[論文レビュー] XLNet: Generalized Autoregressive Pretraining for Language Understanding
XLNetは、双方向コンテキストを捉えるための二ストリーム注意機構を備えた、順列ベースの自己回帰事前学習を導入し、事前学習と微調整のずれなしに、さまざまなNLPタスクでBERTとRoBERTaを上回る。
With the capability of modeling bidirectional contexts, denoising autoencoding based pretraining like BERT achieves better performance than pretraining approaches based on autoregressive language modeling. However, relying on corrupting the input with masks, BERT neglects dependency between the masked positions and suffers from a pretrain-finetune discrepancy. In light of these pros and cons, we propose XLNet, a generalized autoregressive pretraining method that (1) enables learning bidirectional contexts by maximizing the expected likelihood over all permutations of the factorization order and (2) overcomes the limitations of BERT thanks to its autoregressive formulation. Furthermore, XLNet integrates ideas from Transformer-XL, the state-of-the-art autoregressive model, into pretraining. Empirically, under comparable experiment settings, XLNet outperforms BERT on 20 tasks, often by a large margin, including question answering, natural language inference, sentiment analysis, and document ranking.
研究の動機と目的
- 双方向言語理解のための自己回帰型と自己符号化型の事前学習方式(ARとAE)の限界を動機付け、対処する。
- ARの利点と双方向の文脈を組み合わせる統一的な事前学習目的を提案する。
- 長い文脈を扱い訓練効率を向上させるためにTransformer-XLの特徴を組み込む。
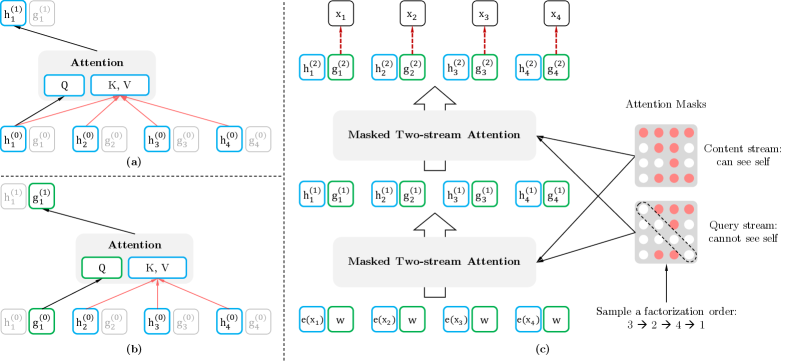
- 順列ベースの事前学習に適合するターゲット認識型の二ストリーム注意機構を開発する。
提案手法
- permutation言語モデリングを定義する:シーケンスの全ての因子化順序に対して期待対数尤度を最大化する。
- 内容ストリームとターゲット認識クエリストリームを備えた二ストリーム自己注意を導入し、ターゲット特有の予測を生成する。
- 特定の順列内でトークンの一部を予測して最適化を容易にする部分的予測目的を計算する。
- 長い文脈をモデル化するためにTransformer-XL風の相対セグメントエンコーディングと再帰を組み込む。
- メモリを備えた複数セグメントをモデル化し、より長い入力やQ&A、文書ランキングなどのタスクに対応する。
- シーケンス長512で大規模な多言語英語コーパス上で訓練し、BERT系ベースラインと公正に比較する。
実験結果
リサーチクエスチョン
- RQ1順列ベースの自己回帰事前学習は双方向の文脈を効果的に学習できるか。
- RQ2入力の破損を除去する(マスキングなし)ことで pretrain-finetune のずれを回避しつつ性能を保てるか。
- RQ3Transformer-XLの要素(相対エンコーディングと再帰)はXLNetの長い文脈の取り扱いを改善するか。
- RQ4順列因子分解下でターゲット認識型トークン予測に二ストリーム注意機構は必須か。
主な発見
- XLNetはGLUE、SQuAD、RACE、文書ランキングを含む広範なタスクで、同等の設定の下でBERTを上回る。
- 長い文脈を要するタスク(例:SQuAD、RACE)で特に性能向上が顕著。
- アブレーション実験では、Transformer-XLと順列言語モデリングの両方がBERTを上回る向上に寄与;メモリ、スパンベース予測、双方向データパイプラインも結果を改善。
- BERTのNext Sentence Prediction目的はXLNetに一貫して寄与せず、XLNetのバリアントでは使用されていない。
- XLNetはRoBERTaに対して競争力のある、または優れた結果を複数の読解問題とGLUEベンチマークで達成。
より良い研究を、今すぐ始めましょう
論文設計から論文執筆まで、研究時間を劇的に削減しましょう。
クレジットカード登録不要
このレビューはAIが作成し、人間の編集者が確認しました。