[論文レビュー] WhisperX: Time-Accurate Speech Transcription of Long-Form Audio
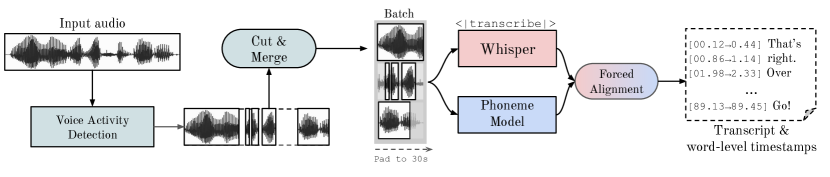
WhisperX は VAD ベースの事前セグメンテーション、Cut & Merge でのチャンク化、並列 Whisper 転写、そして強制的な音素整列を追加し、長時間音声の時間精度の高い語彙レベル転写を大幅に高速化します。
Large-scale, weakly-supervised speech recognition models, such as Whisper, have demonstrated impressive results on speech recognition across domains and languages. However, their application to long audio transcription via buffered or sliding window approaches is prone to drifting, hallucination & repetition; and prohibits batched transcription due to their sequential nature. Further, timestamps corresponding each utterance are prone to inaccuracies and word-level timestamps are not available out-of-the-box. To overcome these challenges, we present WhisperX, a time-accurate speech recognition system with word-level timestamps utilising voice activity detection and forced phoneme alignment. In doing so, we demonstrate state-of-the-art performance on long-form transcription and word segmentation benchmarks. Additionally, we show that pre-segmenting audio with our proposed VAD Cut & Merge strategy improves transcription quality and enables a twelve-fold transcription speedup via batched inference.
研究の動機と目的
- 長時間スピーチの語彙レベルの正確なタイムスタンプという課題に対処する。
- 長時間のオーディオの転写スループットをバッチ処理・並列処理で改善する。
- Whisper と外部音素モデルを組み合わせて信頼性のある語彙レベルの整列を提供する。
- VAD ベースの事前セグメンテーションが転写品質と速度に及ぼす利点を示す。
提案手法
- Voice Activity Detection (VAD) モデルを用いて音声領域を特定し、音声を事前セグメント化する。
- ASR モデルと互換性のあるセグメント長の上限を課すために、最小カット(min-cut)操作を適用する(約30秒)。
- 周辺の短いセグメントを結合し、文脈の豊富さとトレーニング時代のセグメント長に近づける。
- 前のテキストに条件付けず、Whisper を用いて VAD 主導のセグメントを並列に転写する。
- 各転写セグメントに対して音素認識器とダイナミックタイムワーピング(DTW)を用いた強制音素整列を実行し、語彙レベルのタイムスタンプを生成する。
実験結果
リサーチクエスチョン
- RQ1WhisperX は長時間の転写と語彙レベルのセグメンテーションにおいて、最先端の ASR モデル(Whisper と wav2vec2.0)と比較してどうパフォーマンスを発揮するか。
- RQ2VAD Cut & Merge の前処理が転写品質とスループットに与える影響は。
- RQ3異なる Whisper モデルと音素モデルがデータセット全体で語彙セグメンテーション性能にどのように影響するか。
- RQ4外部の音素整列は、推論オーバーヘッドを最小限に抑えつつ、信頼性のある語彙レベルタイムスタンプを提供できるか。
主な発見
- WhisperX は標準ベンチマークで Whisper および wav2vec2.0 に比べ、語彙セグメンテーション、WSR、転写速度を大幅に改善している。
- VAD Cut & Merge によるバッチ転写は、品質を損なうことなく約12倍の速度向上を実現する。
- 強制音素整列は、Whisper のタイムスタンプのみに依存する場合と比較して、オーバーヘッドを最小限に抑えつつ語彙レベルのタイムスタンプを正確に得られ、幻覚や繰り返しを減らす。
- より大きい Whisper モデルはセグメンテーション指標を改善し、音素モデルの選択(例:VoxPopuli 対 LibriSpeech ベース)はAMI/SWB のパフォーマンスに大きな影響を与え得る。一方 LibriSpeech ベースの整列は依然として強力なデフォルトである。
- VAD ベースのチャンク化は境界効果を低減し、Whisper 派生のタイムスタンプへの過度な依存を避け、長時間転写を堅牢にする。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。