[論文レビュー] Why Warmup the Learning Rate? Underlying Mechanisms and Improvements
この論文は、学習率ウォームアップの主な利点は、オプティマイザをより良く条件付けられた領域へ押し込むことによって、より大きなターゲット学習率を可能にすることだと示している。SGDとAdamを分析し、レジームを特定し、ウォームアップを減らすまたは排除する初期化戦略を提案する。
It is common in deep learning to warm up the learning rate $η$, often by a linear schedule between $η_{ ext{init}} = 0$ and a predetermined target $η_{ ext{trgt}}$. In this paper, we show through systematic experiments using SGD and Adam that the overwhelming benefit of warmup arises from allowing the network to tolerate larger $η_{ ext{trgt}}$ {by forcing the network to more well-conditioned areas of the loss landscape}. The ability to handle larger $η_{ ext{trgt}}$ makes hyperparameter tuning more robust while improving the final performance. We uncover different regimes of operation during the warmup period, depending on whether training starts off in a progressive sharpening or sharpness reduction phase, which in turn depends on the initialization and parameterization. Using these insights, we show how $η_{ ext{init}}$ can be properly chosen by utilizing the loss catapult mechanism, which saves on the number of warmup steps, in some cases completely eliminating the need for warmup. We also suggest an initialization for the variance in Adam which provides benefits similar to warmup.
研究の動機と目的
- 学習率ウォームアップがアーキテクチャ、初期化、最適化アルゴリズムを跨いでなぜ訓練を助けるかを調査する。
- ウォームアップのダイナミクスと損失表面のシャープさの相互作用を特徴づける。
- ウォームアップがより大きなターゲット学習率の使用能力と一般化にどのように影響するかを定量化する。
- ウォームアップの必要性を減らすまたは排除する初期化戦略を提案する。
- 事前条件付きシャープネスを低減するためのAdamの実用的な初期化法を提供する。
提案手法
- CIFAR-10/100、TinyImageNet、WikiText-2 に関して、FCN、ResNet、Transformerを横断した系統的実証研究。
- 線形ウォームアップとさまざまなパラメータ化(SP、μP)を用いた SGD、モーメント付き SGD、および Adam の分析。
- 安定性閾値を評価するためのシャープネス(λ^H)と事前条件付きシャープネス(λ^{P^{-1}H})の定義と利用。
- トレーニングの不安定性とウォームアップ効果を説明するカタパルト/自己安定化フレームワーク。
- 二次モーメント g0^2 の初期化としての GI-Adam の導入、事前条件付きシャープネスを低減。
- η_init の探索法を提案し、順伝播を用いた η_c の推定とバイナリ/指数探索を行う。
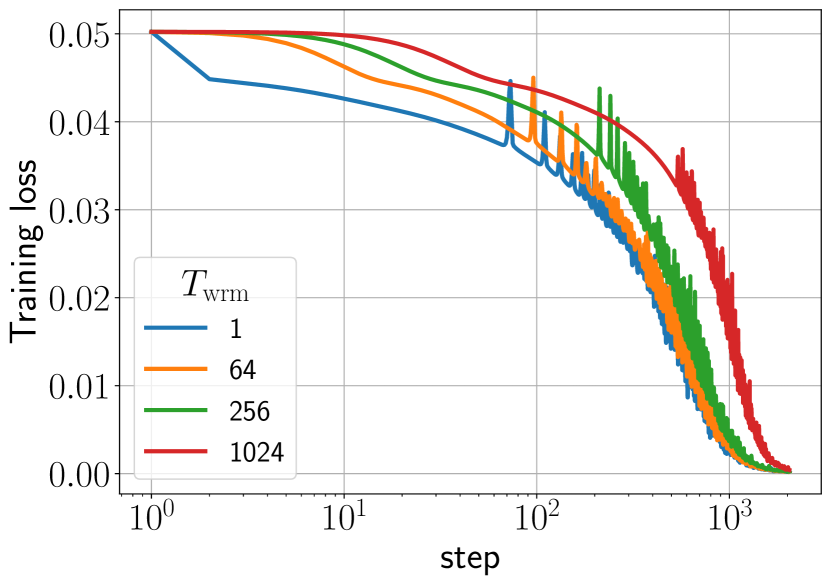
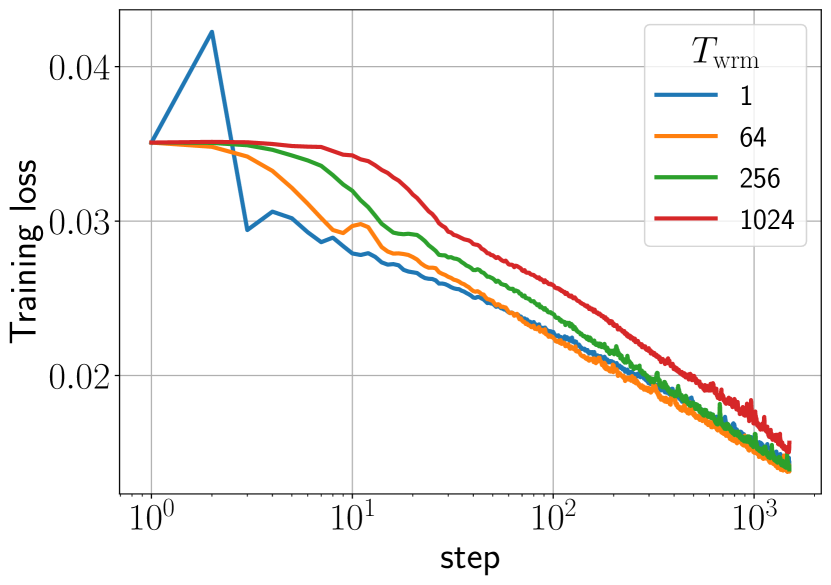
実験結果
リサーチクエスチョン
- RQ1学習率ウォームアップが訓練性能を改善する主な機構は何か?
- RQ2SGD、モーメント付きSGD、Adamにおけるウォームアップのダイナミクスがシャープネスの進化とどう相互作用するか?
- RQ3損失ランドスケープの平坦な領域へ移動することで、ウォームアップはより大きなターゲット学習率を許容できるか?
- RQ4初期化とパラメータ化(SP vs μP)がウォームアップのレジームと有効性にどう影響するか?
- RQ5 principled initialization strategies(例:GI-Adam、η_init ≈ η_c)によってウォームアップを減らすまたは排除できるか?
主な発見
- ウォームアップは主に、より良く条件付けられた損失領域へ移動することによって、ネットワークが増大した η_trgt を耐えられるようにすることで、より大きなターゲット学習率を可能にする。
- 観察された2つの主なレジーム:自然な段階的なシャープネスの鋭化と自然なシャープネスの低減、これらがウォームアップと損失ランドスケープの相互作用を決定する。
- Adam における主要な不安定性は事前条件付きシャープネスに結びついている;ウォームアップは λ^{P^{-1}H} を低減することで大きなカタパルトを緩和する。
- GI-Adam は勾配の二乗で二次モーメントを初期化することにより初期の事前条件付きシャープネスを低減し、ウォームアップと同様に安定性を改善する。
- η_init の選択法で順伝播を用いて η_c を推定する方法は、ウォームアップ時間を大幅に短縮するか、場合によっては排除できる。
- 長いウォームアップは一般に不安定性閾値を遅らせ、カタパルトを平滑化することで、より大きな η_trgt を許容し、堅牢性と一般化を改善する。
- 最終的な性能は主に η_trgt によって決まり、ウォームアップの期間は堅牢性と使用可能な学習率の範囲を微調整する。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。