[論文レビュー] Why think step by step? Reasoning emerges from the locality of experience
本論文は、トレース思考(chain-of-thought)推論が、訓練データに局所的な構造がある場合に言語モデルの性能を高め、局所的な依存関係を連鎖させることで推論を効率化することを示している。一方、データが完全に観測されている場合や非局所的な場合には、推論はほとんど利点をもたらさない。
Humans have a powerful and mysterious capacity to reason. Working through a set of mental steps enables us to make inferences we would not be capable of making directly even though we get no additional data from the world. Similarly, when large language models generate intermediate steps (a chain of thought) before answering a question, they often produce better answers than they would directly. We investigate why and how chain-of-thought reasoning is useful in language models, testing the hypothesis that reasoning is effective when training data consists of overlapping local clusters of variables that influence each other strongly. These training conditions enable the chaining of accurate local inferences to estimate relationships between variables that were not seen together in training. We prove that there will exist a "reasoning gap", where reasoning through intermediate variables reduces bias, for the simple case of an autoregressive density estimator trained on local samples from a chain-structured probabilistic model. We then test our hypothesis experimentally in more complex models, training an autoregressive language model on samples from Bayes nets but only including a subset of variables in each sample. We test language models' ability to match conditional probabilities with and without intermediate reasoning steps, finding that intermediate steps are only helpful when the training data is locally structured with respect to dependencies between variables. The combination of locally structured observations and reasoning is much more data-efficient than training on all variables. Our results illustrate how the effectiveness of reasoning step by step is rooted in the local statistical structure of the training data.
研究の動機と目的
- 中間変数を介した推論が言語モデルの推論を改良し得る理由を動機づけ、形式化する。
- 局所構造を持つ観測に対する条件推論のためのベイズネットベースの枠組みを形式化する。
- 連鎖構造モデルにおける推論の理論的バイアス低減ギャップを証明する。
- 合成ベイズネットで訓練された自己回帰トランスフォーマーを用いて、中間推論がいつ有用かを経験的に検証する。
提案手法
- 変数の局所領域を作り出す観測分布を形式化する。
- 条件付き確率のための直接予測、スキャフォールド生成、自由生成の3つの推定量を導出する。
- 連鎖構造において中間変数を介した推論が隣接していない変数ペアのバイアスを低減する「推論ギャップ」を証明する。
- 局所構造を持つ合成ベイズネットデータで自己回帰型トランスフォーマーを訓練し、保持アウトのペアに対する条件付き確率を評価する。
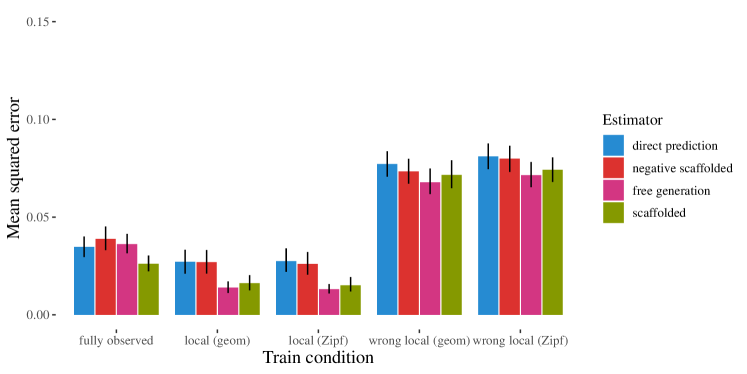
- 局所的に構造化された設定、完全に観測されたデータ設定、誤指定の局地性設定の間で、平均二乗誤差(MSE)を用いて推定量を比較する。
- データ効率と、推論が不要または有害となる状況を分析する。
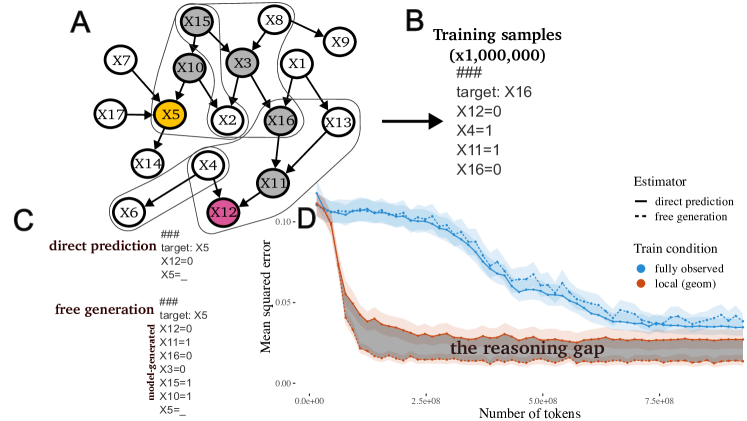
実験結果
リサーチクエスチョン
- RQ1どのような訓練データの局所性条件の下で、中間推論ステップが条件推論のバイアスを低減するか?
- RQ2局所構造の下で、自己生成された中間推論は自己回帰モデルが真の条件付き確率に直接予測よりも一致するのに役立つか?
- RQ3完全に観測されたデータでの学習と比べて、推論ベースの推論はどれだけデータ効率が高いか?
- RQ4推論が役に立たないまたは性能を損なうのはいつか?
- RQ5どの要因(例:局所性の強さ、変数間の距離)はチェイン・オブ・ソウト推論の有用性を調整するのか?
主な発見
- 訓練データに強い局所構造がある場合、中間変数を介した推論は非隣接する変数ペアのバイアスを低減する。
- 局所的に構造化された訓練データの下で、自由生成とスキャフォールド生成の両方が直接予測を上回る。
- データが完全に観測されている場合や局所性構造が不正確な場合、推論はほとんど利点をもたらさない。
- 局所的に構造化されたデータとチェーン・オブ・ソウト推論を組み合わせるとデータ効率が高まり、より少ない訓練量でほぼ真の条件付き確率を達成する。
- 観測変数が頻繁に同時出現する場合、直接予測が真の確率にすでに一致することがあり、推論の必要性が小さくなる。
- 推論チェーンの再サンプリング(複数のモンテカルロサンプル)は推定分散の低減に役立つ。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。