モデル、コードをオープンソース化する。
提案手法
- Locomotion および manipulation を跨ぐ 7 つの Embodied AI ベンチマークから 17 タスクで CortexBench を構成する。
- 普遍的な性能を評価するため凍結された PVR バックボーン(CLIP、MVP、VIP、R3M)を評価する。
- MAE 事前学習を用いて Ego4D 派生および ImageNet の四つの事前学習データセットで ViT-B/ViT-L バックボーンを訓練する。
- 平均成功率と平均ランクを評価指標として CortexBench での性能を測定する。
- VC-1(すべてのデータで訓練された最大モデル)を既存の PVR と比較して相対的な強さを確立する。
- エンドツーエンドのファインチューニングと MAE ベースの adaptation によってタスク固有の性能を向上させる VC-1 の適応を実演する。
実験結果
リサーチクエスチョン
- RQ1既存の事前学習視覚表現は、幅広い Embodied AI タスクで優位性を持つのだろうか?
- RQ2モデルサイズとデータセットサイズ/多様性を拡張すると CortexBench のタスクでの性能にどう影響するか?
- RQ3強力な PVR のタスク固有の適応は、タスク固有の最先端結果に近づくまたは超えることができるか?
- RQ4エンドツーエンドのファインチューニングと MAE 適応が下流タスクに与える影響はどうか?
主な発見
- どの単一の事前学習視覚表現も CortexBench の全タスクを支配しない。
- 最大モデルの VC-1(Ego4D+MNI で訓練) は平均ランクで最高を達成し、多くのベースラインよりも平均成功率が高いが、すべてのタスクで最良ではない。
- データセットサイズと多様性を拡張すると平均的には性能が向上するが、すべてのタスクで普遍的に改善されるわけではない。
- VC-1 のタスク固有適応(VC-1 adapted)は CortexBench のベンチマークで競争力が高く、先行する最先端を超えることも多い。
- VC-1 および VC-1 adapted は、実機実験のいくつかのタスクで主要な既存 PVR よりも優れている。
- 大規模 IL/RL タスクでのエンドツーエンドのファインチューニングは性能を向上させるが、少数ショットの模倣ドメインでは過剰適合により性能を損なう可能性がある。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。