[論文レビュー] xCodeEval: A Large Scale Multilingual Multitask Benchmark for Code Understanding, Generation, Translation and Retrieval
xCodeEval は、コードのための最大規模の実行可能な多言語マルチタスクベンチマークで、7.5K 問題と 17 言語、7 つのタスク、実行ベースの評価エンジン ExecEval を備えています。LLM のコード理解、生成、翻訳、検索を、言語横断・タスク横断・実行レベルで評価することを可能にします。
Recently, pre-trained large language models (LLMs) have shown impressive abilities in generating codes from natural language descriptions, repairing buggy codes, translating codes between languages, and retrieving relevant code segments. However, the evaluation of these models has often been performed in a scattered way on only one or two specific tasks, in a few languages, at a partial granularity (e.g., function) level, and in many cases without proper training data. Even more concerning is that in most cases the evaluation of generated codes has been done in terms of mere lexical overlap with a reference code rather than actual execution. We introduce xCodeEval, the largest executable multilingual multitask benchmark to date consisting of $25$M document-level coding examples ($16.5$B tokens) from about $7.5$K unique problems covering up to $11$ programming languages with execution-level parallelism. It features a total of $7$ tasks involving code understanding, generation, translation and retrieval. xCodeEval adopts an execution-based evaluation and offers a multilingual code execution engine, ExecEval that supports unit test based execution in all the $11$ languages. To address the challenge of balancing the distributions of text-code samples over multiple attributes in validation/test sets, we propose a novel data splitting and a data selection schema based on the geometric mean and graph-theoretic principle. Our experiments with OpenAI's LLMs (zero-shot) and open-LLMs (zero-shot and fine-tuned) on the tasks and languages demonstrate **xCodeEval** to be quite challenging as per the current advancements in language models.
研究の動機と目的
- 実行ベースのフレームワークを用いて、多言語プログラムの理解、生成、翻訳、検索を評価する。
- 複数のプログラミング言語と問題難易度をカバーする、大規模で多様なベンチマークを提供する。
- 言語横断で単体テストを実行する実行エンジンと新しいデータ分割戦略によって、公平な評価を実現する。
提案手法
- 最大17言語で7.5Kの問題を含む、Codeforces からの2500万サンプルのデータセットを構築する。
- 実行テストベースの評価のため、11言語で44のコンパイラ/インタプリタをサポートする安全な分散実行エンジン ExecEval を開発する。
- 実行ベースの評価を伴う7つのタスクを定義する(2つの分類、3つの生成、2つの検索)。
- 幾何平均と循環問題に基づく新規のデータ分割とサンプリング戦略を用いて、問題とタグ間で検証/テストの分布をバランスさせる。
- このベンチマークで OpenAI およびオープン LLM を評価し、現在の能力とギャップを把握する。
- トレーニングデータと評価リソース(データセット、GitHub/Hub、ドキュメント)を提供する。
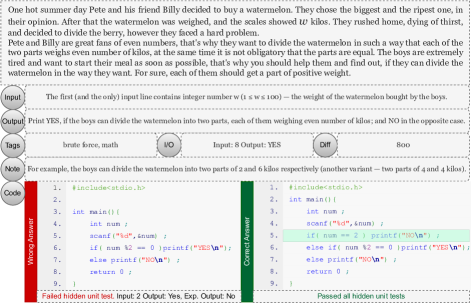
実験結果
リサーチクエスチョン
- RQ1実行ベースの単体テストで評価したとき、マルチリンガル LLM はコード理解、生成、翻訳、検索でどのように性能を示すか?
- RQ217言語にわたる実行可能コードタスクの、言語横断転移とゼロショット能力はどのようなものか?
- RQ3異なる問題難易度と言語リソースは、プログラム合成、修正、翻訳の性能にどう影響するか?
- RQ4提案されたデータ分割とサンプリング戦略は、複数の属性にわたってバランスの取れた代表的な検証/テストセットを生み出すか?
- RQ5現在の LLM における、言語を跨ぐ実行可能コードの熟練度と推論に関する洞察は何か?
主な発見
- xCodeEval は、タスクと言語に跨るゼロショットおよびファインチューニング済みモデルを含む、最新の LLM にとって挑戦的です。
- タグ分類は概ね良好な全体性能を示し、問題説明が含まれると改善します;ウェブ言語は性能が低い。
- コードコンパイルは Go, PHP, Python, Ruby, C# に対して強力だが、Java, Kotlin, Rust ではほぼランダムに近い。
- プログラム合成は一部言語で higher pass@k を達成するが、Rust やその他のリソースが少ない言語では遅れ、APR は一部言語で相対的に高い性能を示す。
- コード翻訳は Kotlin と Go が多くのターゲットへ良く翻訳されることを示し、C++ と Python は強力なターゲットである。一方、言語ペアごとに横断翻訳性能は大きく異なる。
- StarEncoder を用いた Code-Code および NL-Code 取得は言語リソース依存の結果を示し、全体として NL-Code の性能が良い。より大きなコーパスと言語リソースの不均衡は Code-Code 取得に影響を与える。
- 小型モデル(Starcoderbase-3B、CodeLlama 変種)での実験はデータ有効性を示し、より小さなファインチューニング済みモデルが xCodeEval データの恩恵を受けられる一方、多くのケースで大規模指示型モデルは小型モデルを上回り続ける。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。